1- INTRODUÇÃO
1.1ORIGEM E CRESCIMENTO DA WEB
A WEB é o universo de informações acessíveis por meio de computadores ligados em
rede, ou seja, é uma aplicação em rede que permite aos usuários o acesso a serviços
vários tais como mensagem de correio eletrônico, compra e venda, leilões, transmissão
de áudio e imagens, etc. Um dos grandes passos da Internet foi criação do hipertexto. O
hipertexto é uma escrita não-sequencial que apresenta informações como uma coleção
de nós interligados, sendo que cada nó pode estar localizado em pontos diferentes,
tendo como única relação a afinidade das informações que contém. Pode-se dizer que a
WEB surgiu da ARPANET, uma rede concebida em 1960 como uma infra-estrutura de
comunicação para compartilhar o acesso a supercomputadores entre os pesquisadores
no Estados Unidos. Havia também o interesse do Departamento de Defesa dos Estados
Unidos em estudar técnicas que possibilitassem as comunicações entre computadores
de diferentes fabricantes. Com isto surgiu o conjunto de protocolos TCP/IP que foi formalizado em 1980. Influenciado pelo hipertexto, um cientista propôs o vínculo das informações contidas em diversas máquinas. Nesta época vários outros sistemas foram
criados para pesquisa e acesso de documentos pela Internet, como por exemplo: FTP,
Gopher, Archie e WAIS (Wide Area Information Servers). O FTP (File Transfer Protocol)
permite que usuários copiem arquivos previamente colocados em servidores específicos; o Gopher permitia que usuários procurassem informações nas redes de computadores, com base em palavras-chave ou assuntos; o WAIS retornava uma lista de
arquivos, classificados por sua relevância em relação à consulta realizada; o Archie foi
introduzido como uma ferramenta para localizar arquivos em servidores FTP. Por algum
tempo estes sistemas competiram com a WEB antes de serem abrangidos pela própria
WWW, sendo que o único que permanece é o FTP para transferência de arquivos. Os
demais serviços ficaram obsoletos em função de seus protocolos mais primitivos e
também pelo advento do hipertexto, o qual se mostrou muito mais flexível.
1.2COMPONENTES SEMÂNTICOS DA WEB
São três os componentes semânticos da WEB: Uniform Resource Identifiers (URI),
Hypertext Markup Language (HTML) e Hypertext Transfer Protocol.
1.2.1URI (Uniform Resource Identifiers)
O URI é o identificador do recurso distribuído colocado na WEB. O URI não representa
algo físico e sim um ponteiro para métodos de pedidos. Um método de pedido é uma
operação simples como busca, troca ou exclusão de um recurso. No nível mais alto um
URI é um string formatada como http://www.site.com.br/algo.gif e consiste de três
partes: o protocolo para comunicação (no caso http), o nome do servidor (www) e o
nome do recurso no servidor (algo.gif). O formato mais popular do URI é o URL
(Uniform Resource Locator) e normalmente são confundidos apesar de não serem a
mesma coisa. De uma forma geral será utilizado o termo mais corrente ao longo deste
trabalho que é URL.
1.2.2Hypertext Markup Language (HTML)
A HTML oferece uma representação padrão para documentos de hypertexto em formato ASCII, permitindo que os autores formatem texto, façam referência a imagens e
incluam links de hypertexto para outros documentos. Os arquivos HTML são lidos e
interpretados pelos browsers antes de serem apresentados aos usuários.
1.2.3Hypertext Transfer Protocol(HTTP)
O HTTP é o protocolo que permite as comunicações entre os componentes da WEB,
definindo o formato e o significado das mensagens trocadas pelos componentes e é um
protocolo do tipo cliente-servidor, ou seja, o cliente faz uma solicitação e recebe do
servidor uma mensagem como resposta. Os pedidos dos clientes normalmente são disparados com um click em um hypertexto ou pela digitação de uma URL na janela do
browser. Também tem como característica o fato de ser um protocolo sem estado, ou
seja, as mensagens entre cliente e servidor são tratadas independentemente e não
precisam manter qualquer informação de estado entre pedidos e respostas.
1.3CONCEITOS
1.3.1Componentes de Software
Agente de usuário: é o componente que inicia o pedido HTTP e trata a resposta.
O
exemplo mais comum é o browser;
Cliente: programa que envia um pedido HTTP;
Servidor da web: o programa que recebe um pedido HTTP de um cliente e
transmite a resposta;
Proxy: intermediário entre o cliente e o servidor;
Cookie: informações de estado passadas entre o agente do usuário e o servidor
1.3.2 Rede de suporte
Host: qualquer dispositivo computacional componente da rede, podendo ser o
computador do usuário, um servidor da web, um gateway, etc. ;
Pacote: unidade básica de informação dentro da rede;
IP: protocolo da pilha de protocolos TCP/IP responsável pelo encaminhamento dos
pacotes entre clientes e servidores;
Endereçamento IP:forma de identificação inequívoca de um host na rede,
composto
de 32 bits;
Nome do host: nome que identifica um host na rede;
DNS: Domain Name System. Trata-se de um banco de dados distribuído com a
finalidade de traduzir nomes de servidores para endereços IP;
TCP: Transmission Control Protocol, protocolo da pilha de protocolos TCP/IP, com
a função de fornecer uma conexão confiável e bidirecional entre dois hosts;
UDP: User Datagram Protocol, protocolo da pilha de protocolos TCP/IP com a
função de fornecer conexões não confiáveis entre dois hosts, utilizado para
mensagens curtas (p. ex. troca de mensagens com o DNS);
Conexão: canal de comunicação lógico estabelecido entre dois hosts
1.3.3Padronização
A Internet não possui um órgão administrativo; os vários hosts e redes aderem aos padrões de protocolo voluntariamente. A Internet Enginnerng Task Force (IETF) é uma
comunidade aberta de projetistas de redes, fornecedores de produtos e pesquisadores
que contribuem para a evolução e a operação da Internet. A IETF governa os padrões
por uma série de publicações oficiais chamadas RFC (Request For Comments), sendo
que a primeira foi publicada em 1969. Os documentos da Internet começam como
Rascunhos da Internet, que são documentos informais que sofrem revisão com base
nos comentários da comunidade. Nem todos os Rascunhos da Internet se tornam RFCs.
Os documentos de padrões possuem requisitos de compatibilidade de diferentes
níveis: PRECISA (must), DEVE (should) e PODE (may). Qualquer implementação pode
ser considerada condicionalmente compatível se atender a todos os requisitos PRECISA
e uma implementação pode ser considerada condicionalmente compatível se atender
a todos os requisitos do nível DEVE. Os requisitos de nível PODE são opcionais. Estes
níveis de requisito ajudam a assegurar a interoperabilidade entre diferentes
implementações. A fim de nutrir e promover o crescimento da web, foi fundado o
World Wide Web Consortium (W3C), em 1994. Este consórcio desenvolveu uma série
de padrões relacionados à web, enfocando assuntos arquitetônicos, assuntos de
interface com o usuário que lidam com formatos e idiomas, assuntos sociais relativos a
questões de política legal e pública e assuntos de acessibilidade para assegurar que
pessoas com deficiências possam ter acesso à tecnologia.
1.3.4Tráfego e desempenho da WEB.
