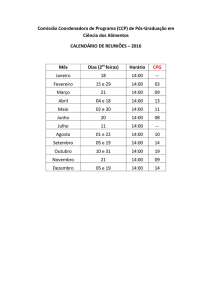
Disciplina de BIOLOGIA COMPUTACIONAL
Mestrado em ENGENHARIA BIOMÉDICA
4º Ano, 1º Semestre 2007/08
MODELOS PROBABILÍSTICOS
Relatório 4
Ana Calhau
54605
Ângela Pisco
55748
Nuno Santos
55746
Palavras-Chave: HMMs, Estados, Caminhos, Ilhas CpG, Algoritmo de Viterbi
Resumo Com este trabalho, pretendeu-se analisar a utilidade das HMMs na modelação de
problemas reais. Inicialmente, estudou-se o problema do “Fair Bet Casino”, pretendendo-se
saber quantos e quais os caminhos que podem gerar uma dada sequência, bem como a sua
probabilidade. De seguida, analisou-se o problema de identificação de ilhas CpG numa
longa sequência de DNA. Para resolver este problema construiu-se uma matriz de transição
para a HMM em estudo, que representa de forma unificada os modelos de Markov (+) e (-),
uma matriz de emissão e calculou-se ainda a probabilidade de uma dada sequência de
estados gerar uma dada sequência de C e G, bem como o caminho mais provável associado à
sequência pretendida, recorrendo-se ao algoritmo de Viterbi.
1. “FAIR BET CASINO”
O problema do “Fair Bet Casino” é bastante conhecido residindo o seu interesse na
analogia que se consegue estabelecer com o problema biológico da procura de ilhas CpG
numa sequência de DNA.
Um agente responsável por um jogo num casino tem duas moedas, possivelmente viciadas.
O agente começa o jogo sempre com a moeda m1 e em cada jogada muda de moeda, podendo
escolher ou a mesma moeda ou a outra, com uma determinada probabilidade. O jogador
apenas observa o resultado da jogada, isto é, só vê cara ou coroa, sem nunca saber qual das
moedas está ser utilizada.
Existem dois estados, S1 e S2, que correspondem a cada uma das moedas, e é possível
fazer duas observações: cara ou coroa. O sistema pode ter início, com igual probabilidade,
em qualquer um dos estados. Os restantes parâmetros correspondem à probabilidade de ver
cara no estado S1, p1, à probabilidade de ver cara no estado S2, p2, à probabilidade de
transição do estado S1 para o estado S2, q1, e à probabilidade de transição do estado S2 para o
S1, q2.
1.1.
Admitindo que no estado S1 apenas é possível observar cara, que no estado S2 apenas é
possível observar coroa e que a probabilidade de transição entre estados (ou ficar no
mesmo) é de 0,5, o Hidden Markov Model (HMM) que descreve esta situação é dado
por:
Pesquisa de Motivos
0.5
0.5
0.5
Não
Viciada
Viciada
1 – p2 = 1
0.5
p1 = 1
p2 = 0
1 – p1 = 0
Cara
Coroa
Cara
Coroa
Figura 1 HMM para o problema proposto.
1.2. Para uma dada sequência de caras e coroas de tamanho T (X1,T), existe apenas um
caminho, na HMM da alínea anterior, capaz de gerar a sequência X1,T, com
probabilidade diferente de zero (sai sempre cara ou coroa). O facto de o estado S1
apenas gerar caras e o estado S2 apenas gerar coroas faz com que a HMM anterior se
transforme num MM com estados não escondidos. Desta forma, se sair cara estamos
necessariamente no estado S1 e se sair coroa estamos necessariamente no estado S2,
pelo que a cada sequência de caras e coroas corresponde um e um só caminho.
1.3. Para se calcular a probabilidade de observar a sequência X1,T de acordo com a HMM da
alínea 1.1, há que ter em conta que há igual probabilidade de sair cara ou coroa para
cada um dos T lançamentos. Desta forma, a probabilidade vem dada por:
P(X1,T)= (1)
em que T é o tamanho da sequência X1,T.
1.4. Considerando agora que os estados S1 e S2 correspondem, respectivamente, a uma
moeda viciada e não viciada, que as probabilidades de ver cara e coroa são idênticas
para o estado S1 e iguais a 0,6 e 0,4 para o estado S2, e ainda que é possível transitar
entre estados com uma probabilidade q=0,3, a HMM e respectivos parâmetros que
descrevem esta situação são:
0.7
0.7
0.3
Não
Viciada
Viciada
1 – p1 = 0,5
Cara
1 – p2 = 0,4
0.3
p1 = 0,5
Coroa
p2 = 0,6
Cara
Coroa
Figura 2 HMM para o problema proposto.
