UNIVERSIDADE DE SÃO PAULO
ESCOLA SUPERIOR DE AGRICULTURA “LUIZ DE QUEIROZ”
(Departamento de Ciências Exatas/Setor de Matemática e Estatística)
LCE 0602 – ESTATÍSTICA EXPERIMENTAL
Lista 1
Gabarito
Aluno1
Aluno 2
Relatório destinado a avaliação parcial na
disciplina Estatística Experimental (LCE-0602)
Piracicaba
2012
Exercício 1
Os dados apresentados a seguir referem-se ao levantamento da produtividade leiteira
diária de n = 50 produtores rurais atendidos por um plano governamental, realizado na
região oeste do Paraná, no município de Marechal Cândido Rondon.
Os resultados da produtividade média diária, em kg, são dados por:
8,13 8,23
9,80 9,86
9,15 9,78
11,67 12,01
10,31 10,33
8,60 8,80 8,97 9,05
9,90 9,95 10,00 8,78
10,23 10,25 11,04 10,11
9,65 9,92 10,94 10,06
10,40 10,46 10,50 11,14
9,12 9,30
9,34 10,34
10,13 10,15
11,77 11,34
11,29 11,46
9,35 9,78
11,75 12,00
10,16 10,23
10,58 8,99
12,05 12,14
Retire uma amostra sem reposição e de tamanho 30 dos dados apresentados e com
base na mesma:
(a) Obtenha as estimativas da média, da variância e do erro padrão da média
populacionais;
Média estimada
10,26067
Variância estimada
1,15422
Erro padrão da média
0.1972082
A média estimada de produtividade leiteira é de 10,26 kg por dia, com uma
variância de 1,15 kg2 e um erro padrão da média de 0,197kg. Ou seja, pode-se
considerar que o erro padrão da média é “pequeno”, assim como a variabilidade
entre as médias da produtividade.
Resolução no SAS
DATA aula1;
INPUT leite @@;
OUTPUT;
DATALINES; */ amostra gerada no R/*
11.14 8.23 10.50 10.58 9.80 10.15 11.46 10.34 9.95
8.80 9.05 10.16 9.34 9.78 8.97 9.35 9.12 9.78
12.01 11.77 10.06 10.25 12.14 8.13
;
*/ Análise Exploratória/*;
PROC UNIVARIATE DATA=aula1 PLOT NORMAL;
VAR leite;
RUN;
The UNIVARIATE
Variable:
11.67 8.60 9.86
9.15 9.30 10.23
Procedure
leite
Moments
N
Mean
(b)
30
9.989
Sum Weights
Sum Observations
30
299.67
Std Deviation
1.08015436
Variance
1.16673345
Skewness
0.39545798
Kurtosis
-0.4230044
Uncorrected SS
3027.2389
Coeff Variation
10.8134384
Resolução no R
> # Entrada dos dados
Corrected SS
Std Error Mean
33.83527
0.1972083
> y= c(8.13, 8.23, 8.60, 8.80, 8.97, 9.05, 9.12, 9.30, 9.35, 9.78,
+
9.80, 9.86, 9.90, 9.95, 10.00, 8.78, 9.34, 10.34, 11.75, 12.00,
+
9.15, 9.78, 10.23, 10.25, 11.04, 10.11, 10.13, 10.15, 10.16, 10.23,
+
11.67, 12.01, 9.65, 9.92, 10.94, 10.06, 11.77, 11.34, 10.58, 8.99,
+
10.31, 10.33, 10.40, 10.46, 10.50, 11.14, 11.29, 11.46, 12.05, 12.14)
> x=sample(y,30)
> x
[1] 11.14 8.23 10.50 10.58 9.80 10.15 11.46 10.34 9.95 11.67 8.60 9.86
[13] 8.80 9.05 10.16 9.34 9.78 8.97 9.35 9.12 9.78 9.15 9.30 10.23
[25] 12.01 11.77 10.06 10.25 12.14 8.13
> # Cálculo da média, variância e desvio-padrão
> mean(x); var(x); sd(x)
[1] 9.989
[1] 1.166733
[1] 1.080154
> # erro padrão da média
> epm=(sd(x))/sqrt(30);epm
[1] 0.1972082
(b) Calcule o coeficiente de variação;
CV = 10,81%
Como o coeficiente de variação é 10,81%, pode-se dizer que a amostra apresenta
baixa dispersão, ou seja, tem-se uma alta precisão do experimento.
