Recuperação de Desastre em Ambiente de Banco de Dados
Vitor de Oliveira Teixeira1, Jean Daniel Henri Merlin Andreazza1
1
Curso de Tecnologia em Banco de Dados - Faculdade de Tecnologia de Bauru
(FATEC)
Rua Manoel Bento da Cruz, nº 30 Quadra 3 - Centro - 17.015-171 - Bauru, SP - Brasil
{vitor.teixeira2, jean.andreazza}@fatec.sp.gov.br
Abstract. In this article, we discuss concepts and tools capable to providing
solutions for disaster and recovery for database. Once defined the concepts
will be discussed deployment and use of specific tool. After the simulation of
disaster a satisfactory response has been obtained, so that minutes after
stopping the main server environment was restored transparently to the user.
Resumo. No artigo serão abordados conceitos e ferramentas capazes de
prover soluções para proteção e recuperação de desastres em banco de
dados. Definidos os conceitos será abordado a implantação e uso de uma
ferramenta específica. Após a simulação de desastre foi obtida uma resposta
satisfatória, de forma que minutos depois da parada do servidor principal o
ambiente foi restaurado de forma transparente para o usuário.
1. Introdução
O armazenamento de informações em bancos de dados informatizados cresce a cada
dia. Instituições, usuários e empresas necessitam de segurança no armazenamento dos
dados, além de cópias de segurança para corrigir erros, ataques cibernéticos ou desastre.
Um banco de dados é uma coleção de registros, ele pode ser relacional ou não
relacional. Para gerenciar essa coleção de registros utiliza-se uma série de programas
que são chamados de Sistemas Gerenciadores de Banco de Dados (SGBD). Conceitos
como cópias de segurança e alta disponibilidade no acesso aos dados podem ser
aplicados para ambos os tipos de banco de dados.
O profissional responsável por administrar um banco de dados é chamado de
Database Administrator (DBA), o DBA deve procurar formas e tecnologias para
proteção e recuperação de desastre quando necessário.
Desastres naturais, falhas ou ataques cibernéticos podem afetar um serviço ou
sistema de forma drástica, poderá também resultar em perda de produtividade e receita,
além de danos financeiros causados pela falta da informação. Para solucionar esta
possível eventualidade, um plano para a proteção ou recuperação de desastre deve ser
traçado para que não resulte em danos financeiros.
O backup diário, semanal ou mensal é de extrema importância, porém quando
necessário recorrer a uma mídia de backup, normalmente o tempo para a recuperação da
informação é demorada, em alguns casos é necessário também a instalação e
configuração de um novo servidor, desta forma o tempo para a recuperação do ambiente
fica comprometido. Alta disponibilidade no acesso aos dados é um motivo para
empresas implementarem um ambiente de recuperação de desastres.
Cada SGBD possui maneiras e ferramentas diferentes para efetuar uma cópia de
segurança dos dados. Este estudo tem como objetivo conceituar o banco de dados
relacional, continuidade de negócios, cópias de segurança e uma ferramenta utilizada
para a recuperação de desastre. Através de pesquisa qualitativa fundamentada a partir de
livros, manuais, sites e artigos, será utilizado ambiente virtualizado para implementação
e análise da ferramenta.
A ferramenta abordada neste estudo é o Oracle Data Guard, que pode ser
utilizada para criação de um ambiente secundário. A ferramenta faz com que a
informação armazenada no banco de dados principal seja replicada de forma íntegra e
on-line para um banco de dados secundário, sendo aplicada somente para o SGBD
Oracle que segue o modelo relacional.
2. Referencial Teórico
2.1. Banco de dados relacional
Segundo Date (2004, p. 6): “[...] um banco de dados é basicamente um sistema
computadorizado de manutenção de registros”. O banco de dados relacional é o modelo
mais popular no mercado, ele possui entidades, atributos e relacionamentos.
SGBD é responsável por armazenar, organizar e otimizar consultas aos dados, o
banco de dados relacional utiliza-se como padrão a linguagem Structured Query
Language (SQL) que foi baseada em álgebra relacional. Ao implantar um SGBD o DBA
deve estudar as formas de backup dos dados e recuperação de desastre.
