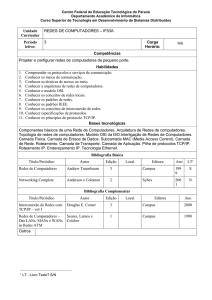
Mapa Mental de Arquitetura e
Organização de Computadores –
Hardware
Mapa Mental de Arquitetura e Organização de Computadores –
Hardware
Mapa Mental de Arquitetura e Organização de Computadores –
Hardware
Mapa Mental de Arquitetura e
Organização de Computadores –
Barramentos
Mapa Mental de Arquitetura e Organização de Computadores –
Barramentos
Mapa Mental de Arquitetura e Organização de Computadores –
Barramentos
Arquitetura: Von Neumann Vs
Harvard
A Arquitetura de von Neumann (de John von Neumann), é uma
arquitetura de computador que se caracteriza pela
possibilidade de uma máquina digital armazenar seus programas
no mesmo espaço de memória que os dados, podendo assim
manipular tais programas.
A máquina proposta por Von Neumann reúne os seguintes
componentes: (i) uma memória, (ii) uma unidade aritmética e
lógica (ALU), (iii) uma unidade central de processamento
(CPU), composta por diversos registradores, e (iv) uma Unidade
de Controle (CU), cuja função é a mesma da tabela de controle
da Máquina de Turing universal: buscar um programa na memória,
instrução por instrução, e executá-lo sobre os dados de
entrada.
Cada um dos elementos apresentados é realizado à custa de
componentes físicos independentes, cuja implementação tem
variado ao longo do tempo, consoante a evolução das
tecnologias de fabricação, desde os relés electromagnéticos,
os tubos de vácuo (ou válvulas), até aos semicondutores,
abrangendo os transistores e os circuitos electrónicos
integrados, com média, alta ou muito alta densidade de
integração (MSI – medium scale, LSI – large scale, ou VLSI –
very large scale integration), medida em termos de milhões
transistores por pastilha de silício.
As interacções entre os elementos exibem tempos típicos que
também têm variado ao longo do tempo, consoante as tecnologias
de fabricação. Actualmente, as CPUs processam instruções sob
controlo de relógios cujos períodos típicos são da ordem de 1
nanosegundo, ou seja, 10 ? 9 segundos. As memórias centrais
têm tempos típicos de acesso da ordem da dezena de
nanosegundos. As unidades de entrada e saída exibem tempos
típicos extremamente variáveis, mas que são tipicamente muito
superiores à escala do nanosegundo. Por exemplo, os discos
duros exibem tempos da ordem do milisegundos (milésimo de
segundo, 10 ? 3). Outros dispositivos periféricos são inertes,
a não ser que sejam activados por utilizadores humanos. Por
exemplo, ao se fazer “copy and paste” nao se-percebe nada do
que foi descrito acima, pois um teclado só envia informação
para o computador após serem pressionada as devidas teclas.
Assim, este dispositivo se comunica com a CPU eventualmente e,
portanto, exibe tempos indeterminados.
A Arquitetura de Harvard baseia-se em um conceito mais recente
que a de Von-Neumann, tendo vindo da necessidade de por o
microcontrolador para trabalhar mais rápido. É uma arquitetura
de computador que se distingue das outras por possuir duas
memórias diferentes e independentes em termos de barramento e
ligação ao processador.
Baseia-se na separação de barramentos de dados das memórias
onde estão as instruções de programa e das memórias de dados,
permitindo que um processador possa acessar as duas
simultaneamente, obtendo um desempenho melhor do que a da
Arquitetura de von Neumann, pois pode buscar uma nova
instrução enquanto executa outra.
A principal vantagem desta arquitectura é dada pela dupla
ligação às memórias de dados e programa (código), permitindo
assim que o processador leia uma instrução ao mesmo tempo que
faz um acesso à memória de dados.
A arquitetura Havard também possui um repertório com menos
instruções que a de Von-Neumann, e essas são executadas apenas
num único ciclo de relógio.
Os microcontroladores com arquitetura Havard são também
conhecidos como “microcontroladores RISC” (Computador com
Conjunto Reduzido de Instruções), e os microcontroladores com
uma arquitetura Von-Neumann, de “microcontroladores CISC”
(Computador com um Conjunto Complexo de Instruções).
