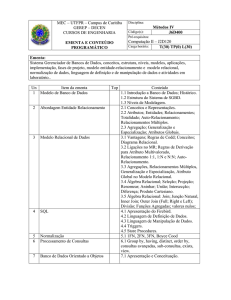
UNIVERSIDADE LUTERANA DO BRASIL
CENTRO DE CIÊNCIAS EXATAS E NATURAIS
CURSO DE SISTEMAS DE INFORMAÇÃO
BANCO DE DADOS RELACIONAL ESTENDIDO
MAURICIO VOLKWEIS ASTIAZARA
IGOR CASA NOVA DOS SANTOS
Banco de Dados II
Torres, Junho de 2001
Introdução
Com este trabalho visamos conhecer um dos tipos de banco de dados não
convencional: o modelo relacional estendido. Procuramos passar pelo conceito de
banco de dados relacional estendido, características, técnica utilizada e vantagens.
Conceito
Diversas novas áreas de aplicação para sistemas de banco de dados são limitadas
por restrições impostas pelo modelo de dados relacional. Entre essas limitações estão a
uniformidade, a orientação a registro e a atomicidade de campos. Notamos que alguns
desses aplicativos requerem linguagens com maior poder expressivo do que o SQL ou a
álgebra relacional.
O modelo orientado a objeto é uma forma de suplantar essas limitações do
modelo relacional, porém sacrifica muitas vantagens do modelo relacional,
especialmente em processamento de consultas.
A solução é uma extensão do modelo relacional, que alarga a aplicabilidade do
modelo sem sacrificar o fundamento relacional. Existem diversos tipos de modelos de
dados que possuem estas características, cada um utilizando uma técnica diferente para
estender o modelo relacional.
Veremos os seguintes modelos:
Modelo de dados baseado em lógica
Modelo relacional encaixado
Modelo de Dados Baseado em Lógica
Para exemplificar este modelo utilizaremos o Datalog, que é uma linguagem de
consulta não-procedural baseada na lógica de primeira ordem. O usuário descreve a
informação desejada sem dar procedimento específico para obtenção daquela
informação.
Técnica
Um banco de dados Datalog consiste em dois tipos de relações:
Relações Base – estão armazenadas no BD, são as tabelas ou entidades do
BD relacional (São as vezes chamadas de BDs extencionais (extensional
database – EBD));
Relações Derivadas – não estão necessariamente armazeadas no BD. Elas
são usualmente relações temporárias que guardam resultados intermediários
computados durante a execução de uma consulta. São as vezes chamados de
BD intencional (intentional database - IDB).
Estrutura da Consulta
[Programa Datalog]
Regra 1
Regra 2
Regra n
Regra 1
Regra 2
Regra n
Consulta
Instrução de Consulta
Instrução de
consulta
A consulta é constituída de duas partes: Programa Datalog e Instrução de
consulta que são executados nessa ordem.
O programa Datalog é um conjunto de regras que envolvem relações base e
derivada. Apresenta a seguinte estrutura:
Cabeça
Corpo
NovaRelação : - literal 1, literal 2, ... , literal n, predicado
Onde:
NovaRelação: é uma nova relação derivada, resultado da execução do corpo
da regra. É definir por um literal;
Relação (1, ... , n): é uma relação base ou derivada;
Predicado: é uma expressão aritmética sobre uma das variáveis das Relações
(1, ... , n).
Literal:
Relação (campo 1, campo 2, ... , campo n)
Onde:
Relação é uma relação base ou derivada;
Campo (1, ... , n) é uma variável ou uma constante que representa o valor do
atributo da relação que está na mesma posição (ordem).
Colocando uma variável na posição de certo atributo, indicamos que este
atributo poderá conter qualquer valor. Colocando uma constante (valor) indicamos que
o atributo deve conter um valor igual ao da constante. A relação só mostrará os registros
que atendem as exigências dos atributos, sendo assim usado para definir critérios de
consulta.
Ex.: sendo a estrutura de uma tabelo chamada depósito:
Nome_agência, número, nome_cliente, saldo
Podemos utilizar a seguinte relação:
Depósito (agência, número, cliente, saldo)
Depósito(“Tramandaí”, X , Y , Z )
Saldo = qualquer valor
Cliente = qualquer cliente
Número = qualquer número
Agência = “Tramandaí”
Observe a correspondência da posição dos atributos com as variáveis/constantes.