2.2. Datacenter
Segundo Veras (2009) existe duas maneiras de categorizar um datacenter pelo tamanho
ou pela posse. Quando o datacenter é categorizado pelo porte pode ser empresarial, de
médio porte, local, sala de servidores ou armário de servidores. Segundo Veras (2009) a
norma TIA 942 define a classificação e donwtime para cada tipo de datacenter. O termo
donwtime é utilizado para descrever o tempo de inatividade de um ou mais componentes
do datacenter, desta forma um datacenter pode ser classificado como:
a)
b)
tier 1 básico não existe redundância possui donwtime de 28.8 horas por ano;
tier 2 composto por componentes redundantes com donwtime de 22 horas por
ano;
c)
tier 3 possui sistema auto sustentado com donwtime de 1.6 horas por ano;
d)
tier 4 sem tolerância a falhas possui donwtime de 0,4 horas por ano.
A construção de um datacenter consiste basicamente em analisar pontos como
energia, refrigeração, controle de temperatura, umidade, segurança física,
gerenciamento e monitoramento do ambiente.
2.3. Desastre e recuperação
Para Veras (2009) um desastre é um acontecimento que afeta um serviço ou sistema de
forma drástica, exigindo um grande esforço para voltar no seu estado original, um
desastre pode ocorrer através de terremotos, ataques terroristas, inundações, incêndios
entre outros.
Ainda de acordo com Veras (2009) a recuperação de desastre é a capacidade de
restaurar o serviço ou sistema em caso de desastre. Para restaurar um banco de dados de
forma manual o DBA deve ter a cópia dos dados, a cópia pode estar armazenada
localmente ou remotamente. O armazenamento local de cópias de segurança gera uma
grande brecha na segurança em caso de desastre, essa falha pode ser resolvida utilizando
ferramentas para replicação remota.
Para Shrivastava e Somasundaram (2009) locais alternativos em pontos
geograficamente diferentes é uma estratégia utilizada para o armazenamento de cópias
de segurança, os autores apontam que 80% das interrupção são planejadas, 20% não
planejada e menos de 1% desastre.
Normalmente não se prevê a hora exata de um desastre ou falha, Shrivastava e
Somasundaram (2009, p. 244) faz a seguinte citação “Depois de analisar qual impacto
terá uma interrupção, projetar soluções apropriadas para recuperação de uma falha é a
próxima atividade importante.”, assim a elaboração de um plano de recuperação de
desastre permite o menor impacto possível sobre o negócio. Envolver pessoas
capacitadas e investimento em infraestrutura resultará em ter um bom andamento da
criação de um ambiente de contingência.
2.4. Backup
O backup de um banco de dados é feito com o propósito de continuidade dos
negócios, correção de erros ou dados corrompidos. Em caso de desastre, falha de discos
rígidos, erros de usuários ou falha na aplicação, os dados podem ser danificados, em
alguns casos o DBA só poderá recuperar dados através do backup. O backup não garante
que os dados gravados possam ser utilizados posteriormente, com essa analise um ponto
que deve ser observado é o teste do backup. Para Veras (2009, p. 244) “Deve-se definir
também uma estratégia para recuperação dos dados do backup e testá-lo antes da sua
necessidade real.” É possível efetuar o backup de modo dinâmico onde o banco de
dados continua sendo acessado, ou estático quando não existe acesso durante o período
do backup.
Segundo Shrivastava e Somasundaram (2009) as mídias mais utilizadas para
backup são fitas magnéticas ou discos. Linear Tape-Open (LTO) é uma tecnologia de
fita magnética e possui o modelo LTO3 que permite armazenar 400GB descompactados
ou 800GB compactados enquanto no modelo LTO4 permite armazenar 800GB
descompactados ou 1600GB compactados.
Os dados são gravados na fita de forma linear, com isso a recuperação dos dados
demanda tempo, cuja a gravação é feita de através de um drive. A troca das fitas pode
ser feita de forma manual ou através de um equipamento denominado library, esse
equipamento possui um mecanismos que efetua a troca automática das fitas. Outra
solução para armazenamento de dados de backup são os discos, os quais possuem uma
taxa de leitura e gravação superior comparado a gravação em fita, porém uma estrutura
mais frágil e pode ser facilmente danificado.