A diferença entre a arquitetura Von Neunmann e a Harvard é que
a última separa o armazenamento e o comportamento das
instruções do CPU e os dados, enquanto a anterior utiliza o
mesmo espaço de memória para ambos. Nos CPUs atuais, é mais
comum encontrar a arquitetura Von Neunmann, mas algumas coisas
da arquitetura Harvard também são vistas.
Nessas distintas arquiteturas, temos vantagens e desvantagens,
como pode-se observar a seguir: Arquitetura tipo Harvard:
Caminhos de dados e de instrução distintos, dessa forma, seus
componentes internos têm a seguinte disposição.
Já na arquitetura Von-Neumann, é processada uma única
informação por vez, visto que nessa tecnologia, execução e
dados percorrem o mesmo barramento, o que torna o processo
lento em relação à arquitetura Harvard.
Essa
é
a
tecnologia
mais
utilizada
nos
PC’s
e
microcontroladores, pois proporcionam maior velocidade de
processamento, pois enquanto a CPU processa uma informação,
outra nova informação está sendo buscada, de forma sucessiva.
Equipamentos que utilizam a arquitetura Harvard:
Os PIC (PICmicro) são uma família de microcontroladores
fabricados pela Microchip Technology, que processam dados de 8
bits e de 16 bits, mais recentemente 32, com extensa variedade
de modelos e periféricos internos, com arquitetura Harvard e
conjunto de instruções RISC (conjuntos de 35 instruções e de
76 instruções), com recursos de programação por Memória flash,
EEPROM e OTP. Os microcontroladores PIC têm famílias com
núcleos de processamento de 12 bits, 14 bits e 16 bits e
trabalham em velocidades de 0kHz (ou DC) a 48MHz, usando ciclo
de instrução mínimo de 4 períodos de clock, o que permite uma
velocidade de no máximo 10 MIPS. Há o reconhecimento de
interrupções tanto externas como de periféricos internos.
Funcionam com tensões de alimentação de 2 a 6V e os modelos
possuem encapsulamento de 6 a 100 pinos em diversos formatos
(SOT23, DIP, SOIC, TQFP, etc)
Fonte: http://sistemasuniban.blogspot.com.br/2010/04/arquiteru
ra-von-neumann-vs-harvard.html
Arquitetura de processadores:
RISC e CISC
A arquitetura de processador descreve o processador que foi
usado em um computador. Grande parte dos computadores vêm com
identificação e literatura descrevendo o processador que
contém dentro de si, arquitetura CISC e RISC.
A CISC (em inglês: Complex Instruction Set Computing,
Computador com um Conjunto Complexo de Instruções), usada em
processadores Intel e AMD; suporta mais instruções no entanto,
com isso, mais lenta fica a execução delas.
A RISC (em inglês: Reduced Instruction Set Computing,
Computador com um Conjunto Reduzido de Instruções) usada em
processadores PowerPC (da Apple, Motorola e IBM) e SPARC
(SUN); suporta menos instruções, e com isso executa com mais
rapidez o conjunto de instruções que são combinadas.
É indiscutível, porém, que em instruções complexas os
processadores CISC saem-se melhor. Por isso, ao invés da
vitória de uma das duas tecnologias, atualmente vemos
processadores híbridos, que são essencialmente processadores
CISC, mas incorporam muitos recursos encontrados nos
processadores RISC (ou vice-versa).
Nos chips atuais, que são na verdade misturas das duas
arquiteturas, juntamos as duas coisas. Internamente, o
processador processa apenas instruções simples. Estas
instruções internas, variam de processador para processador,
são como uma luva, que se adapta ao projeto do chip. As
instruções internas de um K6 são diferentes das de um Pentium
por exemplo. Sobre estas instruções internas, temos um
circuito decodificador, que converte as instruções complexas
utilizadas pelos programas em várias instruções simples que
podem ser entendidas pelo processador. Estas instruções
complexas sim, são iguais em todos os processadores usados em
micros PC. é isso que permite que um Athlon e um Pentium III
sejam compatíveis entre sí.??O conjunto básico de instruções
usadas em micros PC é chamado de conjunto x86. Este conjunto é
composto por um total de 187 instruções, que são as utilizadas
por todos os programas. Além deste conjunto principal, alguns
processadores trazem também instruções alternativas, que
permitem aos programas executar algumas tarefas mais
rapidamente do que seria possível usando as instruções x86
padrão. Alguns exemplos de conjuntos alternativos de
instruções são o MMX (usado apartir do Pentium MMX), o 3D-NOW!
