AVALIAÇÃO DO INDICADOR DE DESEMPENHO DE
BANCOS DE DADOS DISTRIBUÍDOS COM O USO DE
REPLICAÇÃO DE DADOS ALOCADOS EM UMA REDE
WIRELESS
ANUÁRIO DA PRODUÇÃO DE
INICIAÇÃO CIENTÍFICA DISCENTE
Vol. 13, N. 20, Ano 2010
Igor Fonseca Paixão
Prof. Teresinha Planez
Diniz da Silva
Curso:
Ciência da Computação
CENTRO UNIVERSITÁRIO
ANHANGUERA DE CAMPO GRANDE UNIDADE 1
RESUMO
Este projeto propõe aferir a performance de uma base distribuída
instanciada em uma rede Wireless. A partir de um estudo de
caso, uma base de dados que contextualiza o uso de sistemas
distribuídos foi produzida e modelada, e, posteriormente,
mecanismos de replicação foram agregados. Expressões na
linguagem SQL, com grau de complexidade diferenciada, foram
codificadas a fim de serem utilizadas em testes e aferição de
resultados. Os resultados obtidos apresentaram um acréscimo de
tempo insignificante ao aplica técnicas de replicação de dados,
permite concluir que o indicador otimização não foi
comprometido.
Palavras-Chave:
Desempenho.
Banco
de
dados
distribuído;
Replicação;
Anhanguera Educacional Ltda.
Correspondência/Contato
Alameda Maria Tereza, 4266
Valinhos, SP - CEP 13278-181
[email protected]
Coordenação
Instituto de Pesquisas Aplicadas e
Desenvolvimento Educacional - IPADE
Publicação: 5 de novembro de 2012
Trabalho realizado com o incentivo e
fomento da Anhanguera Educacional
329
330
Avaliação do indicador de desempenho de bancos de dados distribuídos com o uso de replicação de dados alocados em uma rede wireless
1.
INTRODUÇÃO
A dependência da sociedade da informação em relação à produção de informações
contendo volumes significativos de dados vem requerendo a produção de banco de dados
cada vez mais robustos, seguros, com alta disponibilidade e performance gerenciado por
uma estrutura maior denominada sistema de informação. O'Brien (2004) define sistema
como um grupo de elementos inter-relacionados ou em interação que forma um todo
unificado, sendo necessário alocar diversos recursos entre eles, recursos de dados. Entre
os diversos componentes de um sistema de informação encontra-se o banco de dados,
estrutura lógica de armazenamento.
Diversas tecnologias são agregadas atualmente de modo a garantir tais
características, porém, a inserção de modo desenfreado pode comprometer determinados
indicadores de qualidade. Nesse contexto deve-se considerar, também, a mobilidade
oferecida pela computação móvel. A ausência de um planejamento, ou um planejamento
centralizado, pode ser a principal causa do comprometimento dessa performance.
A tecnologia de Banco de Dados Distribuídos (BDD) é uma das tecnologias
disponíveis no mercado que atende a tais características e prevê a organização de dados
em células com processamentos distintos, garantindo alta disponibilidade dos dados.
Banco de Dados Distribuídos, segundo Navathe (2005), pode ser definido como
uma coleção de múltiplos Bancos de Dados logicamente inter-relacionados e distribuídos
por uma rede de computadores, figura 1. O compartilhamento de dados é a principal
vantagem da criação de um Banco de Dados Distribuídos e a provisão de um ambiente
em que usuários de um site ou nodo podem ser capazes de acessar dados resididos em
outros sites, afirma SILBERSCHATZ (2006).
Figura 1 – Arquitetura de um banco de dados distribuído
Conforme o volume de dados distribuídos cresce, a necessidade de integração
entre essas diversas fontes aumenta, tornando importante o uso de técnicas de
Anuário da Produção de Iniciação Científica Discente Vol. 13, N. 20, Ano 2010 p. 329-336
Igor Fonseca Paixão, Teresinha Planez Diniz da Silva
331
gerenciamento de bancos de dados distribuídos para, virtualmente, formar um grande
banco de dados a partir de segmentos isolados ou independentes.
Atualmente, o crescimento de recursos para a disponibilidade de dados através
de meios de comunicação como a Internet contribui diretamente para o desenvolvimento
de banco de dados distribuídos.
