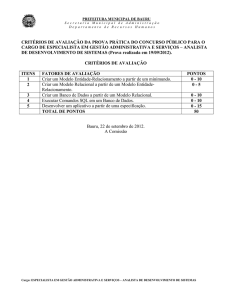
NoSql Uma Alternativa ao Tradicional Modelo Relacional
Wesley José dos Santos1 , Tiago Piperno Bonetti1
1
Universidade Paranaense (Unipar)
Paranavaı́ – PR – Brasil
[email protected], [email protected]
Resumo. Este artigo descreve a utilização de bancos de dados não relacionais
frente as limitações do modelo relacional. Tendo como objetivo demonstrar as
diferenças, vantagens e desvantagens na utilização de bancos de dados NoSql,
apresentando sua estrutura diferenciada e a liberdade oferecida por ele se comparado a certas regras rigorosas presentes no modelo relacional. Foi utilizado o
banco de dados não relacional MongoDb, para a manipulação do banco, averiguando as principais caraterı́sticas e vantagens trazidas pelo NoSql, como por
exemplo, sua capacidade de ser um banco de dados sem estrutura pré-definida
e sua falta de Schema. Como resultado pode-se perceber a facilidade e flexibilidade trazida pelo NoSql, na maneira em como tratar os dados de forma simples
e ágil, mostrando-se um banco de dados que realmente consegue resolver certos
problemas presentes no modelo relacional.
1. Introdução
O grande crescimento do volume de dados e informações na web, vem se alastrando de
maneira perceptı́vel no nosso dia a dia, um grande exemplo disso são as redes sociais
como o Facebook, que utilizam grandes servidores para armazenar seus dados.
Levando em consideração o grande aumento que tem ocorrido no volume de
informações que devem ser processadas e armazenadas diariamente, o tradicional modelo
relacional vem sofrendo graves problemas em conseguir manter uma boa performance no
banco de dados. De acordo com Tiwari (2011), ao lidarmos com grandes volumes de dados utilizando o modelo relacional teremos alguns problemas em relação ao desempenho,
diminuindo a interação do banco com o usuário, pois o modelo relacional deixa muito a
desejar na questão da escalabilidade, e devido a isso e outros fatores cresce a necessidade
de bancos de dados alternativos que possam solucionar tais problemas.
Portanto, o objetivo deste trabalho é demonstrar as vantagens trazidas pela
utilização de bancos de dados NoSql, frente a certas limitações presentes no modelo relacional e demonstrar também que as melhorias presentes no NoSql não estão contidas
apenas em ganho de desempenho, mas em sua maneira em como tratar os dados oferecendo mais facilidade e flexibilidade.
Para que seja possı́vel demonstrar as caracterı́sticas do NoSql, foi proposto para a
realização do trabalho a manipulação do banco de dados não relacional MongoDB, para
que seja possı́vel averiguar as diferenças e vantagens presentes no NoSql, se comparado
a algumas normas presentes no modelo relacional que acabam dificultando a maneira em
como lidar com os dados.
O NoSql (Not Only Sql), vem para resolver diversos problemas presentes no modelo relacional, não somente em conseguir lidar com enormes volumes de dados garan-
tindo a performance e disponibilidade dos dados no banco, mas também vem para facilitar
a maneira em como lidar com tais dados e garantir uma maior liberdade na maneira em
como tratá-los, não fazendo uso de certas regras rigorosas presentes no modelo relacional
[Tiwari 2011].
2. Metodologia
Para a realização deste trabalho foi realizada uma revisão bibliográfica utilizando livros,
artigos e sites da internet. Através da revisão bibliográfica foi possı́vel a realização da
manipulação do banco de dados não relacional MongoDB, para que fosse possı́vel demonstrar suas principais diferenças e vantagens se comparado ao modelo relacional.
3. Modelo Relacional
O modelo de banco de dados relacional foi criado por Edgar Frank Codd em 1970,
tornando-se o sucessor do modelo hierárquico e do modelo rede, tendo como princı́pio
de que todas as informações são guardadas em tabelas, tornando-se assim um padrão a
ser utilizado por várias aplicações comercias e empresariais, devido a sua simplicidade e
performance.
Elmasri e Navathe (2010), definem os bancos de dados relacionais como um conjunto de dados que se relacionam entre si. Tratando as informações de maneira mais
detalhada, temos que entender que esses dados precisam possuir algum sentido, fazendo
uma representação do mundo como ele é.
Um dos principais motivos para a criação do modelo relacional está ligado aos
problemas encontrados em seus antecessores, como a duplicidade, redundância e inconsistências dos dados, além dos graves problemas dos bancos de dados hierárquicos e de
redes em conseguir administrar o controle de concorrência dos dados, ou seja, quando
dois ou mais usuários tentam acessar o mesmo dado durante uma transação, o banco
deve fazer com que uma transação não atrapalhe a outra fazendo com que os dados não
se tornem inconsistentes, pois se por acaso houver algum problema durante o processo
da transação a mesma deve ser desfeita fazendo com que o banco retorne ao seu estado
normal antes do inı́cio da transação [Rodrigues, 2001].
