Bancos de Dados Distribuídos
Sybase
Alunos:
Roberto Costa Flores
Rodrigo Cunha Pinho
Sybase
Introdução
A Sybase Corporation, fundada no ano de 1984, atua basicamente no mercado de softwares de
infra-estrutura com arquitetura aberta para ambientes coorporativo , incluindo:
Bancos de dados
Ferramentas de desenvolvimento
Integração da comunicação em ambientes cliente/servidor
Portais coorporativos
Servidores Wireless e portáteis
As soluções da Sybase para ambiente coorporativo conseguem reunir todas as plataformas
existentes e, segundo a empresa, garantir que todas elas consigam trabalhar em conjunto.
(“Everything Works Better When Everything Works Together”).
A chave é a Arquitetura aberta
O uso de da arquitetura aberta faz com que todas as plataformas possam conviver sem problemas,
preservando assim todos os invenstimentos efetuados anteriormente em infra-estrutura. Isso evita
as chamadas “armadilhas proprietárias” (situações onde a arquitetura do software ou do hardware
são fechadas, ou seja, possuem o seu funcionamento restrito à dispositivos e programas do
próprio fabricante) e aumenta a eficiência e performance das aplicações.
Esta arquitetura aberta permite que sejam integradas:
Plataformas;
Servidores de aplicação;
Componentes;
Bancos de Dados;
Aplicações;
Processos;
Corretores de texto;
Aplicações Wireless.
Divisão do mercado de DDBMS (SGBDD)
Segundo uma pesquisa realizada em 1999, o mercado de sistemas de bancos de dados
distribuídos estava dividido da seguinte forma:
IBM – 32.3%
Oracle – 29.4%
Microsoft – 10.2%
Informix – 4.4%
Sybase – 3.5%
Esta liderança na época da IBM referia-se especificamente à duas plataformas:
mainframe e AS/400. Em todas as outras plataformas, a Oracle liderava o mercado.
Relação de Produtos
Abaixo, a divisão de produtos disponíveis:
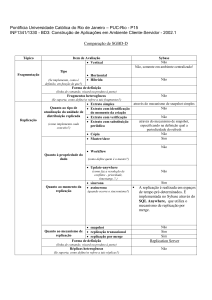
Análise de funções de distribuição do Sybase
1. Projeto de Banco de Dados Distribuído
Suporte à fragmentação
O Sybase resolve a questão da fragmentação através da implementação de views (não
atualizáveis), ou seja, não possui fragmentação. Os tipos de fragmentações horizontal e vertical
são suportados somente para bancos de dados centralizados (ver figura abaixo), onde são
efetuadas utilizando-se cláusulas simples de consulta ou então, para cenários mais complexos,
stored procedures.
Mecanismos de Replicação
As funções de replicação são implementadas no Sybase através do Sybase Adaptive Server
Enterprise (ASE). O produto provê, além dos mecanismos de replicação de dados em um mesmo
banco de dados, a capacidade de acesso a mais de 25 diferentes bancos de dados corporativos.
O processo de replicação de dados no Sybase possui vários componentes. São eles:
Replication Server – programa que mantém os dados replicados na rede local e processa as
transações de dados recebidas pelos outros sites componentes do sistema de banco de dados
(através de seus próprios replication servers). Basicamente transmite os dados (originários do
servidor primário de banco de dados) para os sites de destino, assegurando que cada um deles
terá uma cópia atualizada dos dados e, assim, garantindo a consistência do banco de dados.
Utiliza técnica Store-and-Foward para replicação dos dados. (ver abaixo)
SQL Server (ou Data Server) – é o Sybase Data Server. Gerencia bancos de dados contendo
dados primários ou originais (primary data) ou dados replicados. Trabalha com servidores
heterogêneos, ou seja, suporta diversas plataformas. Recebe e processa as consultas em um
banco de dados e envia as respostas aos clientes requisitantes.
Replication Agent (ou Log Transfer Manager - LTM) – componente que transfere
informações do log de transação do banco de dados para o Replication Server. Ou seja,
detecta alterações efetuadas (insert, updates ou deletions) e, após extrair a transação completa
referente à estas alterações, a transmite ao Replication Server, que irá replicá-la aos demais
sites.
Client Application – processo ou aplicação utilizado pelo usuário, conectado ao data server.
Replication Server Manager (RSM) – ferramenta que permite a monitoração e
administração do sistema de replicação.