Resolução no SAS
** Marcado na saída do SAS do item (a) - PROC UNIVARIATE
Resolução no R
> #calcule o coeficiente devariação
> CV = (sd(x)/mean(x))*100;CV
[1] 10.81344
(c) Faça a análise exploratória dos dados;
Resolução do exercício no SAS
*/ Tabela de Frequências e Histograma/*;
PROC CHART DATA=aula1;
VBAR leite;
HBAR leite;
RUN;
Figura 1- Diagrama de ramo-e-folhas e box-plot da amostra de 30 produtores de leite .
Figura 2- Normal-plot da amostra de 30 produtores rurais de leite.
Figura 3- Tabela de frequências da amostra de 30 produtores rurais de leite.
Figura 4- Histograma da amostra de 30 produtores rurais de leite.
Resolução no R
>
>
>
>
>
>
# Construção de um diagrama de ramo-efolhas
stem(x)
# Construção de um boxplot
boxplot(x)
# Construção de um histograma
hist(x, col="grey",border="black")
The decimal point is at the |
8
8
9
9
10
10
11
|
|
|
|
|
|
|
12
68
0112333
88899
122233
56
1
11 | 578
12 | 01
Figura 5 - Diagrama de ramo-e-folhas da amostra de 30 produtores rurais de leite.
Figura 6- Box-plot da amostra de 30 produtores rurais de leite.
Figura 7- Histograma da amostra de 30 produtores rurais de leite.
Analisando-se os gráficos apresentados anteriormente, tem-se:
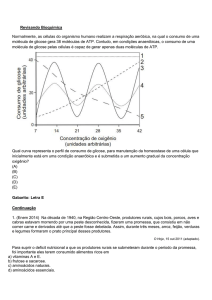
1) No histograma apresentado na Figura 4 (SAS) e Figura 7 (R), observa-se que
a distribuição da produtividade média de leite (kg) dos dados amostrados é
aparentemente unimodal, sendo que as produtividade média se concentra ao
redor do valor de 10kg. Observa-se, ainda, que a distribuição é levemente
assimétrica à esquerda, o que também é observado por meio do box-plot, nas
Figuras 1 e 6.
2) A mesma observação feita para os histogramas pode ser feita para os gráficos
de ramo-e-folhas, apresentados nas Figuras 1 e 5.
3) Observa-se, também por meio do box-plot, que não há valores atípicos.
4) O gráfico Normal-plot, Figura 2, sugere que a distribuição dos dados
amostrados aparentemente não difere da distribuição normal.
(d) Construa os intervalos de confiança para a média populacional, com níveis de
confiança: 95% e 99%;
Com 95% de confiança o intervalo (9,59 ; 10,39) contém a produtividade média de leite
dos produtores rurais.
Com 99% de confiança o intervalo (9,45 ; 10,53) contém a produtividade média de leite
dos produtores rurais.
Resolução no SAS
*/ Intervalo de 95% de Confiança (Alpha=0.05) para média populacional/*;
PROC MEANS DATA=aula1 MEAN VAR STD STDERR LCLM UCLM;
VAR leite;
RUN;
*/ Intervalo de 99% de Confiança (Alpha=0.01) para média populacional/*;
PROC MEANS ALPHA=0.01 MEAN VAR STD STDERR LCLM UCLM;
VAR leite;
RUN;
Resolução no R
> # intervalos de confiança
> t.test(x,conf.level=0.95)
One Sample t-test
data: x
t = 50.652, df = 29, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
9.585664 10.392336
sample estimates:
mean of x
9.989
> t.test(x,conf.level=0.99)
One Sample t-test
data: x
t = 50.652, df = 29, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
99 percent confidence interval:
9.445418 10.532582
sample estimates:
mean of x
9.989
(e) Interprete os resultados obtidos.
Já foi feito para todos os itens, logo após a resolução dos mesmos e antes de
apresentar as saídas dos programas.
Anexar a resolução do exercício a mão
(quando pedido)
Observações:
1) Seguir este modelo como exemplo para a elaboração das
próximas listas a serem entregues.
2) NÃO devem ser impressas todas as saídas do SAS ou do
R, somente as partes que contém a resposta para o item
pedido, conforme este modelo.
3) As interpretações devem ser feitas uma única vez, e
digitadas após cada item. O resultado dos exercícios
feitos a mão devem coincidir com os resultados dos
programas SAS e R (a menos de aproximações) e,
portanto, uma única interpretação é suficiente.