Este literal indica que da relação Depósito quero somente os registros que possuam
agência = “Tramandaí”.
Ex.: Regra
Uma vez compreendido os literais, podemos formar uma regra utilizando-os
Rel (Y,X): - Depósito (“Tramandaí”, X, Y, Z), Z>200
Esta regra indica que a nova relação derivada Rel conterá os campos cliente (Y)
e número (X) da relação base Depósito. Sendo que:
Da relação Depósito só os registros agência = “Tramandaí” serão utilizados;
Estes registros devem atender ainda a exigência do predicado saldo (Z)>200.
Resumo: Rel é uma relação derivada que tem o nome e o número dos clientes
que fizeram depósito na agência Tramandaí e com valor maior que 200.
Instanciação de uma regra: é o registro que aplicado-se a regra (substituir
variáveis pelos seus valores) resulta em verdade (satisfaz as condições da regra).
Instrução de Consulta
Existem duas maneiras de efetuar a consulta:
1) Indicando-se que queremos consultar determinada relação.
Relação (campo 1, campo 2, ... , campo n) ?
Ex.:
Depósito (“Tramandaí”, X, Y, Z) ?
Esta instrução não suporta predicado, nem a supressão de campos.
2) Indicando-se que queremos consultar o resultado de uma regra.
Query (campo1, ... , campo n): - relação 1, ... , relação n, predicado
Ex.:
Query (Y): - Depósito (“Tramandaí”, X, Y, Z) Z>1000
Se a consulta não for muito complexa, esta instrução pode dispensar o programa.
Ex. Programa:
Conhecendo-se a aplicação das regras podemos formar um programa, pois como
foi mencionado: um programa é um conjunto de regras. Sendo a base de dados uma
editora de revistas:
Cliente (cliente, cidade, fone, renda, número_revistas)
Tabela de assinantes ou ex-assinantes de revista da editora
Interesse (cliente, interesse)
Interesse dos clientes (Ex.: política, ciência, informática. Etc.)
Assinatura (cliente, revista)
Revista que o cliente assina.
Vamos elaborar um programa que ao final tenha uma relação que contenha o
nome e o fone dos clientes que tem renda maior que R$ 1000 e interesse em
informática.
R1 (N,F): - Cliente (N, C, F, R), R>1000
R2 (N,F): - Interesse (N, “informática”), R1 (N,F)
A relação R2 atende o que foi especificado. Importante observar que as variáveis
de mesmo nome são as mesmas, portanto representando o mesmo valor. No corpo da
última regra a variável N aparece no atributo cliente da relação Interesse e também na
relação R1 indicando valores iguais, assim será formada uma junção entre Interesse e
R1.
Utilizando programa e instrução de consulta podemos formar uma consulta
completa. Vejamos os exemplos a seguir:
Consultar nome e fone dos clientes da cidade de Torres que tem renda maior que
1500 e assinam menos de 3 revistas.
X (Vcliente, Vfone, Vnúmero): - Cliente (Vcliente, “Torres”, Vfone, Vrenda,
Vnúmero), Vrenda>1500
Y (Vcliente, Vfone): - X (Vcliente, Vfone, Vnúmero), Vnúmero<3
Y (Vcliente, Vfone) ?
Uma expressão equivalente usando a instrução de consulta query ao invés de ?
poderia ser:
X (Vcliente, Vfone, Vnúmero): - Cliente (Vcliente, “Torres”, Vfone, Vrenda,
Vnúmero), Vrenda>1500
Query (Vcliente, Vfone): - X (Vcliente, Vfone, Vnúmero), Vnúmero<3
Operações Algébricas de Consulta
Produto cartesiano:
O produto cartesiano entre duas relações dá-se da seguinte forma:
RelProduto (X1, ... , Xn, Y1, ... , Yn): - rel1 (X1, ... , Xn), rel2 (Y1, ... ,Yn)
Onde Xi e Yi são variáveis distintas
União:
Produzir uma relação de união entre duas regras dá-se utilizando a mesma
cabeça para o corpo das duas regras. <observar a diferença da atribuição>
RelUnião (X1, ... , Xn): - rel1 (X1, ... , Xn), predicado
RelUnião (X1, ... , Xn): - rel2 (X1, ... , Xn), predicado
Ex.: Consultar nome e renda de todos os clientes de Torres e Tramandaí.