2.5. Alta Disponibilidade
Shrivastava e Somasundaram (2009, p. 252) definem alta disponibilidade como
a capacidade da infraestrutura funcionar no tempo da proposta para a operação. Assim,
alta disponibilidade não é total disponibilidade. O Service-level Agreement (SLA)
iniciou-se no início de 1990, como uma maneira dos departamentos de Tecnologia da
Informação (TI) e dos provedores de serviço em ambientes corporativos, medirem e
gerenciarem a qualidade do serviço que eles estavam entregando aos seus clientes.
O SLA foi definido por Sturm, Morris e Jander (2000) como sendo métodos e
procedimentos disciplinados e pró-ativos utilizados para garantir que os níveis serviço
entregues estejam adequados a todos os usuários de TI, em concordância com as
prioridades do negócio e com custo aceitável. Conforme Silva, Martins e Pimski (2005),
há características típicas que podem ser incluídas em um SLA:
a)
b)
c)
d)
horas de serviço disponível;
tempo de resposta;
downtime aceitável para um serviço em um dado período;
alvos de confiabilidade.
Para Silva, Martins e Pimski (2005), nota-se que uma consideração crucial são
os SLA devem estar focados em alvos quantitativos, os quais podem, então, ser
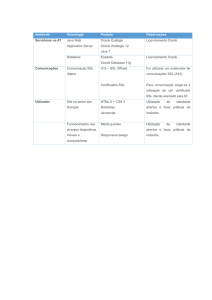
subsequentemente medidos. A tabela 1 possui métricas para dimensionar
disponibilidade através de porcentagens de tempo em que seu ambiente está
operacionalmente ativo.
Tabela 1. Porcentagem de disponibilidade e tempo inativo permitido
Tempo
Ativo (%)
98
99
99,8
99,8
99,99
99,999
99,9999
Tempo
Inativo (%)
2
1
0,2
0,1
0,01
0,001
0,00001
Tempo Inativo por ano
Tempo Inativo por semana
7,3 dias
3,65 dias
17 horas e 30 minutos
8 horas e 45 minutos
52,5 minutos
5,25 minutos
31,5 segundos
3 horas e 22 minutos
1 hora e 41 minutos
20 minutos e 10 segundos
10 minutos e 5 segundos
1 minuto
6 segundos
0,6 segundos
Fonte: Shrivastava e Somasundaram (2009, p. 254)
Para calcular o tempo de disponibilidade de um sistema ou serviço usa a fórmula
onde disponibilidade é D o tempo médio entre falhas é Mean Time Between Failures
(MTBF), enquanto Mean Time To Repair (MTTR) é o tempo médio de recuperação, a
formula é representada da seguinte forma D=MTBF/(MTBF+MTTR).
A tabela 1 mostra sete níveis de disponibilidade, um serviço ou sistema que
possui o MTBF de 8766 horas e o MTTR de 31,5 segundos possui sua disponibilidade
de 99,9999, ou seja, em 1 ano ficara somente 31,5 minutos inativo, para Veras (2009)
um SLA no nível de 99,9999 é muito difícil de ser cumprido.
2.6. Continuidade de negócios
Conforme Shrivastava e Somasundaram (2009, p. 251) a “Continuidade do Negócio”
tem que garantir a “disponibilidade de informações” garantindo as operações da
empresa.
A indisponibilidade de dados em uma empresa pode gerar funcionários ociosos,
multas contratuais, desempenho financeiro fraco, perda de receita, publicidade negativa
e processos judiciais.
A análise de falhas deve verificar e identificar componentes que possam
apresentar pontos únicos de falha, conhecido como Single Point of Failure (SPOF), que
pode acarretar em parada parcial ou completa do serviço ou sistema. O sistema ou
serviço devem ter redundância, assim uma parada não programada poderá ser evitada.