A tecnologia dos bancos de dados distribuídos prevê a organização em células de
dados, com processamentos distintos garantindo a alta disponibilidade dos dados. A
replicação de dados vem garantir esse indicador, porém a otimização continua sendo um
elemento menosprezado.
O Banco de dados distribuídos (BDD) pode ser definido como uma coleção de
banco de dados logicamente inter-relacionados distribuídos por uma rede de computador
e que cooperam na execução de tarefas. A implantação de uma base de dados distribuída
oferece vantagens, sendo elas (NAVATHE, 2005).
Gerenciamento de dados distribuídos com níveis diferentes de
transparência.
Transparência de distribuição e de redes.
Transparência de fragmentação.
Melhoria de confiabilidade e disponibilidade.
Melhoria de desempenho.
O compartilhamento de dados é a principal vantagem da criação de um sistema
de banco de dados distribuídos é a provisão de um ambiente em que usuários de um site
podem ser capazes de acessar dados residindo em outros sites. (SILBERSCHATZ 2006).
Os bancos de dados distribuídos são constituídos de inúmeros centros de dados,
podendo a replicação ser realizada em cada centro. Nesse caso são categorizadas como
um espelhamento; ou parcial, onde apenas os índices são replicados.
Os Sistemas gerenciadores de Banco de dados Relacionais disponibilizam
ferramentas para o gerenciamento das ações que incorporam a replicação de dados. O
SQL Server 2005 implementa três tipos de replicações:
a) Snaptshot replicação - São programados intervalos de tempo para a
execução da replicação. Segundo Batisti (2001) não é indicado para
grandes volumes de dados; exige pouco processador.
b) Transactional Replication – A replicação ocorre somente nos dados alterados
no Publisher (unidade de replicação). A vantagem desse tipo informa
Batisti (2001) é a redução do tempo de latência e a possibilidade de manter
diversas bases de dados replica.
c) Merge Rerplication – São adicionados mecanismos de controles de modo
que alterações efetuadas em uma das réplicas são repassadas as demais.
Anuário da Produção de Iniciação Científica Discente Vol. 13, N. 20, Ano 2010 p. 329-336
332
Avaliação do indicador de desempenho de bancos de dados distribuídos com o uso de replicação de dados alocados em uma rede wireless
Watson (2004) afirma que um projeto de banco de dados distribuídos é
fundamentado nos princípios de fragmentação e replicação e pode-se implementar 4 tipos
de acesso aos dados, são eles: solicitação remota, transação remota, transação distribuída e
solicitação distribuída. A distribuição de dados é totalmente transparente ao usuário.
Replicação significa o armazenamento de várias cópias de uma relação ou
fragmento. Ramakrishnan (2008) afirma que os dados mantidos em células de
processamentos tornam a composição das informações mais velozes, considerando o
armazenamento de uma cópia local. Outra vantagem atribuída é a disponibilidade dos
dados, pois se uma réplica fica inativa pode-se encontrar um espelho em outra célula.
Este artigo esta organizado em seções: Introdução, objetivo, metodologia,
desenvolvimento, resultados e considerações finais.
2.
OBJETIVO
O presente projeto teve por objetivo aferir composições das informações em um banco de
dados distribuídos subsidiado em uma rede Wireless.
Para atender ao objetivo geral proposto, identificaram-se os seguintes objetivos
específicos:
3.
Modelar e implementar um banco de dados distribuídos e povoar com
dados fictícios.
Implementar mecanismo de replicação de base de dados em um banco de
dados distribuídos.
Aferir resultados do indicador eficiências considerando a implantação de
recursos de otimização.