A popularidade da web trouxe um problema para os projetistas de redes, tendo em
vista o aumento do tráfego na Internet e as expectativas do usuário em relação à rapidez no atendimento às suas solicitações. A terminologia relacionada ao tráfego na
Internet é a seguinte:
- Latência (ou demora): tempo entre a iniciação de uma ação, como o envio de uma
mensagem de pedido e a primeira indicação de uma resposta;
- Latência percebida pelo usuário: demora entre o momento em que o usuário seleciona um hipertexto e o conteúdo começa a aparecer na tela. Cada componente de
software e protocolo contribui de forma variada para a latência percebida pelo
usuário. Por exemplo, o browser precisa montar o pedido HTTP, determinar o
endereço IP do servidor, estabelecer uma conexão TCP com o servidor, transmitir o
pedido, esperar pela resposta e finalmente, apresentar a resposta ao usuário. Um
pedido de latência alto pode ter várias origens: sobrecarga no DNS, congestionamento
da rede ou sobrecarga no servidor. A conexão do usuário com a Internet também é
responsável pela latência percebida pelo usuário. Neste particular, vários serviços
denominados de maneira geral como acesso de banda larga tem sido oferecidos, tais
como: ADSL, DVI, acesso por cabo e acesso por satélites. A largura de banda destes
serviços variam até algo em torno de velocidades de rede local, mas a maioria fica na
casa de 200 a 500 Kbps, o que vem a ser um grande avanço em relação aos modems
convencionais que ficam na casa de 56 Kbps, além do que a transmissão é totalmente
digital. A maioria da análise de tráfego da web é baseada em logs que registram as
transferências HTTP realizada por componentes de software da web. A análise de logs
é útil para se entender as características da carga de trabalho tratada pelos
componentes de software da web. Uma carga de trabalho consiste no conjunto de
todas as entradas (por exemplo, pedidos HTTP) recebidas por um componente com o
passar do tempo. As características da carga de trabalho, como o tempo entre os
pedidos e o tamanho e popularidade dos vários recursos, possuem implicações
importantes para o desempenho dos protocolos da web, componentes de software e a
rede que os suporta.
1.35 Aplicações WEB
O crescimento da web ocasionou uma pesada carga sobre os servidores da web e na
Internet e conseqüentemente aumentou a latência percebida pelo usuário no acesso ao
conteúdo da web. O caching aproxima o conteúdo do usuário, que pode estar localizado
no lado do usuário (no browser) ou em algum equipamento intermediário (proxy). Embora melhore o acesso do usuário, uma resposta em cache pode diferir da versão disponível do servidor, sendo necessário então o uso de mecanismos de coerência de cache
que são usados para assegurar que uma mensagem em cache esteja atualizada com o
servidor de origem. Estes mecanismos de coerência de cache podem incluir alguma consulta ao servidor de origem para comparar a última atualização com o que está armazenado. Uma alternativa para o caching, a replicação, envolve a duplicação explícita do
conteúdo da web em diversos servidores. Uma alternativa para a replicação de
conteúdo completo de um site da web é a entrega de conteúdo seletivamente a partir
das réplicas em nome do servidor principal. Esta técnica é conhecida como distribuição
de conteúdo.
A web oferece acesso a diversos recursos sem levar em conta seu formato. Áudio e
vídeo se tornaram comuns na web. Diferentemente do conteúdo tradicional, fluxos de
áudio ou vídeo consistem em um seqüência de sons (amostras) ou imagens (quadros)
durante um período de tempo. Em aplicações de streaming de multimídia o cliente toca
as amostras ou quadro assim que eles chegam do servidor, em vez de baixar todo o
conteúdo antes de começar a reprodução. Essas aplicações consomem grande largura
de banda e são sensíveis a demoras no recebimento das amostras de áudio e quadros de
vídeo. Embora o HTTP possa ser usado para entregar conteúdo de multimídia, a maioria
das transferências de multimídia é simplesmente iniciada via HTTP. Depois de iniciada,
uma aplicação de auxílio, ou media player, contata o servidor de multimídia usando um
conjunto de protocolos mais adequados para o streaming de áudio e vídeo.
2- CLIENTES DA WEB
No item anterior foi apresentado que os três componentes de software principais da web
são: cliente, proxy e o servidor. A maioria dos usuários da web entra em contato direto com
clientes da web e quase nunca com proxy ou servidores. Os servidores são fundamentais, os
proxies desempenham um papel de alta relevância, porém o browser- a forma mais conhecida de um cliente da web- é o que é realmente visto pelos usuários finais como a interface
da web.
2.1 Funções do browser relacionadas à WEB.
Um cliente da web é um pedaço de software. A tarefa típica de um cliente da web é enviar um pedido da web em favor de um usuário e receber a resposta. Na prática os clientes web são muito complexos. A complexidade não vem de uma das tarefas fundamentais que um cliente da web precisa realizar: construir um pedido web corretamente for-
matado, estabelecer uma conexão e comunicar-se com um servidor web por uma
conexão confiável em nível de transporte. Muitas das complexidades de um programa
cliente vêm de fatores ambientais ao redor da troca básica entre pedido e resposta,
personalizar a criação do pedido, interpretar a resposta e moldar a apresentação. Um
browser implementa principalmente um cliente web, constrói e envia um pedido HTTP,
depois recebe, analisa e apresenta a resposta. Uma sessão do browser é, portanto, uma
série de pedidos enviados pelo usuário, possivelmente baseados nas respostas recebidas
a cada estágio. Uma sessão de browser pode durar alguns minutos ou um tempo muito
longo. A figura abaixo mostra as várias etapas no processo envolvido em um pedido da
web, conforme processado por um browser típico.
Browser
1
Servidor DNS
Servidor
Conexão TCP
Pedido HTTP
Resposta HTTP
Algumas etapas podem não ser necessárias para cada pedido, devido ao caching.
Existem dois tipos de caching que são comuns nos browsers: uma parte de memória do
processo em execução e uma parte do espaço em disco do sistema de arquivos que é
dedicada ao caching. É possível que o recurso em cache possa ter sido modificado desde
o momento em que ele foi guardado no cache. O browser pode ter que verificar se a
resposta em cache ainda está atualizada., comparando esta cópia com a cópia atual no
servidor. Essa verificação é chamada de revalidação do cache. Se a versão no servidor for
mais recente, então a cópia no cache está desatualizada. Diz-se que um cache mantém
coerência dos recursos em cache, se ele garantir que os recursos em cache ainda estão
atualizados no servidor de origem. Se o cache revalida sua versão contra o servidor toda
vez que é feito um pedido de um recurso, diz-se que tem uma forte coerência de cache.
Se o cache utiliza uma heurística para decidir se os dados estão atualizados ou não, diz-se
que tem uma fraca coerência de cache. Diversas heurísticas são usadas para se manter a
coerência do cache, por exemplo: intervalos fixos de tempo ou variar o intervalo de
revalidação de acordo com os atributos do recurso (tamanho, última vez que foi
modificado, etc).
TESTE
TESTE
TESTE
TESTE
2.2COOKIES
O HTTP é um protocolo sem estado - um servidor da web não precisa reter nenhuma
informação sobre pedidos passados ou futuros. No entanto um servidor pode ter um
motivo para querer manter informações (estado) entre uma série de pedidos dentro
de
uma sessão de navegação pela web ou ainda entre as sessões. Por exemplo,
um servidor
pode ter que dar um determinado tipo de acesso diferenciado para
algum usuário e se
for necessária alguma informação de identificação toda vez que
o usuário acessa qualquer uma das páginas neste conjunto, haverá um trabalho extra
considerável para o
usuário incluir tais informações e o servidor processá-las. Um
browser desempenha um papel importante no fornecimento de informações, exigido
no pedido de um
usuário. Os cookies são um meio de se administrar o estado em
HTTP, ou seja, a colocação de informações para manipulação pelos servidores e são
armazenados no
host do cliente em favor do servidor. De uma certa forma os
cookies são muito
discutidos dentro da comunidade web, tendo em vista a
opinião de alguns autores que consideram uma invasão na privacidade dos usuários. O
cookie é enviado pelo servidor, junto com a resposta e armazenado no host cliente.