Segundo Sadalage e Fowler (2012), através do surgimento dos bancos de dados relacionais foi possı́vel uma maior abstração, organização e independência dos dados, tornando muito melhor até a forma em como desenvolver aplicações, já que toda a
administração e persistência dos dados é feito através dos SGBDS (Sistemas Administradores de Bancos de Dados), que acabam por conceder uma maior facilidade e flexibilidade
para usuários em manipular os dados e as transações.
Apesar de atualmente o modelo relacional não estar conseguindo gerenciar grandes volumes de dados, tendo problemas em garantir uma boa escalabilidade e performance
do banco, ele foi e ainda é uma ferramenta de grande importância em diversas empresas
espalhadas pelo mundo, por ser um modelo de dados fácil de controlar e manter além de
sua ótima capacidade de evitar que os dados fiquem inconsistentes e realizando da melhor
maneira possı́vel o controle de suas transações.
3.1. Limitações do Modelo Relacional
Segundo Leavitt (2010), por muitos anos o modelo relacional vem sendo utilizado como
padrão na persistência de dados de várias empresas. Porém, com o grande aumento da
quantidade de informações e com a certeza de que essa quantidade só tende a ficar cada
vez maior, o modelo relacional vem sofrendo grandes problemas em relação a escalabilidade e desempenho.
Mesmo com as várias vantagens disponibilizadas pelo modelo relacional ele não
consegue manter o banco de dados disponı́vel e funcional com uma boa performance
quando o assunto é processar grandes volumes de informações, o que acaba fazendo que
grandes organizações, como por exemplo, o Facebook e o Twitter, acabem precisando recorrer a maneiras alternativas de lidar com esse grande crescimento diário de informações.
Apesar das muitas vantagens obtidas através da utilização dos SGBDs do modelo relacional, em cenários aos quais é preciso armazenar e processar um número muito
grande de informações, de modo a conseguir conciliar esta grande quantidade de dados
com uma demanda cada vez maior por escalabilidade, a utilização do modelo relacional
acaba não se tornando uma alternativa muito viável.
Segundo Brito (2010), devido à natureza estruturada do modelo relacional, a estrutura dos dados que compõem o banco é predefinida pelo esboço das tabelas, como nomes,
tipos de dados e colunas. Começou-se então a notar certos problemas no gerenciamento
e organização de grandes volumes de informações no modelo relacional em sistemas que
trabalham de maneira a particionar os dados nesse tipo de banco.
4. NoSql
O termo NoSql (Not Only Sql), foi utilizado pela primeira vez em 1998 por Carlo Strozzi
como sendo o nome de um banco de dados relacional de código aberto que não possui uma
interface SQL. Segundo Tiwari (2011), o significado do termo NoSql está relacionado
aos tipos de bancos de dados que precisam lidar diariamente com um grande volume de
dados que são acessados e manipuladas através da internet, e que não seguem o tradicional
modelo relacional para persistir os dados.
O motivo para o surgimento dos bancos de dados NoSql está ligado com a necessidade de um banco de dados que conseguisse lidar com o aumento do grande volume de
informações, de maneira a oferecer uma melhor escalabilidade, performance superior e a
garantia de que os dados sempre estejam disponı́veis para acesso, pois nesses requisitos
os tradicionais modelos de bancos de dados relacionais deixam muito a desejar, levando
isso em consideração diversas empresas que utilizam o modelo relacional são obrigadas a utilizarem a técnica de escalabilidade vertical, que consiste na aquisição de mais
memória, discos rı́gidos e servidores mais potentes para atender o aumento do volume de
informações, porém essa técnica não é aconselhável devido ao seu alto custo e dificuldade
de implementação [Sadalage e Fowler 2012].
O NoSql oferece uma grande facilidade em escalar bancos de dados distribuı́dos
de maneira horizontal, ou seja, quanto mais dados, mais servidores, porém não necessariamente servidores de grande porte, pois através de sua alta capacidade de garantir uma
boa escalabilidade ele consegue lidar com dados estruturados, replicação, sub-colunas e
consegue garantir uma ótima performance lidando com grandes volumes de dados, além
de possuir uma enorme tolerância a erros.
Uma caracterı́stica de grande importância trazida pelo NoSql e que ilustra perfeitamente a grande facilidade e flexibilidade trazida por esse tipo de banco de dados,
deixando de lado certas regras rigorosas do modelo relacional é chamada de Schemals
que traduzido seria algo como sem esquema ou esquema flexı́vel. Essa caracterı́stica está
ligada com um fator de grande diferença em relação ao modelo relacional, pois significa a
ausência completa ou quase completa da estrutura que define os dados [Sadalage e Fowler
2012]. Através da ausência do esquema em bancos de dados NoSQl, é possı́vel garantir
mais facilidade em lidar com a escalabilidade em grandes volumes de dados e contribui
também para o aumento da disponibilidade. Já que bancos de dados NoSql, não possuem
uma estrutura de dados pré-definida, não é preciso definir o tipo de dado a ser armazenado
na criação do banco, isso é feito dinamicamente a medida em que os dados são inseridos
no banco.