4) Imprimir os trabalhos preferencialmente em Frente e
Verso (vamos contribuir com o meio ambiente).
5) Fazer as listas preferencialmente em duplas (vamos
aprender a trabalhar em equipe).
6) A organização das próximas listas também será
pontuada.
“Nada é tão difícil que você não possa tornar
mais fácil pelo modo que encara.”
Bom trabalho!
Lembretes:
1) A variância é uma medida que expressa um desvio quadrático médio. A
unidade da variância é, portanto, o quadrado dos dados originais.
2) Quando se obtém uma amostra aleatória de tamanho n, estima-se a média
populacional. É bastante intuitivo supor que se uma nova amostra aleatória for
realizada a estimativa obtida será diferente daquela primeira. Desta forma,
reconhece-se que as médias amostrais estão sujeitas à variação e formam
populações de médias amostrais, quando todas as possíveis amostras são
retiradas de uma população. O erro padrão analisa a variabilidade de uma
média.
3) Quando a variável segue uma distribuição normal, o desvio padrão fornece
uma informação adicional acerca da forma como as observações se distribuem
em torno da média, cerca de 68,2% das observações estão contidas no
intervalo definido por média ±1 desvio padrão, 95,4% no intervalo média ± 2
desvios padrão e 99,7% no intervalo média ± 3 desvios padrão.
4) O coeficiente de variação (CV) é geralmente expresso em percentagem. O CV
é independente das unidades adotadas. Por essa razão, é vantajosa para a
comparação de distribuições cujas unidades podem ser diferentes. Uma
desvantagem do CV é que ele deixa de ser útil quando a média esta próximo
de zero. Quanto menor o CV mais preciso tende a ser o experimento. Porém
este valor não é absoluto, pois existe uma variabilidade inerente de cada área
de pesquisa, por exemplo, experimentos realizados em ambiente controlado
(laboratórios) são mais precisos e podem apresentar CV menores que 5%.
Baixa dispersão: CV ≤ 15%
Média dispersão: CV 15-30%
Alta dispersão: CV ≥ 30%
5)
O box plot ( gráfico de caixa) é uma ferramenta exploratória de análise de
dados. O propósito deste gráfico é dar ao analista um método eficiente de
examinar um conjunto de dados, para se ter uma primeira ideia dada
distribuição desses dados. O box plot é especialmente útil quando trabalhamos
com conjuntos limitados de dados para os quais outras ferramentas (tais como
histogramas, que requerem 50 – 200 pontos) podem ser inválidas ou
insuficientes. A posição central dos valores é dada pela mediana e a dispersão
pela amplitude interquartílica. As posições relativas da mediana e dos quartis e
o formato dos bigodes dão uma noção da simetria e do tamanho das caudas
da distribuição.
•
Quando a distribuição dos dados é simétrica, a linha que representa a mediana
estará localizada mais ou menos no centro do retângulo e as duas linhas que
partem das extremidades do retângulo terão aproximadamente os mesmos
comprimentos.
Quando a distribuição dos dados é assimétrica à direita, a linha que representa
a mediana estará mais próxima de Q1 do que de Q3.
Quando a distribuição dos dados é assimétrica à esquerda, a linha que
representa a mediana estará mais próxima de Q3 do quede Q1.
•
•
6) O histograma é um gráfico de barras no qual o eixo horizontal, subdividido em
vários pequenos intervalos, apresenta os valores assumidos por uma variável
de interesse. Um histograma é um resumo gráfico de variação de um conjunto
de dados. A natureza gráfica do histograma permite visualizar padrões difíceis
de ver em uma tabela numérica, como a forma de como os dados se
distribuem, a tendência central de seus valores e sua variabilidade (dispersão).
7) Como muitos valores em cada linha tem as dezenas em comum, podemos
colocar as dezenas em evidência, separando-as das unidades por um traço. Ao
dispor os dados dessa maneira, estamos construindo um diagrama de ramo-efolhas. O lado com as dezenas é chamado de ramo, no qual estão
dependuradas as unidades, chamadas folhas. Os ramos e as folhas podem
representar quaisquer unidades de grandeza (dezenas e unidades, centenas e
dezenas, milhares e centenas, etc). Para sabermos o que está sendo
representado, um ramo-e-folhas deve ter sempre uma legenda, indicando o
que significam os ramos e as folhas.