Da próxima vez que o usuário visitar o site, as informações contidas no cookie são
passadas para o servidor, dentro do cabeçalho do pedido. Como alternativa, as
informações passadas no cookie podem permitir ao servidor acompanhar um conjunto
de usuários de uma organização.A figura abaixo mostra um cliente enviando um pedido
a um servidor. O servidor, em sua resposta, inclui um cabeçalho (Set-Cookie) como
valor do cookie (xyz). Em todos os pedidos futuros para o servidor de origem, o cliente
inclui o cookie. O cliente não interpreta a string de cookie enquanto a armazena e a
inclui em pedidos subseqüentes. Observar que o cookie é trocado sem o conhecimento
do usuário, a menos que este tenha solicitado que seja avisado toda vez em que
cookies forem enviados.
cliente
Pedido
cliente
Resposta
Set-cookie: xyz
cliente
Pedido
servidor
servidor
servidor
Assim como outros atributos semânticos que podem ser controlados por meio do
browser, os usuários possuem um grau considerável de controle sobre os cookies. Os
usuários podem:
decidir se aceitam o uso de qualquer cookie: tal decisão pode impossibilitar o
download de páginas de alguns sites;
definir um limite para o tamanho e o número de cookies que aceitam: isso controla a quantidade de espaço que eles tem para alocar em suas máquinas e
reduz o risco de cookies extremamente grandes;
decidir se aceitam cookies de todos os sites ou apenas de sites/domínios
específicos: esse controle permite que os usuários aceitem cookies dos sites
desejados e elimina a possibilidade de aceitar cookies de outros sites;
estreitar a aceitação de cookies para a duração de uma sessão específica: um
grau de controle mais fino em nível de sessão permite que os usuários ativem
a aceitação de cookies para conseguir uma tarefa em particular. No final da
sessão, eles retornam ao default, não aceitando mais cookies para as futuras
sessões;
exigir que os cookies venham do mesmo servidor da página atualmente sendo
vista: esse controle garante que o usuário saberá de onde os cookies vêm e
impede que os outros sites (que podem ser contatados automaticamente
pelo browser) enviem cookies. Por exemplo quando um browser faz
download de um documento imagens incorporadas podem ser apanhadas
automaticamente. As imagens incorporadas podem residir em um servidor
diferente daquele que atenda ao documento.
2.3 SPIDERS
Um spider é um programa usado para se obter alguns ou todos os recursos em uma grande
quantidade de sites da web. Um uso inicial de um spider foi para ajudar na manutenção de
sites de web. Atualmente, os recursos são reunidos e usados posteriormente em uma aplicação de pesquisa. A pesquisa na web continua sendo uma das aplicações mais populares e
foi a principal motivação para a criação da ferramenta spider.
2.3.1 Pesquisando na web
A pesquisa na web atualmente é um grande desafio em função do número de páginas e
sites a serem visitados na busca do desejado. Para acelerar esta busca é utilizado como
recurso, uma coleção de ponteiros para as posições nos documentos, das ocorrências das
strings de pesquisa. Tal coleção de documentos é chamada de índice invertido. Tome-se
como exemplo um índice do final de um livro, onde as ocorrências são localizadas a partir de
uma string, sendo que são registradas todas as ocorrências de cada um dos termos
indexados.
2.3.2 Cliente spider
O spider tem a finalidade de obter alguns ou todos os recursos em uma grande quantidade
de sites, principalmente com a finalidade de gerar um índice invertido para ser utilizado por
uma aplicação de pesquisa. Assim como outros clientes da web, o spider prepara pedidos
HTTP para acessar recursos em um site da web e analisa as respostas. As principais diferenças entre um spider e um browser são o número incrivelmente mais alto de sites contatados e pedidos enviados, a ausência de qualquer exibição das respostas e o uso bastante singular das respostas. Os sites de pesquisa utilizam um spider para procurar páginas que precisam ser indexadas. Um spider normalmente começa com uma lista básica de sites populares- lista de partida - e acompanha todos os URLs dentro do site. Um exemplo de lista de
partida é a lista de categorias presentes nos sites de pesquisa. O spider obtém a página
inicial de um site e examina todas as referências de hipertexto embutidas nela. Para cada
uma das referências, a ferramenta pode apanhar a página correspondente- isto é chamado
de travessia em largura. Cada um dos links de hipertexto dentro do site seria seguido e depois os itens dentro deles e assim por diante- esta é uma travessia em profundidade.
Logicamente que há um cuidado para que não haja ciclos, evitando-se atravessar um link
que já tenha sido apanhado. Um ponto interessante para os spiders é obedecer a
determinados padrões dentro da web, por exemplo, devem "respeitar" os sites que não
desejam ser indexados. Algumas convenções existem para isto e os spider devem segui-las
para não comprometer os sites de pesquisa que os utilizam. Uma das convenções utilizadas
para controlar a ação dos spiders é em nível de site : o Administrador do site mantém um
arquivo chamado robots.txt, onde lista as regras de acesso para serem seguidas pelos
spiders (ou robôs- que indica um cliente automatizado). Por exemplo, pode-se ter o
seguinte arquivo robots.txt:
User-agent: *
Disallow: /stats
Disallow: /cgi-bin/
Disallow: /Excite/
Este arquivo indica que todos os agentes de busca tem permissão para apanhar recursos do
site para fim de indexação, exceto nos diretórios /stats, /cgi-bin/, /Excite/
Uma outra forma como os robôs podem ser informados a respeito dos recursos que não
devem ser indexados é por meio da tag META Robots, que é um recurso do HTML. Por
exemplo, uma tag como
<META NAME="ROBOTS" CONTENT="NO INDEX, NO FOLLOW">
informa ao robô que o recurso atual não deve ser indexado e nenhum dos links no recurso
deve ser seguido.
2.3.3Uso de spiders nos utilitários de pesquisa
Os spiders ajudam os utilitários de pesquisa a coletar páginas de muitos sites da web. Dependendo da sofisticação do spider, do tamanho da lista inicial e do espaço de armazenamento disponível, um índice invertido pode ser criado com todas ou algumas páginas. Sites
de utilitários de pesquisa estão entre os destinos mais populares na web e possuem ponteiros para várias fontes de informação. Um utilitário de pesquisa possui uma interface simples
para o usuário inserir uma ou mais palavras-chave (conhecidas como termos de pesquisa).
As palavras-chave são pesquisadas no índice e os ponteiros para os documentos que as
contêm (se houver) são retornados. A pesquisa pode ser local em um único banco de dados
ou o conteúdo indexado da web. O tempo que se gasta em pesquisas na web, é em parte
por falta de um bom índice. Alguns sites como o Yahoo! indexa os sites mas não o conteúdo
de todas as páginas, em outras palavras, somente as páginas básicas dos sites são reunidas
para fins de indexação. Outros sites, como o AltaVista e Google indexam páginas individuais
dentro dos sites. Assim sites como Yahoo! servem para se localizar informações gerais sobre
um assunto em um nível de granularidade menos detalhado, enquanto o AltaVista e o
Google oferecem mais resultados a partir da indexação de todas as strings nos documentos.
Os utilitários de pesquisa variam em sofisticação. A maioria deles oferece o recurso de
pesquisa simples, em que um ou mais termos são pesquisados no índice e ponteiros para
documentos que combinam com qualquer uma das palavras-chave são retornados.