Rel (A,D): - Cliente (A, “Torres”, C, D, E)
Rel (A,D): - Cliente (A, “Tramandaí”, C, D, E)
Outra forma equivalente seria usar a instrução query:
Query (A,D) : - Cliente (A, “Torres”, C, D, E)
Query (A,D) : - Cliente (A, “Tramandaí”, C, D, E)
Diferença e Negação
Para encontrar a diferença entre duas relações é necessário o uso do operador de
negação, representado pelo símbolo ¬.
RelDif (X1, ... , Xn): - R1 (X1, ... , Xn), ¬ R2 (X1, ... , Xn)
O conjunto das variáveis que aparece em R1 e R2 deve ser o mesmo.
Ex.: Consultar o nome dos clientes que tem interesse em “informática” mas não
assinam a revista “Guia Digital”.
A(X): - Interesse (X, “informática”)
B(X): - Assinatura (X, “Guia Digital”)
C(X): - A(X), ¬ B(X)
Na última relação acima o X satisfará a regra quando ocorrer em A mas não
ocorrer em B.
Recursão
O Datalog permite a utilização de consultas recursivas ampliando o seu poder de
expressão. Isto significa que podemos propor algumas questões para o banco de dados
que podem ser respondidas em Datalog, mas não na álgebra relacional.
Vejamos um exemplo de sua utilização:
Uma tabela de funcionários contendo o seu nome e o nome de seu gerente direto
(primeiro acima dele). Este gerente também é um funcionário e está armazenado nesta
mesma tabela, podendo ele também ter um superior, formando assim uma hierarquia
gerencial.
Funcionário (nome, gerente)
Exemplo de ocorrências nesta tabela:
Nome
Gerente
Bia
Alfredo
Bernardo
Alfredo
Célia
Bia
Carlos
Bia
Valter
Bernardo
Mauro
Bernardo
Daniela
Célia
Eduardo
Carlos
Fábio
Carlos
Vanessa
Valter
José
Valter
Ana
Eduardo
João
Eduardo
Lúcia
Fábio
Para obtermos o nome de todos os funcionários trabalhando diretamente abaixo
de Bia (primeiro nívvel de funcionários de Bia) poderíamos construir a seguinte
consulta:
Query (X): - Funcionário (X, “Bia”)
Para obtermos os nomes dos funcionários cujo gerente direto trabalha sob Bia
(segundo nível de funcionários de Bia) escrevemos:
Query (X): - Funcionário (X,Y), Funcionário (Y, “Bia”)
Seguindo essa lógica poderíamos elaborar uma consulta para qualquer nível de
funcionários sob Bia. Isto também poderia ser feito na álgebra relacional. Porém para
obter o nome dos funcionários de todos os níveis sob Bia não seria possível, pois não se
sabe o maximo sob Bia.
Com o Datalog esta consulta é possível utilizando recursividade. Ela poderia
apresentar a seguinte formulação:
Rel (X): - Funcionário (X, “Bia”)
Rel (X): - Funcionário (X, Y), Rel (Y)
Query (X): - Rel(X) ou Rel (X)?
Observe que esta consulta é recursiva. Primeiro, são adicionados a relação Rel
todos os funcionários do primeiro nível sob Bia. Depois é efetuada uma união com os
funcionários sob os da relação Rel, adicionando a Rel os funcionários de segundo nível.
Como o conteúdo de Rel é acrescido do segundo nível, os funcionários do nível abaixo
deste (terceiro) também serão acrescidos, assim sucessivamente até que não haja
nenhum nível mais baixo.
Funcionários sob Rel são procurados e quando encontrados são adicionados a Rel.
Vantagens
A possibilidade de realizar consultas recursivas aumenta as possibilidades de
modelagem e consulta.
Devido à proximidade com a álgebra relacional possibilita uma “pré-otimização”
da consulta aplicando-se as regras de otimização algébrica.
Modelo Relacional Encaixado
Características
A hipótese da primeira forma normal (1FN) diz que os atributos devem ter
domínios atômicos, ou seja, o domínio deve ser unidade indivisível possuindo um valor
único, não é permitido algo como um array de valores. Entretanto, os exemplos que
motivaram novas aplicações de banco de dados nem sempre são compatíveis com a
hipótese da 1FN. Em vez de ver o banco de dados como um conjunto de registros,
usuários das novas aplicações encaram o banco de dados como um conjunto de objetos.
Esses objetos requerem diversos registros para suas representações.