Replicated Functions – permite que chamadas de stored procedures do SQL Server sejam
replicadas assincronamente entre os bancos de dados, utilizando um objeto de replicação
denominado Function Replication Definitions. Este método pode significar um aumento de
performance se compararmos com o método normal de replicação. Isso explica-se porque os
dados alterados são encapsulados em uma simples função de sincronização, que pode
executar stored procedures que atualizam diretamente ou não os dados. Podemos ainda
replicar chamadas de stored procedures do servidor primário para o de replicação (applied
funtion) ou vice-versa (request function), através do comando sp_setrepproc.
Exemplo de um processo de replicação
O site de origem realiza uma transação de alteração (update command) no banco de dados;
O Replication Agent (ou LTM) detecta a alteração no banco de dados primário e informa ao
Replication Server (processo servidor de replicação) localizado no site primário;
O Replication Server, então, comunica as alterações à todos os sites de replicação;
Os Replication Servers de cada site destinatário recebem os dados e atualizam o LTM da
localidade;
Os dados são finalmente replicados/atualizados nos sites de destino.
Figura: Replicação de dados utilizando Replication Server
Re-sincronização (Asynchronous Store-and-Forward)
O agente de replicação do Sybase (Replication Server) possui uma função embutida de resincronização é ativada se as alterações efetuadas no banco de dados primário não for replicada
para outros sites, em virtude de indisponibilidade dos mesmos (queda da comunicação, etc).
Esta característica, denominada “Asynchronous Store-and-Forward”, garante que as
modificações efetuadas sejam armazenadas e, assim que os links de conexão entre os sites forem
reestabelecidos, sejam encaminhadas aos sites em questão.
Autonomia
O sistema de replicação utilizado pelo Sybase garante autonomia para todos os sites, provendo
total independência de dados nas operações do dia a dia. Isso porque todos eles guardam a versão
original dos dados alterados e/ou criados (tendo assim controle absoluto dos dados alterados em
sua localidade) e possuem também réplicas atualizadas dos dados atualizados nos outros sites,
mesmo que ocorra uma interrupção na comunicação entre ambos.
Alternando o Banco de dados primário
Fazendo uso da diferença de time-zone entre os sites componentes do sistema de banco de dados,
o Sybase permite que, assim que as operações no site primário sejam terminadas (final do dia),
um outro site seja eleito como site primário
Tipo de fragmento replicado
O Sybase trabalha com fragmentos de cópias. Usa a replicação baseada em transações
(Transaction-Based Replication). Isto significa que o sistema de replicação transmite apenas
transações, e não todos os dados contidos na tabela, reduzindo assim o overhead do servidor.
Desta maneira, alterações efetuadas podem ser replicadas tão logo sejam efetuadas no servidor de
origem.
Forma de replicação
O Sybase trabalha com as duas formas de replicação:
Síncrona (event-driven) - A replicação é efetuada tão logo os dados sejam alterados em seu
servidor primário (origem). Apesar de diminuir a performance, garante sempre um banco de
dados consistente para os usuários. É implementada pelo mecanismo de replicação
transacional.
Assincrona (prescheduled) – A replicação é realizada em espaços de tempo prédeterminados. É implementada no Sybase através do SQL Anywhere, que utiliza o
mecanismo de replicação por merge.
Propriedade do dado replicado
O Sybase trabalha com dados atualizados pelo site principal (primary site), ou seja, utiliza a
propriedade Master/Slave. Entretanto, todos os sites podem ser eleitos como primários, uma vez
que existem situações onde um site poderá estar fora do ar, ou fora de funcionamento (devido à,
por exemplo, procedimento de backup/restore). Por essa razão, cada site tem o seu Replication
Agent que é responsável por detectar alterações realizadas em tabelas existentes dentro do próprio
servidor local e, assim, avisar ao Replication Server para que este possa replicá-las aos demais
servidores do sistema de banco de dados. Isto, logicamente, quando o referido site for o primário
(ou primary) no momento.
Desta maneira, a possibilidade de termos dados inconsistentes é bastante reduzida, uma vez que
somente o site primário pode realizar as alterações.
Além disto, cada site pode ser considerado como primário para um conjunto diferente de dados.
Mecanismos de Replicação
O Sybase utiliza dois mecanismos principais de replicação:
Replicação Transacional – utilizada quando as informações são replicadas de modo síncrono.