Continuidade de negócio analisa pontos como resposta e recuperação de falhas,
avalia o risco e a segurança dos dados além de medidas em caso de falhas. Para
Shrivastava e Somasundaram (2009) requisitos de Recovery-point Objective (RPO) e
Recovery-time Objective (RTO) são utilizados para definir estratégias para recuperação
de desastre.
RPO ou objetivo de ponto de recuperação é o processo de visualizar o passado e
medir o quanto será necessário voltar no tempo para obter os dados no estado correto,
quanto maior o tempo, maior a tolerância para a perda de dados.
RTO ou objetivo de tempo de recuperação é o processo que estima o tempo que
levaria para o negócio voltar no seu estado normal de trabalho.
A figura 1 mostra o tempo entre o início e o fim de um incidente contemplando
o RPO e RTO.
Figura 1 - Medidas de tempo de RPO e RTO
Fonte: Veras (2009)
Veras (2009) cita backup e restore, replicação local, remota e baseado em
servidor como as principais técnicas para recuperação de um ambiente. De acordo com
Oracle 2008b (2008) um banco de dados standby é uma cópia independente do banco de
dados de produção e pode ser utilizado para proteção contra desastre e para alta
disponibilidade no acesso aos dados. A tecnologia consiste basicamente em copiar o
banco de dados principal para um ou mais banco de dados.
Um banco de dados standby pode ser do tipo:
a)
standby físico fornece uma cópia física idêntica do banco de dados de produção,
mantendo as estruturas de dados, esquemas, índices e funções. O banco de dados
físico de espera é mantido sincronizado com o banco de dados produção;
b)
standby lógico também é mantido sincronizado com o banco de dados Produção,
ele contém a mesma informação lógica da base Produção. Sua organização e
estrutura poderá ser diferente do banco de dados principal, como por exemplo a
criação de índices adicionais, além disso pode ser utilizado para geração de
relatórios.
Um banco de dados em standby pode ser replicado localmente ou remotamente
de modo manual ou automático, bancos de dados em standby podem ser usados para
recuperação de desastres ou consultas de relatórios.
2.7. Banco de dados Oracle
O banco de dados Oracle segue o modelo relacional e oferece ferramentas para
gerenciamento como o SQL Plus, Entreprise Manager, Data Guard entre outros, com
intuito de prover escalabilidade, segurança e alto desempenho.
A Oracle Corporation possui sua sede em Redwood City no estado da
Califórnia, as versões comerciais do banco de dados são Standard Edition, Standard
Edition One e Enterprise Edition, em 2013 foi lançada a versão 12C.
No intuito de popularizar seu banco de dados em 2005 a Oracle lançou a versão
gratuita chamada de Express Edition, essa versão além de não possuir as ferramentas
para alta disponibilidade tem a limitação de gerenciar apenas 1GB de memória RAM e
11GB de armazenamento.
De acordo com Segundo Bryla e Loney (2007) o listener escuta e receber
ligações de clientes Oracle, cada servidor deve possuir o arquivo listener.ora com as
devidas configurações.
Segundo Bryla e Loney (2007, p. 50) “Sempre que os dados são adicionados,
removidos ou alterados em uma tabela índice ou outro objeto Oracle, uma entrada é
gravada no arquivo de redo log atual”. O banco de dados Oracle pode trabalhar em
modo noarchivelog ou archivelog, diferente do modo noarchivelog o modo archivelog
envia a cópia dos arquivos de redo log para um ou mais destinos. De acordo com Oracle
(2008c) redo log é estrutura mais importante para operações de recuperação, os redo log
são dois ou mais arquivos que armazenam todas as alterações feitas no banco de dados.
A combinação de área de memória reservada e processos em background é
denominada de instância no banco de dados Oracle, o identificador da instancia é
denominado de SID. Para iniciar a instância o SGBD inicialmente procura o arquivo
SPFILE, se o arquivo não for localizado então é utilizado o PFILE, ambos possuem
informações necessárias para o funcionamento do banco de dados.
3. Oracle Data Guard
O Oracle Data Guard é uma solução para proteção contra desastres, a ferramenta é
flexível e oferece disponibilidade e desempenho além de um gerenciamento
centralizado do ambiente.