2
Ana Calhau
Ângela Pisco
Nuno Santos
1.5. Os HMMs podem ser vistos como máquinas abstractas, com k estados escondidos que
emitem símbolos a partir de um alfabeto ∑. Cada um destes estados tem a sua própria
distribuição de probabilidade e a “máquina” vai mudando entre estados de acordo com
essa distribuição. Desta forma, considerando a sequência X = {1,1,0,0,0} em que {1,0}
= {Cara,Coroa}, através do método HMM, é possível determinar a sequência de estados
mais provável dessa sequência.
1
1
0
0
0
T–>
0.3
0.126
0.0353
0.0099
0.0028
B–>
0.6
0.21
b)
0.0882
0.6
0.4
0.0247
0.4
0.0069
0.4
a)
0.5
0.0028
0.0378
0.09
0.0106
0.0030
Início
Fim
0.075
0.5
0.0262
0.0092
0.0032
0.0038
a)
F–>
0.5
T–>
0.25
b)
0.175
0.5
0.0612
0.0875
0.5
0.0214
0.0306
0.5
0.0075
0.0107
0.5
0.0038
Figura 3 Diagrama que representa os vários passos para a obtenção da sequência de estados mais provável
sabendo a sequência X. Os valores a) e b) são 0,3 e 0,7, respectivamente, e são equivalentes em cada coluna do
diagrama. Às linhas B e F correspondem, respectivamente, os estados S2 e S1.
O diagrama anterior pode ser resumido numa tabela de programação dinâmica 2x5, tal
como evidenciado de seguida:
Tabela 1 Tabela de programação dinâmica 2x5 para o caso considerado, estando evidente a sequência de estados
mais provável
Begin 1
S1 0
S2 0
1
0
0,25
0,30
1
0
0,0875
0,1260
0
0
0,03063
0,03528
0
0
0,01072
0,00988
0
0
0,00375
0,00277
Pela análise da tabela e diagramas anteriores, torna-se evidente que a sequência de estados
mais provável é S={S1, S1, S1, S1, S1}.
2. IDENTIFICAÇÃO DE ILHAS CpG
2.1. As ilhas CpG são zonas do DNA que possuem elevado número de citosinas
imediatamente seguidas por guaninas.
Neste exercício, foram consideradas sequências de DNA humano, nas quais, segundo o
modelo de Markov considerado, foram identificadas 48 ilhas CpG.
Considerando que a probabilidade de se estar numa ilha CpG é equivalente à de se estar
fora dela, obtém-se a matriz com as probabilidades de transição, para uma HMM unificada
dos dois modelos utilizados no estudo:
3
Pesquisa de Motivos
Tabela 2 Matriz 8x8 onde estão evidenciadas as probabilidades de transição para uma HMM que representa de
forma unificada os modelos de Markov + e -.
A+
C+
G+
T+
ACGT-
A+
0.09
0.0855
0.0805
0.0395
0.125
0.125
0.125
0.125
C+
0.137
0.184
0.1695
0.1775
0.125
0.125
0.125
0.125
G+
0.213
0.137
0.1875
0.192
0.125
0.125
0.125
0.125
T+
0.06
0.094
0.0625
0.091
0.125
0.125
0.125
0.125
A0.125
0.125
0.125
0.125
0.15
0.161
0.124
0.0885
C0.125
0.125
0.125
0.125
0.1025
0.149
0.123
0.1195
G0.125
0.125
0.125
0.125
0.1425
0.039
0.149
0.146
T0.125
0.125
0.125
0.125
0.105
0.151
0.104
0.146
Pode-se dizer que a matriz obtida é constituída por quatro submatrizes. Uma vez que a
probabilidade de estar ou não numa ilha CpG é igual, a transição de um nucleótido + para
outro + será metade do que no modelo em que apenas se considera o estado + (ilha CpG). O
mesmo se passa para o modelo –. No caso de uma transição + para – ou vice-versa, a
probabilidade de um qualquer nucleótido transitar para outro será o produto de ¼ e ½, já que
existe uma equiprobabilidade entre os nucleótidos.
2.2.Para o caso que se pretende estudar, a sequência X é igual a X={C,G,C,G} e a matriz
dos caminhos p dada por p={C+,G-,C-,G+}.
O cálculo da probabilidade pedida pode ser feito de acordo com a equação abaixo
(2)
Simplificando (2) vem
(3)
Desenvolvendo (3) fica-se com
! ! " ! # (4)
Para se ficar com o resultado independente de parâmetros não fornecidos pela tabela
anterior assumiram-se duas condições. Dado que a probabilidade de estar numa ilha CpG é
igual à de estar fora, então a probabilidade de ir do estado begin para qualquer um dos estados
pode ser considerada igual, o que corresponde a ter-se em valor numérico $%&'(.