Para isto, todos os servidores precisam estar conectados (nenhum dos servidores que
receberão as réplicas poderão estar inativos). O replication agent do servidor gerador das
alterações (Publisher) avisará o replication server sobre as mesmas, e este as replicará
automaticamente para os demais sites (Subscribers);
Replicação por Merge – utilizada quando o existe indisponibilidade de um ou mais
servidores. Para garantir a autonomia dos sites, os mesmos continuam a trabalhar
normalmente até que todos eles estejam ativos e disponíveis. Neste momento, os bancos são
atualizados realizando-se um merge entre as informações de todos os sites. Os sites se
alternam como banco de dados master (publisher), enquanto os outros possuem o papel de
subscriber (sincronizam-se a partir do master). Embora não seja regra, o Replication Server
fica localizado no banco de dados master, acelerando assim o merge entre os servidores.
2. Controle do Ambiente Distribuído
Controle de Segurança
Através de seus Adaptive Servers (ASA ou ASE **), a Sybase oferece serviços de segurança que
incluem:
Autenticação para usuários, clientes e servidores;
Integridade dos dados;
Criptografia dos dados;
Exemplo de mecanismo de segyrança suportado pelos Adaptive Servers: CyberSAFEKerberos
(plataforma Unix).
A figura a seguir exemplifica como uma aplicação cliente utiliza um mecanismo de segurança
para assegurar uma conexão segura com Adaptive Server.
Uma conexão segura entre clientes e servidores pode ser utilizada para:
Autenticação de logins – o cliente valida o login através do mecanismo de segurança. Este
retorna uma “credencial”, que contém relevantes informações sobre segurança. Neste
momento, o cliente envia a credencial para o Adaptive Server que a autentica utilizando
mecanismo de segurança. Se a credencial for válida, uma conexão segura é estabelecida entre
o cliente e o Adaptive Server.
Proteção de Mensagens – Utilizando o mecanismo de segurança, o cleinte prepara o pacote
de dados que será enviado ao Adaptive Server. Dependendo do tipo de serviço de segurança
que for requisitado, o mecanismo de segurança irá encriptar os dados ou criar uma assinatura
criptografada associada aos dados em questão. O cliente envia o pacote de dados ao Adaptive
Server, que utiliza o mecanismo de segurança para validá-los. Somente após isto, o Adaptive
Server iá retornar os dados da forma como foram requisitados, como por exemplo, de forma
encriptada.
Serviços de Segurança e Adaptive Server
Dependendo do tipo de mecanismo escolhido, o Adaptive Server poderá permitir que o uso dos
seguintes serviços de segurança (exemplos de sintaxe dos comandos utilizados nos dois primeiros
itens):
Confidencialidade das mensagens – dados encriptados através da rede;
sp_configure configuration_parameter, [0 | 1]
Integridade das mensagens – verifica possíveis modificações nos dados trafegados;
msg integrity reqd
Autenticação Mútua – verifica identidade do cliente e do servidor. Isto deve ser requerido
pelo cliente (não podendo ser feito pelo Adaptive Server)
Detecção de intrusos – verifica se os dados foram interceptados por indivíduos não
autorizados;
Checagem de ordem – verifica a ordem dos dados trafegados;
Checagem de mensagem original – verifica a origem da mensagem;
Procedimento de segurança remota – estabelece autenticação mútua, confidencialidade das
mensagens (com encriptação) e integridade das mensagens para procedimentos remotos de
comunicação.
Obs: Os Adaptive Server’s atuam como clientes quando conectados com um outro servidor.
Executam um procedimento de conexão remota (RPC – remote procedure call), como mostra a
figura abaixo:
Para listarmos todos os mecanismos de segurança suportados pelo Adaptive Server, devemos
executar a seguinte query: select * from syssecmechs
O resultado retornado será parecido com este:
sec_mech_name available_service
------------------------------ -------------------dce unifiedlogin
dce mutualauth
dce delegation
dce integrity
dce confidentiality
dce detectreplay
dce detectseq
Checando Permissões
A checagem das permissões de acesso no Sybase é realizada pelo SQL Server (ou Data Server),
que analisa se o usuário requisitante (da query) possui as permissões necessárias para acessar o(s)
objeto(s) referenciado(s). Caso o usuário não possua permissão, um erro é gerado e o
processamento da query é interrompido.
Privilégios de Objetos de Bancos de Dados
O usuário que cria um objeto de banco de dados (tabela, view ou stored procedure) tem
automaticamente a propriedade sobre os mesmos e, consequentemente, todas as permissões de
acesso garantidas sobre eles.