O Oracle Data Guard deve ser utilizado em conjunto com o Oracle Database
Enterprise Edition. Sua estrutura foi projetada para que a falha de um único componente
não afete a disponibilidade de dados, ou seja o banco de dados da produção é replicado
para um ou mais bancos de dados em standby que podem estar em locais
geograficamente diferentes.
De acordo com Bryla e Loney (2007, p. 50) “O uso de múltiplos destinos de log
arquivados para arquivos de redo log preenchidos é crucial para um dos recursos de alta
disponibilidade do Oracle conhecido como Oracle Data Guard”
A figura 2 mostra processo Physical standby database que é um dos modos para
replicação remota de dados.
Figura 2. Visão do banco de dados Produção e Standby
Fonte: Oracle (2008a).
O banco de dados de Produção e Standby podem ser acessados por meio de
ferramentas de linha de comando SQL ou através do Data Guard Broker (DGMGRL)
que é uma interface de linha de comando. Segundo Oracle (2008d) sem o DGMGRL o
DBA deverá gerenciar os bancos separadamente.
O Oracle Data Guard possui três formas de proteção de dados, são elas:
a)
maximum protection: Antes da transação ser confirmada os redo log serão
gravados no banco de dados Produção e Standby. Nesse modo o banco de dados
Produção é desligado se ocorrer alguma falha;
b)
maximum availability: Ao contrário do modo maximum protection, o banco de
dados Produção não é desligado se ocorre alguma falha. Em vez disso ele opera em
modo de desempenho máximo até que a falha seja corrigida;
c)
maximum performance: Este é o modo padrão de proteção, ele trabalha de
forma assíncrona e fornece um nível de proteção de dados próximo ao modo
maximum availability com um impacto mínimo no desempenho do banco de dados
Produção.
Em todos os modos de proteção é necessário definir os parâmetros para o
transporte de redo log.
3.1. Configuração do ambiente
Para implementação, testes, simulação de desastre e obtenção dos resultados,
será utilizado três hosts virtuais, um denominado “Cliente” e dois servidores
denominados de "Produção" e "Standby". O host utilizado como hospedeiro dos virtuais
possui o sistema operacional Microsoft Windows 8.1 64 bits, 120 GB de disco rígido
SSD, 8 GB de memória RAM e Oracle VM Virtual Box 4.3.1.
Os servidores virtuais possuem sistema operacional Microsoft Windows 2008
Server R2 64 bits, 20 GB de disco rígido, 2 GB de memória RAM e banco de dados
Oracle Database Enterprise Edition Release 11.2.0.1.0. Inicialmente foi feito a
instalação e configuração do banco de dados Oracle Database Enterprise no servidor
Produção, enquanto no servidor Standby somente a instalação do software sem a criação
do SID e LISTENER.
O host Cliente possui sistema operacional Microsoft Windows 8.1 64 bits, 20
GB de disco rígido, 2 GB de memória RAM e Client Oracle Database 11g Release
11.2.0.1.0.
3.2. Parâmetros de configuração
Para efetuar as modificações dos parâmetros será utilizado o SQL Plus logado como
usuário sys com a role sysdba. Inicialmente é necessário definir o formato e onde os
archives logs serão gravados. O banco de dados deve trabalhar em modo archivelog e
force logging, a figura 3 demonstra o processo necessário para as alterações.
Figura 3. Modo de Trabalho
O banco de dados Produção deve estar open, desta forma qualquer usuário que
tenha permissão, pode conectar e executar operações comuns de acesso. É necessário a
alteração de diversos paramentos para o funcionamento da ferramenta, também é
necessário a criação dos Standby Redo Log (SRL), para definir o tamanho e quantidade
de grupos SRL é necessário verificar o tamanho e quantidade do redo log. De acordo
com Oracle (1999) o SRL deve ter pelo menos um grupo a mais que os redo log.