O modelo relacional encaixado é uma extensão do módulo relacional no qual os
domínios podem ser valores atômicos ou assumirem valores que são relações. Assim o
valor de um atributo pode ser uma relação, e o valor de um atributo dessa relação pode
ser outra relação. Isto permite a construção de um objeto complexo que pode ser
representado em uma única tupla de uma relação encaixada.
Técnica
Para mostrar a implementação de um modelo relacional encaixado vamos
examinar o exemplo de um banco de dados que deve armazenar informações sobre
documentos. Para cada documento são armazenadas as seguintes informações:
Título do documento
Lista de autores
Data
Lista de palavras-chave, palavras relativas ao assunto que o documento trata.
A relação não normalizada e com duas ocorrências de documentos ficaria assim:
Doc, não normalizada
Título
Lista_Autor
Plano de venda
{Samuel, João}
Relatório geral
{João, Fábio}
Data
1/Abril/95
17/Junho/97
Lista_Palavra-chave
{Lucro, Estratégia}
{Lucro, Pessoal}
Observe que o atributo Autor - lista é multivalorado: um documento tem vários
autores, portanto não é atômico. O mesmo ocorre com Palavra-chave - lista. Já data não
é um atributo multivalorado mas pode ser dividido em 3 fragmentos, subcampos.
Pelo modelo relacional tradicional, a mesma relação Doc na 1FN seria:
Doc1 (1FN)
Título
Plano de venda
Plano de venda
Plano de venda
Plano de venda
Relatório geral
Relatório geral
Relatório geral
Relatório geral
Autor
Samuel
João
Samuel
João
João
Fábio
João
Fábio
Agora a versão Doc na 4FN:
Doc4 (4FN)
Dia
1
1
1
1
17
17
17
17
Mês
Abril
Abril
Abril
Abril
Junho
Junho
Junho
Junho
Ano
95
95
95
95
97
97
97
97
Palavra-chave
Lucro
Lucro
Estratégia
Estratégia
Lucro
Lucro
Pessoal
Pessoal
Título
Plano de venda
Plano de venda
Relatório geral
Relatório geral
Autor
Samuel
João
João
Fábio
Título
Plano de venda
Plano de venda
Relatório geral
Relatório geral
Palavra-chave
Lucro
Estratégia
Lucro
Pessoal
Título
Plano de venda
Relatório geral
Dia
1
17
Mês
Abril
Junho
Ano
95
97
Como foi dito anteriormente o modelo relacional encaixado permite a
implementação de relações com atributos multivalorados, que ao invés de conter um
domínio atômico possui uma relação. A definição do esquema de Doc é a seguinte:
Doc=(Título, Lista_Autor, Data, Lista_Palavra-chave)
Lista_Autor=(Autor)
Data=(Dia, Mês, Ano)
Lista_Palavra-chave=(Palavra-chave)
Onde:
Doc tem 4 atributos;
O atributo título tem domínio atômico;
Os outros atributos tem domínios com valores que são relações, que são
definidas logo abaixo;
Uma relação lista_autor é simplesmente um conjunto de autores;
O mesmo ocorre com o atributo lista_palavra-chave;
Já a data é definida por 3 atributos (Dia, Mês e Ano). Note que deste modo é
permitido a um documento ter um conjunto de datas, porém no nosso exemplo
somente uma data para cada documento é necessária.
Linguagem de Consulta Relacional Encaixada
A linguagem de consulta que utilizaremos para ilustrar o Modelo Relacional
Encaixado é a SQL/NF (Nested Form), que é uma versão da SQL estendida para
incorporar operações relacionais encaixadas, existem outras como a XSQL e novas
linguagens estão em fase de desenvolvimento.
Enquanto no SQL padrão só eram permitidos atributos na cláusula “select” e
somente relações na cláusula “from”, a SQL/NF não faz diferença entre relações e
atributos.
Para realizar a seguinte consulta “Dê o título de todos os documentos escritos por
João que dizem respeito a lucro” é utilizada a seguinte instrução:
select Título
from Doc
where “João” in Lista_Autor
and “Lucro” in Lista_Palavra-chave
Considerando uma modificação na consulta para “Dê o ano de publicação dos
documentos escritos por João que dizem respeito a lucro”:
select Título, (select ano from data)
from Doc
where “João” in Lista_Autor
and “Lucro” in Lista_Palavra-chave
Na SQL padrão as funções de agregação (avg, min, max, sum, count) tomam um
conjunto como argumento e retornam um valor como seu resultado. A SQL/NF permite
que estas funções sejam aplicadas a qualquer expressão que dê uma relação como
resultado. Vamos observar um exemplo do uso dessas funções na elaboração da
seguinte consulta “Dê o título e número de autores de cada documento”:
select Título, count (Lista_Autor)
from Doc
É permitido ainda que condições sobre conjuntos, que em SQL padrão são usadas
nas cláusulas “having”, sejam diretamente colocadas na cláusula “where”.