Em contra-partida, todos os outros usuários (inclusive o administrador do banco de dados) ficam
automaticamente sem permissões sobre estes objetos. Somente as terão quando forem autorizados
pelo proprietário do objeto ou algum outro que já tenha sido autorizado pelo mesmo.
As seguintes permissões de criação de objetos (por padrão) são dadas ao proprietário e não
podem ser transferidas para outros usuários:
alter table; drop table; create index; create trigger; truncate table; update statistics
Já as permissões abaixo podem ser dadas e revogadas à outros usuários:
select, insert, update, delete, references, and execute
Concedendo e revogando permissões de acesso à objetos de Banco de Dados
Existem dois tipos de permissões para objetos de banco de dados:
• Permissões de acesso à objetos – para utilizar comandos de acesso aos objetos.
• Permissões de criação de objetos – para criação de objetos. Só podem ser concedidos pelo
administrador do sistema ou pelo proprietário do banco de dados.
Exemplos de sintaxe para permissões de acesso (grant command):
grant {all [privileges]| permission_list}
on { table_name [( column_list)]
| view_name[( column_list)]
| stored_procedure_name}
to {public | name_list | role_name}
[with grant option]
revoke [grant option for]
{all [privileges] | permission_list}
on { table_name [( column_list)]
| view_name [( column_list)]
| stored_procedure_name}
from {public | name_list | role_name}
[cascade]
Verificação de permissões concedidas
Para determinar as permissões de acesso de um determinado usuário à um determinado objeto,
executamos o seguinte comando: (no exemplo, verificamos as permissões do usuário Judy ao
objeto titles)
sp_helprotect titles, judy
grantor grantee type action object column grantable
------- ------ ----- ------ ------ ------ ------dbo judy Grant Select titles All
FALSE
dbo judy Grant Update titles advance
FALSE
dbo judy Grant Update titles notes
FALSE
dbo judy Grant Update titles price
FALSE
dbo judy Grant Update titles pub_id
FALSE
dbo judy Grant Update titles pubdate
FALSE
dbo judy Grant Update titles title
FALSE
dbo judy Grant Update titles title_id
FALSE
dbo judy Grant Update titles total_salesFALSE
dbo judy Grant Update titles type
FALSE
Obs: A coluna grantable indica que o usuário não pode conceder nenhuma permissão de acesso à
estes objetos para nenhum usuário (opção FALSE).
Tipos de usuários e suas permissões
O sistema de acesso do Adaptive Server reconhece os seguintes tipos de usuários:
• System Administrators – Lida com tarefas que não são específicas das aplicações. Único que
possui permissão de criar novos bancos de dados.
• System Security Officers – Executa tarefas relacionadas à segurança, incluindo administração
do sistema de auditoria, administração de logins e senhas, segurança de rede, etc. Pode acessar
qualquer banco de dados para habilitar a auditoria.
• Operators – Pode realizar operações de backup e restore dos bancos, sem precisar ser o
proprietário do mesmo.
• Database Owners – Juntamente com o System Admnistrators, podem conceder permissões de
criação de objetos para outros usuários.
• Database object owners – Proprietários (criadores) dos objetos existentes no banco de dados.
• Other users (also known as “public”) – No final da cadeia, estes usuários precisam ter direitos
concedidos por outros usuários hierarquicamente superiores.
Tipos de objetos existentes em um banco de dados
Tabelas
Tipos de Dados
Regras
Stored Procedures
Triggers
Views
Indices
Controle de Integridade
A integridade transacional dos dados é garantida através do uso do Replication Server.
Diferentemente de uso de trigger ou de snapshots (que não assegura integridade dos dados, uma
vez que trabalha com cópias individuais de tabelas, não garantindo as propriedades ACID), o
Replication Server transfere as transações, e não grupos de tuplas ou colunas alteradas pelas
mesmas. Com isso, garante a entrega de informações sempre consistentes.
Características do Sybase para garantir a proteção da integridade dos dados e das
transações
A replicação da transação mantém a integridade transacional de todas as informações
distribuídas
Sites primários (de onde as informações são distribuídas) mantém o controle total sobre os
dados tranmitidos
Dados são enviados para os servidores locais
Replication Server interage com diferentes bancos de dados, utilizando Replication Agents e
EnterpriseConnect Data Access para integrar todos os bancos de todos os fornecedores.
Realocação dos dados é transparente para o usuário
Dados são acessados localmente, garantindo assim a transparência para os usuários.
No Sybase, temos a implementação de controle de integridade de chaves primárias através do
Adaptive Server, que é o responsável pela inclusão dos registros.