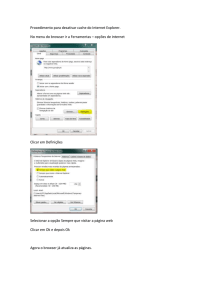
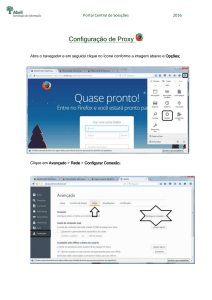
2.4 O Proxy
Em um modelo convencional cliente/servidor, o cliente se conecta diretamente ao servidor
sem intermediários. No caso da web, que utiliza o modelo cliente/servidor, os usuários
fariam suas requisições diretamente aos servidores que enviariam a resposta também
direto para o usuário. Com o aumento do número de usuários e servidores, foi pensada
uma maneira de se atenuar o tráfego dentro da Internet e uma forma encontrada foi a
utilização de um intermediário. Este intermediário faria um cache das solicitações e desta
forma economizaria largura de banda dentro da Internet o que representa uma menor
latência percebida pelo usuário. Na realidade este intermediário ganhou grandes
proporções e é denominado de servidor proxy. O papel deste servidor tem sido considerado
relevante, tanto que passou a fazer parte de sistemas de firewall. Além da tarefa primária
de fazer cache dos sites acessados pelos usuários, o proxy também atua como um filtro para
acesso à web, ou seja, de acordo com a configuração feita, os usuários só terão acesso ao
que não estiver bloqueado por ele. O papel principal do proxy é o de front-end para os
usuários, conferindo compartilhamento de acesso e mantendo a privacidade do usuário. De
uma forma geral o proxy é instalado para proteger uma rede interna , compartilhando um
só acesso. Quando instalado em uma rede local com acesso por LP à Internet, o host que
roda o programa de proxy, terá duas placas de rede, uma como endereço da rede interna e
outra com o endereço conhecido da Internet (endereço externo). Os clientes são
configurados para acessar a rede externa via o proxy. Este recebe a solicitação do cliente,
examina se o endereço pretendido pode ser acessado (de acordo com sua configuração),
verifica se a página pretendida está no cache, se estiver retorna a página ao cliente, caso
não esteja faz o acesso externo e retorna a página ao cliente. O proxy faz também o acesso
ao servidor DNS para resolução de nomes. Todo este processo é transparente para o
usuário, o que o leva a imaginar que o acesso está sendo feito diretamente.
2.4.1 Classificação dos proxies
Mesmo tendo no cache uma função primordial, é possível que alguns proxyes não executem
esta função, executando somente a função de compartilhamento de acesso, encaminhando
as solicitações e respostas. Os proxies podem ainda ser transparentes ou não. Um proxy
transparente não modifica as mensagens que passam por ele, a não ser de maneira
superficial. Um exemplo de uma modificação superficial é a colocação de dados sobre si
mesmo. Já um proxy não-transparente faz algumas alterações nas mensagens, como por
exemplo o endereço da origem, ocultando o endereço do usuário.
2.4.2 Segurança e filtragem de endereços
O proxy tem uma função importante na segurança de uma rede que esteja conectada à
Internet. O fato de ocultar o endereço interno impede as tentativas de ataques a
equipamentos internos da rede. Este fato é perfeitamente válido para os proxies não
transparentes, já que para a rede externa todas as requisições são feitas pelo próprio proxy,
não aparecendo o endereço do usuário. Outro fator contribuinte para a segurança (agora do
ponto de vista tráfego interno para o externo), é a possibilidade de filtrar o acesso à sites
indesejados. Por exemplo, uma determinada empresa pode bloquear sites de diversão para
os usuários.
2.4.3 Encadeamento e hierarquias de proxy
Normalmente os sites tem somente um proxy como intermediário entre o cliente e a Internet, porém nada impede que vários proxyies sejam colocados em cadeia entre o cliente e o
servidor, desta forma pode-se dizer que existirá um encadeamento de proxies, e um será
cliente para o seguinte. Neste esquema, dentro da configuração dos proxies, um proxy pode
se servir do cache do seguinte o que pode facilitar ainda mais o acesso. Por exemplo dentro
de uma instituição com sub-redes, pode ser criado um proxy para cada sub-rede, sendo que
cada proxy destes pode passar por um proxy central que teria o acesso à rede externa.
2.4.4 Protocolos filtrados
Os proxies não filtram todos os protocolos utilizados na Internet. Eles só conhecem o HTTP e
o FTP, sendo que o SMTP não passa pelo proxy já que não é conhecido deste.
2.4.5 O Proxy como servidor na web
Um proxy, em seu papel como servidor na web, é um destino para os pedidos dos clientes.
Um proxy com caching atuando como servidor na web para os pedidos de um cliente pode
verificar se o pedido pode ser satisfeito a partir do seu cache. Se puder responder a partir
do cache e os dados estiverem válidos, o proxy entrega a requisição ao cliente. Caso
contrário, faz a requisição ao servidor de origem e a repassa ao solicitante. Do ponto de
vista do cliente o proxy se comporta como o servidor de origem. A diferença é a redução na
latência quando uma resposta em cache é retornada, pois o proxy está muito mais perto do
cliente.
3.0 SERVIDORES WEB
Um servidor web é um programa que recebe os pedidos dos clientes, faz a devida interpretação deste pedido e gera uma resposta. Este é o terceiro componente de software da
web - os clientes e os proxies são os outros dois componentes. O tratamento de um pedido
consiste em várias etapas básicas: análise da mensagem de pedido, verificação se o pedido
foi autorizado, associação do URL no pedido com um nome de arquivo, construção da
mensagem de resposta e transmissão da mensagem de resposta para o cliente solicitante. O
servidor pode gerar uma mensagem de resposta de diversas maneiras: pode ser um simples
retorno de uma URL, pode ser através da ativação de um script ou pela consulta a um banco
de dados em back-end.
3.1 Servidor da web e site da web
Um site da web consiste em uma coleção de páginas da web associadas a um nome
específico, enquanto um servidor da web é um programa que vai atender a pedidos dos
clientes. Na realidade pode-se dizer que um site da web é composto de um ou mais
servidores da web.
3.2 Servidor web
Este servidor é um programa que trata do atendimento aos pedidos de HTTP por recursos
específicos. A criação e a transmissão de uma página da web pode, na verdade, exigir o
envolvimento de vários servidores, scripts e banco de dados. O servidor é executado em
uma plataforma com acesso à rede e deve ser adequadamente configurado para a carga
que terá para atender a demanda de pedidos. Logicamente um site popular deve ter uma
configuração com maior capacidade do que um site menos popular, porém em qualquer
caso o servidor não deve ser utilizado para outras funções, ou seja, não deve ser
compartilhado para uso comum. Uma prática válida é a instalação de mais de um servidor
dentro da mesma plataforma (por exemplo, servidor web na mesma plataforma de um
servidor ftp). Deve ser evitado a colocação na mesma máquina de servidores que tenham
muitas requisições como por exemplo servidor e-mail e servidor web. Servidores como o de
DNS, dada a sua importância deve ser instalado sozinho em uma plataforma de alta
confiabilidade.