Considerando o esquema de banco de dados abaixo, examinemos o exemplo:
Jogador (nome, pontuação)
pontuação (rodada, pontos)
Consultar o nome e total de pontos dos jogadores com mais de 100 pontos.
select nome, sum (select pontos from pontuação)
from Jogador
where sum (select pontos from pontuação)>100
Como um modelo relacional estendido, o modelo relacional encaixado deve
permitir compatibilidade com o modelo relacional tradicional, por isso existem os
operadores “desencaixar” (unnest) e “encaixar” (nest).
Com o operador desencaixar podemos transformar uma tabela que está modelada
de forma encaixada (não normalizada) em uma na 1FN. Ele possui a seguinte sintaxe
em SQL/NF:
unnest <tabela> on <campo> as <novo campo>
Relação Encaixada Campo multivalorados Novo campo atômico
Por exemplo desencaixar a lista de autores em único campo para a relação Doc:
unnest Doc on Lista_Autor as Autor
O operador encaixar possui sintaxe semelhante ao do desencaixar. Com ele
transformamos uma tabela normalizada em uma encaixada (não normalizada).
nest <tabela> on <campo> as <novo campo>
Relação a ser
encaixada
Campo, ou campos a
serem a agrupados
em um único
Novo campo que
será o resultado do
encaixe
Para gerar a relação Doc a partir de Doc1 (na 1FN) utilizamos os seguinte
comandos de encaixe:
Nest (nest (nest (Doc1 on Autor as Lista_Autor) on
Palavra-chave as Lista_Palavra-chave) on Dia, Mês, Ano as
Data
As operações encaixar e desencaixar podem ser usadas nas consultas.
Considerando o banco de dados abaixo:
Cliente (codcliente, nome, fone)
NF (codcliente, data, valor)
Vejamos a consulta “Dê o nome e a média de compras de cada cliente”:
Select nome, avg (valor_total) From
(nest (select
nome, valor, codcliente from Cliente, NotaFiscal where
Cliente.codcliente=NotaFiscal.codcliente) on valor as valor
total)
Assim pode-se trabalhar de forma encaixada mesmo quando as relações estão
modeladas na forma relacional tradicional (normalizadas).
Como de pode notar, com SQL/NF e o modelo encaixado não é necessário o uso
dos comandos “group by” e “having”, mesmo assim eles estão presentes na SQL/NF
para manter a compatibilidade.
Vantagens
Embora as relações normalizadas possam representar adequadamente um banco
de dados, a representação não normalizada pode ser um modelo de mais fácil
entendimento e mais intuitivo, uma vez que o usuário típico de um sistema pensa na
organização das informações no modo não normalizado. A representação em 4FN
exigiria que os usuários incluíssem junções nas suas consultas, complicando a iteração
com o sistema. Uma visão definida poderia eliminar a necessidade das junções nas
consultas, porém ocorre a perda da representação em uma única tupla.
O modelo encaixado permite ainda total compatibilidade com o modelo relacional
tradicional podendo transformar as relações em 4FN para encaixadas e vice versa.
Conclusão
Com a disseminação da informática os sistemas automatizados de informação
estão sendo aplicados às mais diferentes áreas, das ciências humanas à neurologia, não
ficando mais restritos à aplicação comercial.
Neste contexto, os analistas podem se deparar com sistemas que requerem um
banco de dados com características especiais no modo de tratar e organizar as
informações. Nesse caso os bancos de dados relacionais estendidos são importantes
opções que devem ser levadas em conta.
Por serem uma extensão do modelo relacional é provável que não ocorra nenhum
“trauma” na transição de um modelo para o outro, tanto para o analista quanto para os
usuários, sendo este grande fator a favor dos bancos de dados relacionais estendidos.
Bibliografia
1. KORTH, Henry F.; SILBERSCHATZ, Abraham. Sistema de Banco de Dados. 2
ed. São Paulo: Makron, 1995.
2. _____._____. 3 ed. São Paulo: Makron, 1999.