3. Suporte a acesso a dados de SGBD Heterogêneo
O acesso a banco de dados heterogêneos é garantido no Sybase através do OmniConnect, um dos
produtos “middleware” da empresa (outros exemplos de produtos “middleware” da Sybase são o
próprio Replication Server e o Open Server)
O OmniConnect garante independência de plataforma, permitindo que os usuários acessem dados
de bancos de outros fabricantes. Além disso, permite que eles trabalhem com estes dados dentro
do próprio Sybase.
O OmniConnect permite que os usuários construam aplicações que acessem dados residindo em
diferentes plataformas de bancos de dados. Isso resolve o problema da interoperabilidade.
Um outro produto disponibilizado pela Sybase com as mesmas funções do OmniConnect é o
DirectCONNECT.
O DirectCONNECT Anywhere foi desenhado para trabalhar com vários tipos de drivers ODBC,
conseguindo assim comunicar-se com distintos bancos de dados. Podemos conectar qualquer
aplicação cliente com qualquer DirectConnect (com exceção do DirectConnect para Oracle)
usando o Sybase 3.01 DirectConnect ODBC driver. Criado pela Intersolv (agora chamada de
Merant), este diver é provido pela Sybase juntamente com o DirectConnect.
Como qualquer driver ODBC pertencente ao ASE (Adaptive Server Enterprise), este driver
também funciona com o protocolo Sybase Open Client. Para isto, as versões 10 ou 11 do Open
Client devem ser instaladas na mesma máquina do DirectConnect.
Outro produto da Sybase que garante acesso de escrita e leitura, em tempo real, à bancos de dados
de outros fabricantes é o Enterprise Data Studio.
OmniConnect conecta bancos de dados de vários fabricantes
O OmniConnect também provê, entre outras coisas, integridade referencial através de bancos de
dados heterogêneos.
OmniConnect, juntamente com o EnterpriseConnect, provê acesso transparente a vários bancos
de dados, incluindo:
Oracle
Ingres
Informix
Rdb
IBM databases:
o DB2 for MVS
o DB2/400
o DB2/2
o DB2 for VM (SQL/DS)
Microsoft SQL Server
Adaptive Server Enterprise
SQL Anywhere(TM)
Mainframe data:
o ADABAS
o IDMS
o IMS
o VSAM
O Sybase utiliza ainda a tecnologia de “gateways” para acesso à outras plataformas, como por
exemplo o Mainframe.
Configurando o ODBC DNS (Data Source Name)
Data Source Name – Nome arbitrário para o DirectConnect ODBC DSN. Campo
obrigatório.
Description – Opcional. Descrição do ODBC DSN.
Server Name – Nome do servidor para o DirectConnect, como está definido para o
Open Client (no arquivo SQL.INI). É um campo obrigatório.
Database Name – Nome do banco de dados que queremos conectar. (na figura, está
em branco). É um campo opcional.
Abaixo, um exemplo de como o Sybase, através do DirectCONNECT, se conecta com outros
bancos de dados:
DirectConnect for Informix
Data Source Name – Nome definido para o Informix ODBC DSN. Este nome será
configurado também no campo Connection Spec 1, na configuração do
DirectConnect for Informix.
Host Name – Nome da máquina onde o banco Informix está instalado.
Server Name – Nome do servidor Informix.
Database Name – O nome do banco de dados Informix que queremos nos conectar,
utilizando o ODBC DSN.
4. Transparência
Transparência de Distribuição
A transparência é uma outra propriedade que, no Sybase, também é garantida pelo produto
OmniConnect, que mantém um catálogo global dos objetos existentes no banco de dados
contendo o mapeamento físico dos mesmos. Os usuários, ao acessarem este catálogo global,
enxergam todos os dados como se estivessem contidos em uma única localidade. Isto permite que
o OmniConnect tenha acesso aos dados mantendo a atual localização dos mesmos transparente
para os usuários. É a chamada transparência de distribuição.
Com isso, não é necessário que os usuários coloquem na consulta, por exemplo, o nome do
servidor onde o objeto está localizado.
Funções adicionais: amplo acesso corporativo e transparência de idiomas
Essa transparência de distribuição fornecida pelo OmniConnect auxilia o desenvolvimento de
aplicações e o suporte ao acesso corporativo. Além de tornar os dados disponíveis para qualquer
usuário (em qualquer momento), permite que as aplicações sejam desenvolvidas
independentemente de onde estejam armazenadas fisicamente.