3.2.1 Tratamento de um pedido do cliente
Os servidores web oferecem acesso a uma coleção diversificada de recursos, desde arquivos
estáticos a scripts que geram respostas personalizadas. As etapas no tratamento do pedido
do cliente são as seguintes:
1.Ler e analisar a mensagem de pedido HTTP: o servidor lê a mensagem do pedido
enviado pelo cliente. O cabeçalho da mensagem contém informações de controle,
como a operação foi solicitada (método GET ou POST) e o URL do recurso solicitado;
2.Traduzir o URL para um nome de arquivo: o servidor converte o URL no nome de
arquivo correspondente. O URL pode ter um relacionamento direto com a estrutura
do sistema de arquivo de suporte. Por exemplo, os recursos da web podem estar
localizados em um diretório básico como /www onde o URL www.site.com.br corresponde ao arquivo /www/index.html.;
3.Determinar se o pedido está autorizado: antes de gerar uma mensagem de resposta, o
servidor verifica se o cliente tem permissão para acessar o recurso. Embora muitos
recursos de web estejam disponíveis a todos os usuários, o servidor pode limitar o
acesso a alguns recursos, com base na informação de autorização no cabeçalho de pedido HTTP;
4.Gerar e transmitir uma resposta: o servidor gera uma mensagem de resposta que
inclui um cabeçalho para conduzir informações de status (por exemplo, um erro indicando um pedido não autorizado ou um recurso não existente, um redirecionamento
para o cliente repetir o pedido com um URL diferente ou uma resposta bem sucedida
que inclui o recurso solicitado). Além disso, o cabeçalho pode incluir metadados sobre
o recurso como o tamanho e o formato.
3.2.2 Controle de acesso
Um servidor web pode limitar quais usuários podem acessar certos recursos. O controle de
acesso exige uma combinação de autenticação e autorização. A autenticação identifica o
usuário que originou o pedido e a autorização determina se o usuário tem direito de acesso
o recurso solicitado.
3.2.3Respostas geradas dinamicamente
Além de oferecer recurso estático a web oferece acesso a recursos dinâmicos. Esse recurso
diferencia a web dos serviços mais antigos de transferência de arquivos na Internet.
Respostas
geradas dinamicamente são criadas de diversas maneiras. Uma inclusão no servidor instrui
o servidor a personalizar um recurso estático com base nas diretivas de um arquivo tipo
HTML. Ao contrário, um script no servidor é um programa separado, que gera o recurso
solicitado. O programa pode ser executado como parte dos servidores ou como um
processo separado, que se comunica com o servidor. A geração dinâmica da mensagem de
resposta dá aos criadores de conteúdo uma grande flexibilidade, à custa de um fardo mais
pesado sobre o servidor, além de introduzir riscos em potencial à segurança.
Inclusões no servidor: os criadores de conteúdo normalmente desejam personalizar uma
página da web para o usuário solicitante. Por exemplo, a página pode apresentar a hora e o
endereço IP do cliente. O criador do conteúdo não tem esta informação no momento em
que o arquivo HTML é criado. Em vez disso, o arquivo poderia incluir diretivas, ou macros,
que instruem o servidor a inserir a informação no momento da resposta. A análise de um
arquivo para cada pedido introduziria um fardo desnecessário sobre o servidor,
especialmente se a maioria dos arquivos não incluiu macros. Em vez disso o servidor
determina se o arquivo exige análise, com base no URL. Uma convenção comum é que o
nome do recurso possua uma extensão diferente de html. Por exemplo, uma extensão
shtml, .php ou .asp. PHP (Personal Home Page) é uma linguagem de scripting utilizada em
várias plataformas (como Linux e Windows) e ASP (Active Server Pages) é uma
implementação da Microsoft que roda nos seus servidores. Estas duas implementações
permitem que o servidor execute ações como acesso a banco de dados e formatação de
documentos, por exemplo;
Scripts no servidor: em vez de embutir informações em um arquivo tipo HTML, um
programa separado poderia gerar o recurso inteiro. Nessa situação, o URL na mensagem do
pedido HTTP corresponde a um programa, não um documento. O programa pode realizar
uma série de tarefas, como acessar informações de um banco de dados ou criar uma
resposta personalizada. É muito importante que haja uma separação entre o servidor e o
script. O papel principal do servidor é associar o URL solicitado ao script apropriado e
passar os dados de e para o script. O papel principal do script é processar a entrada do
servidor e gerar o conteúdo para o cliente. O servidor pode interagir com o script das
seguintes maneiras:
oprocesso separado invocado pelo servidor: o script pode ser executado como um processo
separado invocado pelo servidor, para criar o recurso solicitado. Ter um processo
separado isola o servidor da operação do script, mas gerando um overhead adicional na
criação e destruição de um processo para cada pedido. Essa é a técnica tradicional usada
pela Common Gateway Interface (CGI);
omódulo de software no mesmo processo: o script pode ser um módulo de software
separado, que é executado como parte do servidor. A chamada de um módulo dentro do
servidor evita o overhead da criação de um processo separado, com o risco de consumir
um excesso de recursos do sistema do servidor. Essa é a técnica utilizada pela Netscape
Server Application Interface (NSAPI), Internet Server Application Programing Interface
(ISAPI) da Microsoft, módulo mod_perl do Apache e servlets Java da Sun Microsystems;
oprocesso persistente contatado pelo servidor: o script pode ser um processo separado,
que cuida de vários pedidos por um longo período de tempo. O servidor se comunica
com o processo para enviar argumentos e receber a saída. Ter um processo de execução
longo elimina a necessidade de se criar e destruir uma conexão com outros serviços,
como um banco de dados de back-end. Essa é a técnica utilizada pelo FastCGI.
A separação bem definida entre os scripts e o servidor da web exige uma interface bem
definida para a passagem de dados entre as duas partes de software. Primeiro o servidor
precisa determinar se o recurso solicitado identifica um script, em vez de um documento.
Os URLs que correspondem aos scripts normalmente incluem um caracter "?" ou uma
string como "cgi", "cgi-bin" ou "cgibin". No entanto, normalmente, a associação de um
URL com um script é determinada pela configuração do servidor. Por exemplo, o servidor
poderia ser configurado para assumir que qualquer URL com uma extensão em particular
(por exemplo, cgi) ou associada a um diretório (p.ex. /www/cgi) corresponde a um script.
Depois de identificar se o URL corresponde a um script, o servidor verifica se as
permissões de acesso atribuídas ao script permitem a execução. Depois o servidor chama
o script e espera o término de sua execução antes de enviar uma resposta ao cliente. A
existência de uma interface bem definida para a troca de dados é importante para fazer
com que o servidor e o script funcionem juntos. A interface exata difere de uma forma de
scripting para outra. Ainda assim, todas as técnicas focalizam uma necessidade comum
do servidor encaminhar dados de entrada para o script e receber dados de saída. Como
as formas de passar e receber dados dependem do sistema operacional utilizado, será
focalizada a forma de interação entre um servidor UNIX e um script CGI. O servidor web
oferece diversas informações ao script, como mostra a tabela abaixo. As informações
sobre o servidor incluem o nome e a versão do software do servidor, o nome e a versão
do protocolo, o número da porta do servidor e o diretório raiz para os recursos
hospedados no site. As informações sobre os pedidos do cliente incluem o endereço IP e
o nome do host do cliente. As informações sobre o pedido incluem o endereço IP e o
nome do host do cliente. As informações sobre o pedido incluem o tipo de conteúdo do
pedido, o tamanho do pedido e o formato preferido para o recurso solicitado. Outros
campos da mensagem de pedido HTTP estão disponíveis em variáveis iniciadas com
HTTP. Por exemplo, a mensagem de pedido HTTP pode incluir um cabeçalho User-Agent
que identifique o tipo de browser que iniciou o pedido; essa informação estaria
disponível na variável de ambiente HTTP_USER_AGENT. Igualmente a variável
HTTP_COOKIE contém o cookie incluído no pedido HTTP. As variáveis de ambiente
permitem que o script personalize suas operações para o servidor de suporte, o cliente
solicitante e os cabeçalhos de pedido. Por exemplo, o script poderia ler o arquivo
netdata.txt no diretório raiz /www e transformar seu conteúdo para gerar um arquivo
HTML que anuncie o endereço IP do cliente e inclua um texto de saudações em alemãosuíco.