(usado pelos processadores da AMD, apartir do K6-2), e o SSE
(suportado pelo Pentium III).
Agora vamos analisar cada uma delas com um pouco mais
detalhadamente.
CISC
Examinando de um ponto de vista um pouco mais prático, a
vantagem de uma arquitetura CISC é que já temos muitas das
instruções guardadas no próprio processador, o que facilita o
trabalho dos programadores, que já dispõe de praticamente
todas as instruções que serão usadas em seus programas. Os
processadores CISC têm a vantagem de reduzir o tamanho
do código executável por já possuirem muito do código comum em
vários programas, em forma de uma única instrução.
Os processadores baseados na computação de conjunto de
instruções complexas contêm uma microprogramação, ou seja, um
conjunto de códigos de instruções que são gravados no
processador, permitindo-lhe receber as instruções dos
programas e executá-las, utilizando as instruções contidas na
sua microprogramação. Seria como quebrar estas instruções, já
em baixo nível, em diversas instruções mais próximas do
hardware (as instruções contidas no microcódigo do
processador). Como característica marcante esta arquitetura
contém um conjunto grande de instruções, a maioria deles em um
elevado grau de complexidade.
A CISC é implementada e guardada em micro-código no
processador, sendo difícil modificar a lógica de tratamento de
instruções. Esta arquitetura suporta operações do tipo “a=a+b”
descrita por “add a,b”, ou seja podem simplesmente
utilizar dois operandos para uma única instrução, sendo um
deles fonte e destino (acumulador) e permite um ou mais
operadores em memória para a realização das instruções. Com
isto se comprova a necessidade de abranger um elevado leque de
modelos de endereçamento, com acesso direto à memória e com
apontadores para as variáveis em memória, armazenados eles
próprios (ponteiros) em células de memória.
Porém, do ponto de vista da performance, os CISC’s têm algumas
desvantagens em relação aos RISC’s, entre elas a
impossibilidade de se alterar alguma instrução compostapara se
melhorar a performance. O código equivalente às
instruções compostas do CISC pode ser escrito nos RISC’s da
forma desejada, usando um conjunto de instruções simples, da
maneira que mais se adequar. Sendo assim, existe uma disputa
entre tamanho do código X desempenho.
RISC
No caso de um chip estritamente RISC, o programador já teria
um pouco mais de trabalho, pois como disporia apenas de
instruções simples, teria sempre que combinar várias
instruções sempre que precisasse executar alguma tarefa mais
complexa.
Os processadores baseados na computação de conjunto de
instruções reduzido não têm micro-programação, as instruções
são executadas diretamente pelo hardware. Como característica,
esta arquitetura, além de não ter microcódigo, tem o conjunto
de instruções reduzido, bem como baixo nível de complexidade.
A ideia foi inspirada pela descoberta de que muitas das
características incluídas na arquitetura tradicional de
processadores para ganho de desempenho foram ignoradas pelos
programas que foram executados neles. Mas o desempenho do
processador em relação à memória que ele acessava era
crescente. Isto resultou num número de técnicas para
otimização do processo dentro do processador, enquanto ao
mesmo tempo tentando reduzir o número total de acessos à
memória.
RISC é também a arquitetura adotada para os processadores dos
videogames modernos, que proporcionam um hardware extremamente
dedicado somente à execução do jogo, tornando-o muito mais
rápido em relação a micro computadores com mais recursos,
embora com processador x86.
Pode-se concluir que os projetistas de arquiteturas CISC
consideram três aspectos básicos: – uso de microcódigo; –
construção de conjuntos com instruções completas e eficientes
(completeza no conjunto); – criação de instruções de máquina
de “alto nível”, ou seja, com complexidade semelhante à dos
comandos de alto nível.