O OmniConnect provê também transparência de idioma e de procedimentos armazenados (stored
procedures). Isto reduz custos com treinamento para desenvolvedores e usuários, uma vez que a
única linguagem que os mesmos devem conhecer é o T-SQL. Esta é linguagem é traduzida pelo
OmniConnect, que também converte os dados para serem “entendidos” pelo ambiente do Sybase.
Toda essa tradução de parâmetros ocorre de forma transparente para o usuário.
Transparência de Replicação
A transparência de replicação para os usuários é garantida também pela utilização do Replication
Server. Se o usuário estará trabalhando com, por exemplo, uma determinada tabela, não estará
preocupado se a mesma é uma réplica ou não. Quem estará tratando isto será o Replication Server
da localidade, em conjunto com o Replication Server do site primário.
Um outro produto que também implementa a transparência de replicação no Sybase, mais focado
para usuários móveis (mobile users) é o SQL Anywhere Studio.
Transparência de Fragmentação
O Sybase não implementa transparência de fragmentação.
5. Processamento Distribuído de Consulta
Suporte ao processamento distribuído de consulta
O Sybase implementa o processamento distribuído de consulta através do CIS (Component
Integration Services). Trata-se da camada do software que extende o conceito dos Adaptive
Servers aos dados externos. Esta “camada” é utilizada pelo OmniConnect e pelo ASE (Adaptive
Server Enterprise) para prover métodos de acesso às tabelas localizadas em outros sites. Além
disso, provê a transformação da sintaxe SQL (portanto, a interação com o servidor remoto de
dados será efetuado utilizando a linguagem nativa – álgebra relacional).
Como a performance é um a principal preocupação da maioria dos usuários de bancos de dados
distribuídos, o CIS direciona esta preocupação focando-se em dois aspectos principais do
processamento distribuído de consultas:
a. Decomposição da consulta
Processo de análise de uma simples consulta SQL (depois de verificar a existência de erros –
“Parsing”) para determinar a quantidade máxima de processamento que poderá ser efetuada por
um servidor remoto.
Por exemplo, se a cláusula order de uma consulta não puder ser efetuada por um servidor remoto,
o resultado da ordenação terá que ser feito localmente. Irá gerar mais trabalho, pois os resultados
terão que ser armazenados em uma tabela local, armazenados e, somente após isto, apresentados
ao usuário requisitante da consulta.
Estes aspectos são tratados pelos mecanismos de otimização global do CIS, que é extendido ao
otimizador local de consultas do Adaptive Server Enterprise (ASE), para incluir informações
sobre dados remotos.
Para isso, CIS avalia as “árvores de consultas” em dois estágios na fase de otimização do
processamento:
I. Pré-otimização – ocorre antes de o otimizador de consultas ser chamado para analisar as
várias mudanças representadas pela consulta;
II. Pós-otimização – ocorre após a otimização, mas antes da geração e execução do plano de
acesso. Determina a quantidade de processamento que será efetuada por um servidor
remoto e pelo servidor local (site que emite a consulta).
b. Otimizador de consulta
Quando existem transações distribuídas implícitas na sintaxe da consulta, os principais objetivos
do otimizador é:
Determinar custo de acesso para cada servidor remoto;
Determinar estratégia de junção.
Estatísticas de distribuição de tabelas remotas
Sem termos informações sobre custos de acesso à tabelas remotas, é imposível selecionar uma
estratégia ótima de consulta. Por isso, temos que obter estatísticas de distribuição. Isto é feito pelo
Adaptive Server (e OmniConnect) através do comando update statistics.
Se o objeto estiver em uma tabela remota, os dados associados (com os indices) são requisitados e
processados localmente, como se fossem originados de indices locais. O histograma de
distribuição resultante é armazenado no catálogo local para posterior uso pelo otimizador de
consultas.
Outras considerações
Eficientes execuções de consultas distibuídas devem requere que as tabelas remotas sejam
acessadas apenas durante o tempo de processamento da consulta
Em muitos casos, otimizações locais em um site remoto são efetuadas juntando várias tabelas
(deste mesmo site) e realizando-se uma subconsulta remotamente. Somente o resultado desta
subconsulta é transmitido pela rede.
Tipo de otimizador de consulta utilizado e mecanismos de otimização de consulta
distribuída
A otimização de consulta no Sybase também é implementada através do Adaptive Server. O tipo
de otimizador implementado no Sybase é baseado em custos, o que significa que ele se baseia
em estatísticas mantidas pelo servidor para escolher o melhor caminho de acesso para a realização
da consulta.