Tipo
Servidor
Variável
SERVER_NAME
Exemplo
www.site.com.br
SERVER_SOFTWARE
Apache/1.2.6
SERVER_PROTOCOL
HTTP/1.0
SERVER_PORT
80
DOCUMENT_ROOT
/www
Cliente
GATEWAY_INTERFACE
REMOTE_ADDR
CGI/2.0
10.10.10.10
Pedido
REMOTE_HOST
CONTENT_TYPE
user.site.com.br
Text/html
CONTENT_LENGTH
158
Tipo
Variável
REQUEST_METHOD
Exemplo
GET
QUERY_STRING
name= usuário
ACCEPT_LANGUAGE
de-CH
HTTP_USER_AGENT
mozzilla/2.0
A CGI também oferece um meio para um script aceitar entrada de um usuário, através formulários HTML. Nestes formulários sempre vai existir um botão do tipo Submit, que ao ser
acionado envia os dados do formulário para o script processá-los (pode ser uma consulta,
um pedido de inscrição, solicitação de cadastramento em um banco de dados, etc). Existem
dois métodos pelos quais o HTTP envia os dados: o método GET e o método POST. O primeiro
envia
os
dados
dentro
da
URL,
como
por
exemplo:
www.site.com.br/script.cgi?nome=usuario e o segundo envia os dados no cabeçalho da
mensagem HTTP. O primeiro método tem uma limitação de 255 caracteres, o que já não
acontece com o segundo. Ao receber o pedido, o servidor chama o script correspondente
para executá-lo e passo os argumentos do usuário por meio de uma variável de ambiente
adicional (QUERY_STRING para formulários baseados em GET) ou através de uma entrada
padrão para formulários baseados em POST.
Tanto em relação aos scripts como em relação às inclusões no servidor (processamento pelas linguagens embutidas no código HTML), deve ser observado o problema de desempenho
do servidor. Sempre que um processo estiver sendo realizado ele está ocupando recursos de
memória do computador e se for um processo que exija muito do servidor, este poderá
sofrer uma degradação apreciável no seu processamento, podendo causar uma latência
observada muito grande. Uma boa maneira de se resolver este problema é colocar os scripts
que exijam mais recursos em máquinas separadas do servidor.
Ao se falar em respostas dinâmicas, a transmissão de vídeo e som aparece em destaque.
Inicialmente a transmissão de vídeo e som pela Internet era muito difícil e não podia ser
realizada “on-line” tendo em vista a capacidade de processamento dos computadores da
época, além do que as linhas de transmissão eram muito lentas (o valor típico para as linhas
era de 16 Kbps). Hoje com a facilidade de processamento e memória para os computadores
pessoais e a facilidade da banda larga, a transmissão em tempo real é comum. Para este fim
utiliza-se o modo “streaming”. Neste modo os arquivos começam a ser reproduzidos quase
que imediatamente, enquanto os dados são enviados, sem ter que esperar pelo download
do arquivo inteiro. Para obter eficiência na transmissão, áudio e vídeo são compactados em
um padrão (MP3, MPEG, etc). Normalmente é utilizado o UDP como protocolo de
transporte, tendo em vista o baixo overhead. O grande problema para este tipo de
transmissão é a capacidade de processamento dos servidores e também a rede que deve
atender a demanda.
Ainda na questão de acesso a páginas dinâmicas, visando a rapidez e a segurança do
ambiente criou-se um ambiente de três camadas: na primeira camada estão os servidores
web para acesso dos usuários, na segunda camada os servidores de aplicações e na terceira
camada os servidores de banco de dados. A primeira camada incorpora uma interface para
os usuários entrarem os dados necessários às transações, na segunda camada os dados são
processados e na terceira os servidores de banco de dados são acessados para recuperação
ou armazenamento. Em termos de segurança, observa-se que os usuários somente têm
acesso à primeira camada, isto quer dizer que nenhum agente externo tem acesso direto
aos servidores de aplicação ou aos sistemas gerenciadores de banco de dados. A figura
abaixo ilustra esta arquitetura:
3.2.4 Arquitetura do servidor
Um servidor normalmente lida com vários pedidos de cliente ao mesmo tempo. Esses pedidos precisam compartilhar o acesso ao processador, disco, memória e interface de rede
no servidor. Existem duas técnicas para alocação de recursos do sistema entre os pedidos de
cliente concorrentes: controle do servidor por evento e controle do servidor por processo.
Controle do servidor por evento: é o modo mais simples de se estruturar um servidor,
pois neste caso existirá um único processo lidando com um pedido de cada vez. O processo
aceita um pedido do cliente, gerando uma resposta e transmite a resposta aos clientes
antes de considerar o próximo pedido. Como uma extensão natural do tratamento de um
pedido de cada vez, um servidor poderia consistir em um único processo que alterna entre
o atendimento a diferentes pedidos. Em vez de lidar com um único pedido em sua
totalidade, o processo periodicamente realiza um pequeno trabalho em favor de cada
pedido. Essa técnica controlada por evento é mais apropriada quando cada pedido
introduz uma pequena quantidade de trabalho confinado. A maioria dos servidores web
não utiliza este controle, tendo que em vista que podem acontecer várias situações que
podem gerar atrasos nas etapas que envolvem o processo de atendimento aos pedidos dos
clientes;
Controle do servidor por processo: como uma alternativa à arquitetura controlada por
evento, o servidor poderia dedicar um processo separado a cada pedido. Nessa técnica,
cada processo realiza todas as etapas envolvidas no tratamento de um único pedido. A
execução de vários processos permite que o servidor atenda a vários pedidos ao mesmo
tempo. Um servidor controlado por processo, normalmente tem um processo-mestre que
simplesmente escuta novas conexões dos clientes. Para cada nova conexão, o processomestre cria um processo separado para tratar da conexão. Depois de analisar o pedido do
cliente e transmitir a resposta, o processo termina. O término de um processo significa que
todos os recursos de memória que foram alocados para ele, automaticamente retornam ao
sistema operacional. Existe um overhead quando da criação de cada processo novo quando
é recebida uma nova conexão e para reduzir este overhead, quando o servidor é
inicializado, um conjunto de processos é criado. Quando uma nova conexão chega, o
processo-mestre identifica um processo inativo e atribui a ele o atendimento deste novo
pedido. Além de reduzir o overhead, a latência também é reduzida.
3.2.5 Estudo de caso do servidor Apache
Para ilustrar a operação de um servidor web, será apresentado o servidor web Apache, que
é uma distribuição gratuita e roda sob vários sistemas operacionais. O objetivo aqui é
explicar em alto nível como o servidor operar e ilustrar que tipos de opções de configurações
estão disponíveis para um administrador.
1.Gerenciamento de recurso: o servidor Apache segue o modelo controlado por
processo, com um processo-pai que atribui um processo-filho para cada nova
conexão. Em vez de criar um novo processo-filho para cada nova conexão, o
processo-pai bifurca previamente vários processos quando o servidor inicia. O
número de processos-filhos adicionais (StartServers) é um dos vários parâmetros
configuráveis que se relacionam a processos-filho. O servidor equilibra o número de
processos. Existe um número máximo de processos simultâneos (MaxClients) que
são configuráveis quando o servidor é compilado.