METODOLOGIA
A estruturação do projeto foi organizada em etapas, sendo elas:
a) Definição do estudo de caso - A produção de um contexto que relata
necessidades da implantação de uma base de dados distribuídas. A partir
desse contexto será modelada a estrutura de armazenamento fazendo uso
dos princípios do modelo relacional e o desenvolvimento do diagrama de
caso de uso com o objetivo de definir a abrangência do sistema. Será
utilizado o SGBD (sistema Gerenciador de Banco de Dados) SQL Server
2005.
b) A população da base de dados será realizada a partir de procedimentos de
banco produzindo geração automática dos dados. Esses dados serão
produzidos de modo aleatórios.
c) Mapeamento (Topologia física e lógica) e implementação de uma rede
Anuário da Produção de Iniciação Científica Discente Vol. 13, N. 20, Ano 2010 p. 329-336
Igor Fonseca Paixão, Teresinha Planez Diniz da Silva
333
Wireless
d) Modelagem e implementação da composição das informações a partir da
linguagem SQL. Foi definido 10 expressões SQL, envolvendo funções
agregadas, subconsultas, procedimento de bancos (Inserção, exclusão,
alteração)
e) Implementação da Replicação da base dados
f) Aferição da performance da composição das informações efetivando
comparação com a implantação ou não, da replicação da base de dados. A
apresentação de resultados fará uso de ferramentas estatísticas. Será
comparado com e sem a utilização do mecanismo de replicação de base de
dados.
4.
DESENVOLVIMENTO
Foi projetada uma base de dados constituída de 6 tabelas inter-relacionadas, figura 2 e
implementada fazendo uso do sistema Gerenciador de Banco de Dados SQL Server versão
2005. Os dados fictícios foram inseridos, automaticamente, por intermédio da execução de
uma stored procedure, contemplando 20.000 registros na tabela Tb_ItensVenda.
Figura 2 – Modelo físico da base de dados
Após a inserção de registros, 10 procedimentos de bancos envolvendo as ações
de inserção, figura 3, alteração e exclusão foram projetadas, testadas e aferidas
considerando o indicador tempo de resposta ao usuário.
Figura 3 – Script do procedimento de inclusão de registro na base de dados
Anuário da Produção de Iniciação Científica Discente Vol. 13, N. 20, Ano 2010 p. 329-336
334
Avaliação do indicador de desempenho de bancos de dados distribuídos com o uso de replicação de dados alocados em uma rede wireless
Técnicas de replicação de base de dados foram aplicadas e novamente executadas
as operações, inicialmente a base de dados foi Startada em uma rede local e
posteriormente integrada com equipamentos de rede wireless.
Para a aferição do indicador tempo foi utilizado à ferramenta L Server Profiler,
SQL Server Management Studio presente na própria estrutura do SGBD, figura 3.
Figura 3 – Implementação da replicação transacional com o uso do assistente do SQL Server 2005
5.
RESULTADOS
A partir de um contexto que justifica o uso de um banco de dados distribuídos, a
modelagem da estrutura de armazenamento foi o primeiro resultado do projeto de
pesquisa. A ferramenta gráfica SQL Server Management Studio foi utilizada para o
desenho das tabelas do banco de dados e posteriormente a execução do script de criação
do banco, tabelas e povoamento dos dados. Para a implementação da estrutura física da
base distribuída, dois computadores com a mesma especificação física foram utilizados,
sendo da marca CCE, processador Core 2 duo T5800 2GHz, disco rígido de 250 GB,
memória de RAM 2 GB, sistema operacional 32 bits e uma rede com/sem fio de 5
megabits. Em uma das máquinas instalou-se o SQL Server 2005 Standart, que serviu de
servidor de Publicação na replicação e na outra o SQL Server 2005 Express, que serviu de
servidor de Assinatura.
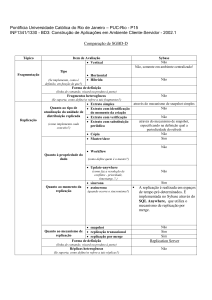
Com a estrutura física planejada, os testes iniciaram primeiramente na base de
dados com fio e sem replicação. Conforme é demonstrado no quadro 1 a operação de
inserção resultou em uma diferença de tempo de 103 milésimo de segundos.
Considerando a operação de alteração a diferença de tempo foi menor 134 milésimo de
segundos.
Anuário da Produção de Iniciação Científica Discente Vol. 13, N. 20, Ano 2010 p. 329-336
Igor Fonseca Paixão, Teresinha Planez Diniz da Silva
335
Quadro 1 – Resultados da performance (milissegundos) das ações de banco de dados em um rede local,
fazendo uso do recurso de replicação ou não
Sem replicação de
dados
Com replicação de
dados
Processo de Inserção (Um único registro)
53
156
Processo de Alteração (Um único registro)
64
134
Processo de deleção (Um único registro)
55
126
Operações de Banco de dados
Em seguida os testes foram executados na base de dados acessados a partir de
uma estrutura de rede wireless. A operação de inserção resultou em uma diferença de 96
milésimo de segundos, quadro 2.