Para estabelecer a conexão entre os hosts é necessário que cada host conheça o
endereço IP, número de porta, nome da instância e tipo de método de resolução de
nome. No servidor Standby será necessário a configuração do LISTENER através do
software Net Configuration Assistant e a criação do SID com o nome de STDBY
através do programa ORADIM. Será necessário a configuração dos seguintes arquivos
nos servidores:
a) hosts: Contém informações de endereço IP e nome dos servidores.
b) listener.ora: Será usado para que a ferramenta DGMGRL tenha permissão para
reiniciar a instância quando necessário. Os dois servidores devem ter a entrada
SID_DESC dentro do SID_LIST_LISTENER.
c) sqlnet.ora: No parâmetro NAMES.DIRECTORY_PATH deve constar o valor
TNSNAMES, esse parâmetro define o método de pesquisa de resolução de nomes.
d) tnsnames.ora: O arquivo contém informações como número de porta, nome da
instância, nome do servidor, tipo de protocolo e tipo de servidor.
O arquivo hosts está localizado em C:\Windows\System32\drivers\etc, os
arquivos listener.ora, sqlnet.ora e tnsnames.ora estão localizados em
C:\app\oracle\product\11.2.0\dbhome_1\NETWORK\ADMIN.
No host Cliente será necessário somente a configuração dos arquivos sqlnet.ora
e tnsnames.ora, localizados em C:\app\oracle\product\11.2.0\client_1\network\admin. O
arquivo tnsnames.ora possui a entrada DATAGUARD que contém informações
referentes aos dois servidores, desta forma caso houver indisponibilidade de acesso no
servidor Produção será redirecionado para o servidor Standby.
Após a configuração dos servidores deverá ser utilizado o Recovery Manager
(RMAN) que executa tarefas de backup e recuperação de dados. Segundo Oracle
(2008a) as ferramentas RMAN e Data Guard podem ser usadas em conjunto. Não será
abordado o uso conjunto das ferramentas, o RMAN será utilizado apenas para efetuar o
backup do banco de dados Produção.
A figura 4 mostra a criação do backup do banco de dados em Produção.
Figura 4. Criação do backup
É necessário criar o arquivo PFILE através do SPFILE com o nome de
initSTDBY.ora. O conteúdo do arquivo initSTDBY.ora deve ser alterado de forma que
onde apareça o nome da instância orcl deve ser alterado para stdby e vice e versa. Após
a alteração deve ser criado o SPFILE através do arquivo initSTDBY.ora modificado.
Os arquivos de backup gerados na pasta C:\app\oracle\backup\rman\ devem ser
movidos para o servidor Standby utilizando a mesma estrutura de pasta, também deve
ser movida a pasta de senha C:\app\oracle\product\11.2.0\dbhome_1\database\PWDorcl,
o nome da pasta deve ser alterado para PWDstdby. Após mover arquivos no servidor
Standby deve ser aplicado o comando “duplicate target databse for standby” para
restaurar o backup.
Efetuado as configurações e a restauração do backup no servidor Standby deverá
ser ativado o segundo destino dos archive logs e a ferramenta Data Broker nos
servidores.
3.3. Funcionamento Data Guard
Para iniciar a aplicação dos redo logs no banco de dados Standby é necessário a
execução do comando no servidor Standby “alter database recover managed standby
database using current logfile disconnect from session”. O servidor Standby está pronta
para receber O Data Guard armazena informação para controlar a aplicação dos redo
log. Na figura 5 é possível verificar que o campo DEST_ID possui a numeração 1 e 2,
essa numeração define que os dois bancos de dados receberão a mesma informação.
Figura 5. Catálogo Data Guard
O termo switchover é utilizado para denominar quando o banco de dados
Standby for ativado. Quando é feito o switchover o banco de dados Standby é
transformado em banco de dados Produção, e o Produção passa a ser o Standby. Já o
termo switchback é utilizado para denominar a volta do cenário inicial, o Produção que
virou Standby volta a ser Produção e o Standby que virou Produção volta a ser Standby.
A figura 6 mostra o processo antes do switchover, onde a instância ORCL está
como Primary database e a STDBY está como Physical standby database.
Figura 6. Data Guard antes do switchover
A figura 7 mostra o processo após do switchover to stdby, onde a instância
ORCL está como Physical standby database e a STDBY está como Primary database.
Figura 7. Data Guard após do switchover
3.4. Simulação de funcionamento
Para simular o funcionamento do Data Guard será criado ambiente com usuário, tabela
e dados. Inicialmente a conexão será através do servidor Produção, após isso será
efetuado processo de switchover para o servidor Standby.