Diretiva
StartServers
MaxClients
MinSpareServers
MaxSpareServers
MaxRequestPerChild
ListenBackLog
MaxKeepAliveRequests
KeepAliveTimeout
Definição (valor default no Apache 1.3.3)
Número inicial de processos filho (5)
Número máximo de processos filho (256)
Número mínimo de destino de filhos ociosos (5)
Número máximo de destino de filhos ociosos (10)
Número máximo de pedidos por filho (30)
Número máximo de conexões pendentes (511)
Número máximo de pedidos por conexão (100)
Tempo ocioso máximo para a conexão (15 seg)
O servidor impõe um limite sobre o número mínimo e máximo de processos ociosos
(MinSpareServers e MaxSpareServers). A cada poucos segundos, o processo pai determina
quantos processos-filho estão ociosos. Depois o pai cria ou termina os processos-filho,
dependendo se o número ser muito baixo ou muito alto. O encerramento de processos
ociosos retorna os recursos ao sistema operacional para serem usados por processos ativos
e reduz o overhead. Certas configurações são default para cada um dos parâmetros
configuráveis. No entanto, as definições de parâmetros apropriadas dependem da mistura
de pedidos do cliente. Por exemplo, um servidor que recebe um grande número de pedidos
de clientes com pouca largura de banda, deve ter um número relativamente grande de
processos ativos, por dois motivos: primeiro as limitações de largura de banda dos clientes
exigem que o servidor transmita em uma velocidade baixa, exigindo um tempo de
atendimento maior para cada pedido; segundo o servidor precisa ter um número
relativamente grande de transferências simultâneas para fazer uso eficaz de seu link.
O processamento do pedido HTTP tem cinco etapas fundamentais:
1.converter o URL solicitado em um nome de arquivo: o servidor associa o URL a um nome
de arquivo em particular, se houver. Este pode ser um processo um tanto complicado,
que depende da configuração do servidor. De uma forma geral esta tradução pode ser
vista como um mapeamento para uma posição física da página dentro do servidor. Por
exemplo, quando se acesso um site (www.site.com.br) e uma página é aberta, significa
que o servidor foi
configurado para um arquivo padrão (normalmente index.htm ou index.html) situada no
diretório raiz do servidor (também especificado na configuração). Este arquivo
corresponde à página inicial do site. Alguns sites permite que usuários tenham suas
próprias páginas e normalmente estas páginas vêm precedidas do caracter "~", portanto
um URL como www.site.com.br/~nome_usuário pode estar mapeado para
/usuários/nome_usuário/arquivos;
2.determinando se o pedido está autorizado: o servidor pode ser configurado para prover
um controle de acesso, ou seja, pedidos vindo de determinados endereços ou de certos
nomes de hosts podem ser rejeitados ou ainda o usuário pode ter que entrar com alguma
senha para ter acesso ao registro. A configuração
<Directory /dir/html>
AuthType Basic
AuthName specialuser
AutUserFile /user/cadastro
require valid-user
</Directory>
vai permitir que só os usuários cadastrados em /user/cadastro
acessem o diretório /dir/html.
A configuração
<Directory /dir/cgi-bin>
order deny, allow
deny from all
allow from 10.10.10.1
</Directory>
somente aceita pedidos para recursos em /dir/cgi-bin a partir do host 10.10.10.1.
3.identificar e chamar um manipulador para gerar uma resposta: o Apache possui uma
série de manipuladores que realiza uma ação usando o arquivo solicitado, conforme
resumido na Tabela abaixo. O manipulador normalmente é atribuído com base na
extensão do nome de arquivo ou no local, conforme ditado pela configuração do servidor.
Manipulador
default-handler
send-as-is
cgi-script
server-parsed
imap-file
type-map
server-info
server-status
Finalidade (extensão do arquivo)
Enviar o arquivo como conteúdo estático
Enviar o arquivo como uma mensagem de
resposta HTTP (.asis)
Invocar o arquivo como um script cgi (.cgi)
Tratar o arquivo como uma inclusão no
servidor (.shtml)
Tratar o arquivo como um arquivo de regra
Imagemap (.imap)
Tratar o arquivo como um mapa para a
negociação de conteúdo (.var)
Apanhar as informações de configuração do
servidor
Apanhar o relatório de status do servidor
4.transmitir a resposta ao cliente
5.registrar o pedido em um log.
4.Servidor de DNS
O serviço de nomes na web é um fator fundamental para que o cliente tenha acesso aos
recursos na rede. Quando o usuário digita um URL no browser, o primeiro passo é traduzir
este endereço em texto para o endereço IP do servidor ao qual se deseja ter acesso. Esta
"tradução" é feita pelo servidor de DNS (Domain Name System). É fundamental que a
implementação do protocolo na máquina do cliente tenha o endereço de, pelo menos, um
servidor de DNS sendo que normalmente serão dois os servidores apontados (um primário
e um secundário).
4.1 Conceito de Domain Name System
O DNS é estruturado como um banco de dados distribuído, alojado em vários servidores ao
longo de toda a rede. Do ponto de vista do usuário, os domínios de nomes são usados como
argumentos pelos "resolvers" que é o agente local capaz de emitir consultas para os
servidores de DNS e recuperar as informações passando-as ao cliente. Os servidores de
nomes manipulam dois tipos de dados: o primeiro tipo de dados está armazenado em
conjuntos denominados "zonas"; sendo que uma "zona" é um banco de dados completo de
uma parte do domínio. Neste caso o servidor é dito ter autoridade sobre a zona sendo que o
servidor checa periodicamente para ter certeza de que os dados da zona estão atualizados e
se não estiver, obtém uma cópia atualizada de outro servidor de nomes. O segundo tipo de
dados é a partir do seu próprio cache. Este cache eventualmente é descartado por um
mecanismo de timeout. Zona e domínios normalmente são confundidos, porém são algo
diferente. Uma zona é uma parte de um domínio de nomes, porém quando só existe uma
zona dentro de um domínio, a referência geral é para o domínio.
4.2 Arquitetura do DNS
A arquitetura do DNS reflete a hierarquia dos nomes de host e endereços IP. O DNS possui
um espaço de nome hierárquico, com uma raiz sem nome, como mostra a figura abaixo. A
primeira camada contém os domínios de alto nível e os domínios de país com dois
caracteres variando desde Ascension Island (.ac) até Zimbabwe (.zw). Um domínio .arpa
separado trata do mapeamento inverso (de endereço IP para o nome) e será visto com mais
detalhes mais adiante.
Root
/
.com .edu .org .mil
.ac .br .fr. .uk .pt .
.com .edu .mil .gov ...
.uss .faa
www ftp email
4.2 Interpretação do URL
O URL identifica um recurso que se quer ter acesso e é composta no seu total pelo
protocolo a ser utilizado, o nome do servidor e os domínios e sub-domínios onde está
localizado o servidor. Desta forma o URL http://www.site.com.br pode ser analisado como:
.br: indicativo do país ;
.com: indica que dentro do país o domínio pretendido é comercial;
.site: nome do domínio onde se encontra o servidor de origem;
www: nome do servidor.
De posse destes dados o servidor de DNS ao qual o cliente está consultando, faz a sua
busca e retorna o endereço IP do servidor de origem pretendido. Caso este existe e esteja
ativo é retornado o seu endereço, caso não exista é retornada uma mensagem de erro.
4.3 Tipos de consultas
Os servidores de DNS utilizam dois tipos de consultas para resolver os nomes: a consulta
iterativa e a recursiva.