Quadro 2 – Resultados da performance (milissegundos) das ações de banco de dados acessada a partir de
uma estação de rede sem fio , fazendo uso do recurso de replicação ou não
Sem Replicação
dados
Operações de Banco de dados
de
Com replicação de
dados
Processo de Inserção (Um único registro)
61
157
Processo de Alteração (Um único registro)
67
135
Processo de deleção (Um único registro)
60
125
A replicação de dados utilizada em ambos os testes foi a do tipo Transacional.
Com a execução de sentenças de atualização (update), inserção (insert) e exclusão (delete),
pôde-se aferir com o auxílio da ferramenta SQL Database Engine Tuning Advisor que os
resultados foram mais satisfatórios com a base de dados alocada em uma rede com fio
tanto com replicação quanto sem replicação. As diferenças, em milissegundos é
demonstrado no gráfico 1
Gráfico 1 – Diferenças em milissegundos da aplicação dos recursos de replicação de dados em uma rede
local e uma rede wireles
Anuário da Produção de Iniciação Científica Discente Vol. 13, N. 20, Ano 2010 p. 329-336
336
Avaliação do indicador de desempenho de bancos de dados distribuídos com o uso de replicação de dados alocados em uma rede wireless
6.
CONSIDERAÇÕES FINAIS
Em seu desfecho, este artigo conclui que sistemas distribuídos, juntamente a tecnologia de
redes remotas de computadores, representam uma alternativa válida para aumentar o
desempenho dos Sistemas de Banco de Dados em uma organização, resultando no
conseqüente alívio dos gastos com a infra-estrutura de redes de computadores cabeadas,
do processamento e da capacidade de armazenamento dos servidores.
O banco de dados distribuídos garante a concentração e integração da
informação, fazendo com que os dados estejam atualizados, disponíveis e com segurança
sempre que necessário, oferecendo também a possibilidade de crescimento modular
devido a uma necessidade repentina de expansão.
As técnicas apresentadas de replicação de dados que o SGBD SQL Server 2005
disponibiliza é aplicado para garantir a confiabilidade de funcionamento do sistema e a
disponibilidade de um site atualizado do sistema distribuído quando necessário.
Observa-se também que o SQL Server 2005 dispõe de inúmeras soluções
complexas para otimizar o servidor e suas consultas. Portanto, com estudos
fundamentados em conceitos de índices, estatísticas e nas ferramentas apresentadas, temse um grande ganho na otimização do banco de dados. Pois atualmente este é um grande
problema quando se diz em gargalos e performance de servidores de banco de dados.
Com a aplicação dos recursos de replicação de dados ocorre uma perda
insignificante no desempenho de resposta, independente do tipo de acesso aos dados,
porém o custo e benefício de resguardar a informação a aumentar a sua disponibilidade
justifica sua implantação.
REFERÊNCIAS
BATTISTI, Júlio. SQL Server 2005: Administração & Desenvolvimento, Curso completo. Rio de
Janeiro: Axcel Books do Brasil Editora, 2005.
NAVATHE, Elmasari. Sistema de Banco de dados 4º ed. Pearson – Addison Wesley. São Paulo.
2005.
O'BRIEN. James A. Sistema de Informação e as decisões gerenciais na era da Internet. 2º ed.
Saraiva. São Paulo. 2004.
RAMAKRISSHNAN, Raghu. Sistemas de gerenciamento de banco de dados. 3º Ed. São Paulo: MC
Graw Hill, 2008.
SILBERSCHATZ, Abraham. KORTH, Henry. Sistemas de banco de dados. Campus. Rio de Janeiro
2006.
WATSON, Richard. Data Management – Banco de dados e organizações. 3º Ed. LTC, Rio de
Janeiro, 2004
Anuário da Produção de Iniciação Científica Discente Vol. 13, N. 20, Ano 2010 p. 329-336