As estatísticas são um atributo das colunas, e não indices. São agora estatísticas baseadas em
colunas. Com isso, podemos ter estatísticas para qualquer coluna da tabela. Com isso, temos
como definir quais serão as colunas que estarão participando de um indice e, com isso, otimizar o
tempo de pesquisa.
Considerando o exemplo abaixo, como um indice composto em (country e population) e sem
estatísticas para a coluna população.
select * from cities
where country = "UK"
and population > 10000000
Antes da versão 11.9.2 do Sybase, o Adaptive Servers usuaria heurística para estimar o plano de
acesso, na falta de dados de distribuição para a coluna população. Isso poderia causar um plano
ruim de acesso. Este limitante foi resolvido, pois agora toda coluna pode ter suas estatísticas
próprias.
Outra funcionalidade do otimizador de consultas no Sybase é o Cluster Ratios, que provê uma
uma medida mais realística do agrupamento das informações (clustering), permitindo que o
otimizador faça uma melhor estimativa de I/O que será necessário para a realização da consulta.
Uma outra ferramenta é o OPTDIAG, que visualiza, escreve e simula estatísticas armazenadas
nas tabelas de sistema (system tables). Provê uma consistente interface para o usuário em relação
à otimização de consultas. Mostra para o usuário as seguintes opções:
Resumo das informações da tabela, como número de linhas (por exemplo);
Estatísticas de indices, incluindo por exemplo o número de “folhas”;
Custer Ratios de linhas é páginas;
Informações sobre as colunas das tabelas, incluindo histrograma de dados, últimas estatísticas
atualizadas e densidade;
Seleção de desnsidade de default (valores heurísticos)
O OPTDIAG implementa também simulações de estatísticas nas tabelas de sistema. Além disto,
ignora custo quanto ao tráfego de rede e realiza otimização global e local.
Portanto, o Sybase utiliza o otimizador de consultas baseado em custos, apesar de suportar o tipo
baseado em heurísticas. Utiliza também mecanismos de otimização local e global (para sites
remotos).
6. Processamento Distribuído de Transação
Suporte ao processamento distribuído de transação
O protocolo 2PC habilita que aplicações cliente coordenem transacões através de dois ou mais
Adaptive Servers e as trate como se fosse transações locais. Garante também que todos ou
nenhum dos bancos de dados participantes dos Adaptive Servers sejam atualizados
O Sybase utiliza transações denominadas SYB2PC, ou seja, transações que utilizam o protocolo
Two-Phase Commit para asegurar que as transações serão comitadas ou desfeitas (rollback),
como se estivéssemos tratando apenas de uma unidade lógica.
Assim como quase todos os mecanismos do Sybase, as transações SYB2PC são implementadas
pelo Adaptive Server.
Transações de prepare que são coordenadas pelo protocolo SYB2PC são efetuadas ou desfeitas
dependendo do status de commit da transação master. Durante a recuperação, o Adaptive Server
inicia um contato com o serviço de commit para determinar o status de commit da transação
master (principal) e, de acordo com isso, commita ou desfaz a transação de prepare. Se o
Adaptive Server não conseguir comunicação com este serviço de commit, ele espera um
determinado tempo t e, caso não obtenha retorno, desfaz a transação.
O Adaptive Server não tem procedimentos de recuperação de outros bancos de dados no sistema
de banco de dados.
Completando transações heuristicamente
O Adaptive Server inclui comandos como dbcc complete_xact para facilitar a complementação
heurística das transações. O comando resolve uma transação, commitando ou desfazendo-a,
liberando assim os recursos utilizados pela transação.
Este mecanismo deve ser utilizado com precauções, uma vez que pode causar resultados
inconsistentes para uma consulta distribuída, pois pode ir de encontro à decisão tomada pelo
Adaptive Server coordenador ou pelo protocolo de transação utilizado.
Protocolo de recuperação (recovery)
Durante um “crash recovery” a Adaptive Server deverá solucionar transações que estiverem no
estado de prepare. O método utilizado para transações de prepare depende do método de
coordenação ou do protocolo de coordenação utilizado para gerenciar transações distribuídas:
Transações coordenadas com MSDTC
Durante a recuperação, o Adaptive Server inicializa contato com o MSDTC para determinar o
status de commit da transação master e, com isso, resolver se commita ou desfaz a transação de
prepare. Se não conseguir contato com o MSDTC, o procedimento de recuperação espera até que
o contato seja reestabelecido. Outros procedimentos de recuperação não são efetuados até que
esta comunicação seja reestabelecida.