Consulta iterativa: é utilizada de servidor para servidor. Tome-se como exemplo o
endereço www.uss.edu.br. Um computador na Internet que deseje acessar o
servidor www no domínio uss, que está no domínio edu que é um sub-domínio do
domínio br, envia sua consulta para o seu servidor de DNS. Este não tendo o
endereço desejado, faz uma consulta ao servidor de DNS responsável pelo domínio
br solicitando o servidor de DNS do domínio edu. De posse deste endereço, consulta
ao servidor responsável pelo domínio edu quem é o servidor de DNS do domínio uss,
novamente de posse do servidor de DNS do domínio uss, consulta o endereço do
servidor www. Caso o servidor www exista no domínio uss, é retornado este
endereço e o servidor de DNS ao qual está ligado o usuário retorna o endereço IP do
servidor e daí é iniciada a sessão entre os dois hosts;
Consulta recursiva: esta consulta é a realizada entre o host e o servidor de DNS ao qual
está ligado e só pode retornar uma das duas respostas: ou o endereço solicitado ou
uma mensagem de erro.
A figura abaixo ilustra os dois tipos de consultas:
4.4 Otimização de desempenho do DNS
As consultas aos servidores de primeiro nível podem causar um colapso nestes servidores ou
mesmo no link. Para resolver este problema são utilizados dois recursos: um é a replicação
do servidor de primeiro nível em outros servidores e outro é o cache. A replicação consiste
na execução de cópias em outros servidores e o caching é o armazenamento temporário das
consultas feitas, partindo do princípio que esta consulta pode ser repetida várias vezes.
Desta forma, antes de consultar o servidor mais acima, o servidor contatado pelo usuário
consulta o seu cache e se tiver a resposta para a consulta a entrega de imediato.
4.5 Tipos de servidores DNS
Os servidores DNS podem ser englobados em três tipos: os servidores primários, os
servidores secundários e os masters. Os servidores primários são os servidores que tem a
cópia original do arquivo do domínio (ou da zona) e qualquer alteração no arquivo é feita no
arquivo do servidor primário. O servidor secundário pega a cópia dos arquivos de um
servidor primário. Este cópia é somente read-only e não é permitido alterar a cópia no
servidor secundário. Quando um arquivo de uma zona é copiado para outro servidor, diz-se
que houve uma transferência de zona. Várias são as razões para se ter um servidor
secundário: uma delas é a segurança de que o domínio não ficará sem servidor caso o
primário torne-se indisponível e outra razão são os links lentos pelos quais a consulta terá de
atravessar. Com um servidor secundário em local remoto do site, as consultas dos
computadores deste local remoto não precisarão atravessar o link, resultando em respostas
mais rápidas. O servidor master é o servidor do qual o servidor secundário recebe a
transferência de zonas. O endereço do servidor master é configurado no servidor secundário
e pode ser um servidor primário ou mesmo outro servidor secundário. Tanto os servidores
primários como os secundários podem ser considerados autoridades sobre suas zonas
porque tanto um como outro podem responder às solicitações a respeito de suas zonas.
Pode acontecer também de um servidor de DNS não ter nenhum arquivo de zona e neste
caso é conhecido como um servidor de cache. A única responsabilidade do servidor de cache
é fazer as consultas, retornar os resultados e armazenar os resultados obtidos. Esta é uma
boa solução para links mais lentos.
4.6 Resources Records
Todos os resources records do DNS tem um formato similar. O primeiro campo em qualquer
registro DNS é sempre um endereço IP ou um hostname. Observar que todos os nomes e
endereços terminam com um ponto (.). Isto significa que os endereços são absolutos e não
relativos. Endereços absolutos também são chamados de fully qualified domain names e são
relativos à raiz, enquanto endereços relativos o são em relação ao domínio default, que
pode ou não ser o raiz. Este campo pode, opcionalmente, ser seguido por um TTL (Time To
Live), o qual indica durante quanto tempo a informação do campo deve ser considerada
válida. O segundo campo indica o tipo de endereço. Nos bancos de dados atuais, a string
"IN" é a mais comum e indica um endereço Internet. Este campo está presente por motivos
históricos e compatibilidade com sistemas antigos. O terceiro campo é uma string que indica
o tipo de resource Record. Este campo é seguido por valores opcionais que são específicos
para o RR.
Start of Authority (SOA): este registro armazena o nome do DNS e o nome do
responsável por ele. Um exemplo de um SOA:
; Start of Authority (SOA) record
dns.com.
IN
dns1.dns.com. owner.dns.com. (
16200201
; serial number
10800
; refresh (3 horas)
3600; retry (1 hora)
604800
; expire (1 week)
86400) ; TTL (1 dia)
serial number: indica o número de série do arquivo. É um número seqüencial
e normalmente representado pelo dia e ano mais um número que indica a
seqüência . É incrementado a cada vez que o arquivo é alterado;
refresh: diz aos secundários o espaço de tempo no qual o servidor deve ser
consultado para checar quanto a atualização do arquivo;
retry: determina o intervalo de tempo no qual o servidor DNS secundário
tentará entrar em contato com o primário, caso não tenha conseguido da no
primeiro intervalo definido em refresh;
expire: tempo a partir do qual o servidor secundário para de consultar o
primário para novas atualizações, caso não tenha conseguido nas tentativas
anteriores
TTL: este valor é retornado com todas as respostas às consultas ao banco de
dados e diz ao solicitante quanto tempo a informação pode ser mantida com
segurança em cache (no caso 86400 segundos = um dia). Este valor é o valor
default para todos os registros no arquivo e pode ser atualizado por um valor
de TTL provido por outro RR.
O arquivo de DNS para uma determinada zona, ainda inclui outros RR que
definem os endereços e determinados tipos especiais de servidores. São eles:
Address Resources Records: o registro A contém o endereço IP a ser
associado com hostame;
Name Server (NS) Resource Records: o registro NS contém o endereço do
servidor de nomes para o domínio;
Mail Exchanger Server (MX): o registro MX contém o endereço do servidor de
e-mail.
Exemplo de um arquivo de DNS:
; Start of Authority (SOA) record
@
IN
SOA ns.site.com.br owner.site.com.br (
16200201 ; serial number
10800
; refresh (3 horas)
3600; retry (1 hora)
604800
; expire (1 week)
86400)
; TTL (1 dia)
NS
MX
ns.site.com.br.
; nome do servidor DNS
10 mail.site.com.br. ; servidor de e-mail
ns
mail
www
ftp
A
A
A
A
192.168.122.1
192.168.122.2
192.168.122.3
192.168.122.4
Com este arquivo as consultas podem ser feitas de nome para endereços IP.
Porém existem casos nos quais é necessário que o DNS converta os nomes
para endereços IP e para isto existe o arquivo de zona reversa. Este arquivo é
utilizado por exemplo, por servidores de IRC que necessitam saber se a
máquina em questão pode ou não conversar e em caso positivo qual a
prioridade que deve ser dada. Para o acesso completo, deve existir uma zona
reversa. O nome desta zona tem o particular de ser, obrigatoriamente,
endereço IP da rede, de maneira inversa, seguida de .in-addr.arpa. Desta
forma o nome de arquivo de zona reversa para uma rede com endereço
192.168.122.0 será: "122.168.192.in-addr.arpa"
; Start of Authority (SOA) record
@
IN
SOA ns.site.com.br owner.site.com.br (
16200201 ; serial number
10800
; refresh (3 horas)
3600; retry (1 hora)
604800
; expire (1 week)
86400)
; TTL (1 dia)
1
2
3
4
NS
ns.site.com.br.
PTR
PTR
PTR
PTR
ns.site.com.br.
mail.site.com.br.
www.site.com.br.
ftp.site.com.br