A figura 8 demonstra a criação de usuário vitor, a conexão foi através do SQL
Plus do host Cliente, utilizando a entrada dataguard criada no arquivo tnsnames.ora.
Figura 8. Conexão através do TNSNAMES
A figura 9 mostra a criação da tabela usuário e a inserção do primeiro registro no
servidor Produção.
Figura 9. Criação de tabela e inserção de dados
É possível verificar na figura 10 que os dados foram inseridos corretamente.
Figura 10. Dados Produção
A figura 11 demonstra os mesmos dados do servidor Produção, isso ocorre
porque os dados foram replicados corretamente para o servidor Standby.
Figura 11. Dados Standby
Com intuito de simular a perda do servidor Produção efetuou-se o switchover
para o servidor Standby. Com o servidor Produção desligado tentou-se a conexão
através do host Cliente a resposta foi satisfatória.
4. Conclusão
Os conceitos abordados possibilitam ao DBA ter uma visão do ambiente de forma mais
ampla. A visão do ambiente passa por tecnologias que provêm alta disponibilidade no
acesso aos dados e a continuidade de negócio, que envolve temas como SLA, RPO e
RTO. Os conceitos como backup e standby demostram tecnologias que podem ser
utilizadas para a resolução rápida e em médio prazo para alguns problemas que se
referem ao acesso aos dados.
Após a definição dos conceitos foi demonstrada a implantação da ferramenta
Data Guard. A implantação da ferramenta passa por diversos passos e conceitos,
através da simulação de desastre foi obtida uma resposta satisfatória, de forma que cinco
minutos e quarenta e oito segundos depois da parada do servidor Produção o ambiente
foi restaurado de forma transparente para o usuário.
Conclui-se que o sucesso da ferramenta é atrelada a criação de um ambiente
seguro, eliminando assim possíveis SPOFs.
Referências
Bryla, B; Loney K. “Manual do DBA”, Porto Alegre: Bookman, 2007.
Date, C. J. “Introdução a Sistemas de Banco de Dados”, 8 Ed. Elsevier, 2004.
Oracle. 1999. “Oracle Data Guard Concepts and Administration 11g Release 2 (11.2)”,
http://docs.oracle.com/cd/E11882_01/server.112/e17022/log_transport.htm#SBYDB
4760, Abril.
Oracle. 2009. “Oracle Data Guard com Oracle Database 11g Release 2”,
http://www.oracle.com/technetwork/pt/database/enterpriseedition/documentation/data-guard-com-database-11g-r2-1721669-ptb.pdf, Setembro.
Oracle. 2008a. “Data Guard Scenarios”,
http://docs.oracle.com/cd/B19306_01/server.102/b14239/scenarios.htm, Março.
______. 2008b. “Glossary”,
http://docs.oracle.com/cd/E11882_01/server.112/e40540/glossary.htm#CNCPT8931
4, Abril
______. 2008c. “What Is the Redo Log?”,
http://docs.oracle.com/cd/B28359_01/server.111/b28310/onlineredo001.htm#ADMIN1
1302, Abril
______. 2008d. “Oracle Data Guard Broker”,
http://docs.oracle.com/cd/B28359_01/server.111/b28295/concepts.htm#i1005616, Maio
Shrivastava, A; Somasundaram, G. “Armazenamento e Gerenciamento de
Informações”, Bookman, 2009.
Silva, N. S. Da; Martins, V. A.; Pimski, I. “A Importância dos SLAs na relação das
empresas de serviços com seus fornecedores visando a entrega de valor superior para
o cliente”. In: VIII Semead, 2005, São Paulo. VIII Semead, 2005,
http://www.ead.fea.usp.br/semead/8semead/resultado/trabalhospdf/430.pdf
Sturm, R; Morris, W; Jander, M. “Service Level Management: Fundamentos do
Gerenciamento de Níveis de Serviço”. Rio de Janeiro: Campus, 2000.
Veras, M; “Datacenter Componente Central da Infraestrutura de TI”, 1 Ed. Brasport,
2009.