Por outro lado, quando se está no último estado do caminho, e apenas por simplificação,
admitiu-se que a probabilidade de ir do último estado para o estado end é a mesma,
independentemente do estado em que se esteja, e vale 1 (! # &).
De acordo com o enunciado, a matriz de emissão é dada pela tabela abaixo:
Tabela 3 Matriz de emissão da HMM.
A+
C+
G+
T+
ACGT-
A+
1
0
0
0
1
0
0
0
C+
0
1
0
0
0
1
0
0
G+
0
0
1
0
0
0
1
0
T+
0
0
0
1
0
0
0
1
A1
0
0
0
1
0
0
0
C0
1
0
0
0
1
0
0
G0
0
1
0
0
0
1
0
T0
0
0
1
0
0
0
1
4
Ana Calhau
Ângela Pisco
Nuno Santos
Substituindo as variáveis em (4) pelos valores dados pelas tabelas 2 e 3, a probabilidade
pedida vale
$%&'( & $%&'( & $%&') & $%&'( & '%* &$+"
2.3.Algoritmo de Viterbi e cálculo do caminho mais provável
O Algoritmo de Viterbi é utilizado para encontrar a sequência de estados que gera, com
maior probabilidade, a sequência observada, isto é, identifica qual o caminho mais provável,
para a HMM em causa.
Este algoritmo pode ser definido da seguinte forma
&////0 123457
$////0 6 12345
8 9-:; <,-% = -8 >% ? $% @ % A B &//C : D
,-% .
,8%
(5)
Sendo p* o caminho óptimo, tem-se que
E 9-:; <,-% = -%FGH >
(6)
Para este caso concreto não é necessário considerar todos os estados possíveis, já que de
acordo com a matriz de emissão apenas são relevantes os estados C e G (tanto em ilha CpG,
como fora), dado que todos os outros têm probabilidade nula para a sequência em causa.
Com base em (5) e (6) e no parágrafo anterior, construiu-se a seguinte tabela:
Tabela 4 Tabela de programação dinâmica 4x4 para o caso considerado, estando evidente a sequência de estados
mais provável.
C
G
C
G
0
0
0
0,002903
0
Begin
1
C+
0
0
0,125
G+
0
0
0,017125
0
0,000397668
C-
0
0,125
0
0,002141
0
G-
0
0
0,015625
0
0,000362836
0
O caminho mais provável é, portanto, {C+, G+, C+, G+}.
3. CONCLUSÃO
Ao longo deste trabalho foi possível tomar conhecimento de todas as potencialidades dos
modelos de Markov. Estes modelos, na sua versão geral, não apresentam uma
correspondência biunívoca entre estados e símbolos, já que pode existir mais do que um
estado que emita o mesmo símbolo. Isto leva a que exista mais do que um caminho com a
capacidade de gerar uma dada sequência.
A pesquisa de ilhas CpG é um problema importante na medida em que encontrar ilhas CpG
corresponde a encontrar, em grande parte dos casos, regiões promotoras de genes. O par CG
está tipicamente sub-representado num genoma, porque o nucleótido C é facilmente metilado,
tendo posteriormente tendência a mutar para T. No entanto, a metilação é suprimida nas zonas
5
Pesquisa de Motivos
envolventes dos genes, razão pela qual existe um maior número de CG nestas regiões.
No último ponto do primeiro exercício, o resultado obtido está de acordo com o esperado,
pois existe um maior número de coroas do que caras na sequência, e o estado S1 emite
coroas com maior probabilidade do que S2.
O mesmo se verifica na última alínea do segundo exercício, em que o modelo admite que
se está numa ilha CpG. As sequências são, no entanto, pequenas para que se possam
extrapolar conclusões.
Em termos globais, a realização deste trabalho foi bastante útil para entender o
funcionamento dos HMMs. Apesar da sua natureza heurística, considera-se que os resultados
conseguidos com estes modelos são bastante bons.
4. BIBLIOGRAFIA
[1] Freitas, Ana T., Modelos Probabilísticos, Guia do 4º Laboratório de Biologia
Computacional, Novembro de 2007
[2] Freitas, Ana T., Apontamentos das aulas teóricas de Biologia Computacional, 2007
[3] An Introduction to Bioinformatics Algorithms , N. C. Jones and P. Pevzner, 2005, MIT
Press
[4] Biological Sequence Analysis - Probabilistic models of proteins and , R. Durbin, S.
Eddy, A. Krogh, G. Mitchison, 1998, Cambridge
6