Levando em consideração o que foi dito sobre as limitações presentes no modelo relacional e como os bancos de dados NoSql vem para resolver da melhor maneira
possı́vel tais limitações e problemas, fica evidente os motivos pelos quais eles acabam se
mostrando tão promissores e vem ganhando cada vez mais espaço nas grandes empresas
que precisam de maneiras alternativas em tratar seus dados, garantindo que seus sistemas
possam ser escalados da melhor forma possı́vel sempre que necessário.
5. Estudo de Caso
Foi proposto para a realização do projeto fazer a manipulação de um banco de dados
NoSql, para que se possa averiguar sua estrutura de código diferenciada se comparado
a tradicional linguagem SQL e identificar suas principais diferenças se comparado ao
modelo relacional.
Para a realização da manipulação do banco de dados NoSql foi utilizado o banco
de dados MongoDB, em sua versão 3.2.6, sendo totalmente OpenSource. Durante a
manipulação do banco de dados pode-se notar primeiramente sua estrutura de código que
se apresenta totalmente diferente do já conhecido SQL, porém mesmo ele se mostrando
bem diferente, a estrutura de códigos presentes no MongoDB se mostra muito simples e
fácil de utilizar, podendo-se afirmar até que ele seja mais fácil do que o tradicional SQL,
pois tanto sua leitura e escrita de códigos é simples de ser entendida, além de apresentar
uma diminuição considerável das linhas de códigos se comparado ao SQL.
Durante a criação de um banco de dados utilizando o MongoDB pode-se perceber
sua flexibilidade na maneira em como tratar os dados, o que facilita muito o processo de
aprendizagem para iniciantes. Tal flexibilidade é vista logo no inı́cio da criação do banco,
pois durante o processo de criação não é preciso definir o tipo de dado que será inserido no
banco, por exemplo, caso o usuário queira criar uma tabela de clientes no banco ele deve
informar que o nome desse cliente é do tipo VARCHAR, e ele também deve informar a
quantidade de caracteres do nome do cliente, já no caso de bancos de dados NoSql isso
não precisa ser feito, pois esse tipo de banco de dados não possui uma estrutura de dados
pré-definida, isso é feito dinamicamente pelo banco a medida que os dados são inseridos.
Uma caracterı́stica muito importante que diferencia muito os bancos de dados
relacionais e o NoSQL é a questão da falta de esquema presente nos bancos de dados
NoSql, ou seja, os documentos que estão dentro de uma coleção podem ter formatos
diferentes uns dos outros, como é representado na Figura 1, onde ambos os documentos
podem normalmente fazer parte da mesma coleção.
Figura 1. Representação da falta de esquema em bancos de dados NoSql.
6. Considerações finais
Este artigo abordou a utilização de um banco de dados não relacional para demonstrar
algumas de suas caracterı́sticas que o diferenciam e trazem uma melhor forma em como
persistir os dados se comparado ao modelo relacional.
Durante a manipulação do banco de dados NoSql MongoDB, pode-se perceber o
quanto modelos não relacionais são fáceis de serem utilizados e o quanto ele é flexı́vel em
sua maneira de tratar os dados deixando de lado certas regras rigorosas presentes no modelo relacional, o que acaba facilitando o processo de tratamento de grandes quantidades
de dados oferecendo maneiras mais ágeis de garantir uma boa escalabilidade sempre que
for necessário.
Pode-se notar também uma diminuição das linhas de códigos contidas no NoSql,
em relação ao modelo relacional, mesmo em códigos que tenham a mesma função o
NoSql consegue uma boa diminuição dessas linhas o que facilita o processo de aprendizado e desenvolvimento.
O que se pode concluir sobre a utilização de bancos de dados NoSql é que suas
funcionalidades e vantagens não estão contidas apenas no ganho de performance e sua
capacidade de lidar com grandes volumes de dados, mas também em sua maneira de
como tratar esses dados proporcionando mais liberdade e flexibilidade.
Referências
Brito, R. W. (2010). Bancos de dados nosql x sgbds relacionais:análise comparativa.
Universidade de Fortaleza.
Elmasri and Navathe (2010). Sistemas de banco de dados. 3. ed. Pearson Education - Br,
São Paulo.
Leavitt (2010). Will NoSQL Databases Live Up to Their Promise?
Society.
IEEE Computer
Sadalage, P. and Fowler, M. (2012). NoSQL Distilled:. ed. Pearson Education Inc., Nova
Jersey.
Tiwari, S. (2011). Professional NoSQL. ed. John Wiley Sons, Inc., Crosspoint Boulevard,
Indianapolis.