Transações coordenadas pelo Adaptive Server
O servidor local espera até que o Adaptive Server coordenador faça contato e indique que a
transação de prepare deve ser commitada ou desfeita. Para acelerar o processo, o Adaptive Server
recupera cada uma das transações no estado em que estavam antes da ocorrência da falha.
Utilizando este método, o servidor pode deixar o banco online mesmo quando o Adaptive Server
coordenador ainda não tiver resolvido o que fazer com a transação de prepare.
Transações coordenadas pelo SYB2PC
Transações de prepare que são coordenadas pelo protocolo SYB2PC são efetuadas ou desfeitas
dependendo do status de commit da transação master. Durante a recuperação, o Adaptive Server
inicia um contato com o serviço de commit para determinar o status de commit da transação
master (principal) e, de acordo com isso, commita ou desfaz a transação de prepare. Se o
Adaptive Server não conseguir comunicação com este serviço de commit, ele espera um
determinado tempo t e, caso não obtenha retorno, desfaz a transação. O banco de dados não fica
online durante este procedimento de recuperação.
Controle de concorrência
Gerenciamento das transações
O Replication Server depende dos servidores de dados para provêr os serviços de transação que
irão proteger os dados distribuídos. No Sybase, estes servidores que armazenam os dados
primários provêem todo o controle de concorrência necessário para um sistema de banco de dados
distribuídos. Se uma transação falha para, por exemplo, atualizar uma tabela com os dados
primários, o Replication Server não distribui as transações para outros sites. Os dados somente
são atualizados quando nenhuma falha ocorre nas transações.
O Replication Server utiliza controle de concorrência otimizado para manter a consistência dos
dados replicados. Este método possui algumas vantagens em um sistema de replicação:
Promove alta disponibilidade dos dados, porque não trava os mesmos durante a transação
distribuída
Requer menos recursos de sistema para processar uma transação
Transações Replicadas Falhadas
A modificação do dado pode falhar na atualização da cópia replicada do dado em outro site. A
primeira versão é “a cópia oficial”, e as atualizações que forem realizadas no primeiro BD são
replicadas nos sites que possuem cópias dos dados.
Algumas rasões para a possível falha na tabela replicada são:
Usuário acessando o banco com um login sem permissão para atualizar a tabela replicada
A tabela principal e a replicada estão inconsistentes após o recovery do sistema
Atualização do dado direto na réplica da tabela
Entre outras...
Quando uma transação falha, o servidor de réplicas recebe um ERRO do servidor com erro. Os
erros dos servidore\s de dados são mapeados para que uma ação possa ser disparada no intuito de
corrigir o erro. O padrão no caso de falha na transação, é escrever uma mensagem no log do
servidor e posteriormente suspender a conecção. Após a causa da falha ser consertada, você pode
reestabelecer a conecção e o servidor replicado irá tentar executar a transação e continuar
executando a próxima transação.
O processo de resolução do problema na transação pode ser feito manualmente ou então
automaticamente encapsulando-se a logica para efetuar a transação rejeitada em um programa de
aplicação.
Transações que modificam os dados em diversos servidores de dados e banco de dados
Uma transação que modifique o dado em mais de um servidor pode requerer um maior controle
de concorrência.
De acordo com a propriedade de atomicidade de uma transação, se um servidor onde está o dado
falhar em uma atualização por exemplo, todos os outros servidores que possuirem esse dado
devem ter a capacidade de aplicar o “rollback”.
Há exatamente um Replication Agent para cada banco de dados primário. Se uma transação
simples atualiza diversos bancos primários, a transação é replicada em multiplas transações,
sendo uma para cada banco de dados primário. Você pode também escolher por encapsular a
transação em uma simples stored procedure que funciona como uma unidade atômica para
subescrever os diversos sites.
Bibliografia:
Gorelik, Y. Wang, and M. Deppe. Sybase Replication Server. Proceedings 1994
ACM SIGMOD Conference , Minneapolis, Minnesota, May 1994, page 469.
Flexible Update Propagation for Weakly Consistent Replication
Karin Petersen, Mike J. Spreitzer, Douglas B. Terry, Marvin M. Theimer, and
Alan J. Demers (*)
Computer Science Laboratory - Xerox Palo Alto Reasearch Center - Palo Alto,
California 94394 U.S.A
Universidade da California
www.sybase.com