Colocados juntos, esses elementos do projeto nortearam a
filosofia de construção de processadores CISC por longo tempo,
como a família Intel x86, os processadores AMD K e,
anteriormente, os sistemas IBM e VAX. Assim é que existem
naqueles conjuntos instruções poderosas, do tipo:
CAS – compare and swap operands (comparar valores e
trocas operandos)
RTR – return and restore codes (retornar e restaurar
código)
SWAP – swap register words (trocar palavras dos
registradores)
Menor quantidade de instruções: talvez a característica mais
marcante das arquiteturas RISC, seja a de possuir um conjunto
de instruções menor(todas também com largura fixa), que as
máquinas que possuíam a arquitetura CISC, porém com a mesma
capacidade. Vem daí o nome dado a arquitetura RISC
(computadores com um conjunto reduzido de instruções). A
SPARC, da Sun, possuía um conjunto de cerca de 50 instruções,
a VAX-11/780 tinha até 300 instruções, o Intel 80486 foi
apresentado com 200 instruções e os Pentium possuem mais de
200 instruções.
Com o conjunto de instruções reduzido e cada uma delas tendo
suas funções otimizadas, os sistemas possuíam um resultado
melhor em questão de desempenho. Em virtude do conjunto
reduzido das instruções, acarretavam em programas um pouco
mais longos.
Execução otimizada de chamadas de função: outra evolução da
arquitetura RISC para a arquitetura CISC tem relação com a
chamada de retinas e passagem de parâmetros. Estudos indicam
que as chamadas de funções consomem um tempo significativo de
processador. Elas requerem poucos dados, mas demoram muito
tempo nos acessos a memória.
Em virtude disso, na arquitetura RISC foram utilizados mais
registradores. As chamadas de função que na arquitetura CISC
ocorriam com acessos a memória, mas na RISC isso era feito
dentro do processador mesmo, utilizando os registradores que
foram colocados a mais.
Modo de execução com Pipelining: uma das características mais
relevantes da arquitetura RISC é o uso de pipelining, mesmo
sabendo que ela tem um funcionamento mais efetivo quando as
instruções são todas bastante parecidas.
Imaginando estágios de uma linha de montagem, não é
interessantes que um estágio termine antes do outro, pois
nesse caso perde-se a vantagem da linha de montagem. O
objetivo de cada instrução, é completar um estágio de pipeline
em um ciclo de clock, mas esse objetivo nem sempre é
alcançado.
O processamento de uma instrução é composto pelo menos por
cinco fases:
Instruction fetch;
Instruction decode;
Operand fetch;
Execution;
Write back.
Hoje em dia o pipeline não se limita a apenas 5 estágios, mas
pode chegar a 20 ou 30 estágios (Intel Pentium 4). No entanto,
para que todo o processo funcione é necessário que
determinadas restrições se verifiquem. A prioridade é que
todas as instruções permaneçam em cada estágio o mesmo tempo,
para que:
O sinal de relógio seja usado
processamento;
Não sejam necessários “buffers”;
como
cadência
de
Execução de cada instrução em um ciclo de clock: se o uso do
pipelining se considera uma característica importante da
arquitetura RISC, a execução de uma instrução por ciclo de
clock é mais importante, segundo os que estabeleceram suas
bases. Um dos pontos mais negativos das arquiteturas RISC é o
longo tempo de execução de cada instrução. Com o surgimento
dessa nova arquitetura, cada instrução passou a ser executada
a cada ciclo de clock.
Resumo
Vamos montar uma tabela com as principais diferenças entre as
arquiteturas. Isto deveria ser suficiente para responder a
maioria das questões de concurso sobre o assunto.
RISC
CISC
Múltiplos conjuntos de
registradores, muitas vezes
superando 256
Único conjunto de
registradores,
tipicamente entre 6
e 16 registradores
Três operandos de
registradores permitidos por
instrução (por ex., add R1,
R2, R3)
Um ou dois operandos
de registradores
permitidos por
instrução (por
ex., add R1, R2)
Passagem eficiente de
parâmetros por registradores
no chip (processador)
Passagem de
parâmetros
ineficiente através
da memória
Instruções de um único ciclo
Instruções de
(ex. load e store)
múltiplos ciclos
Controle hardwired (embutido
no hardware)
Controle
microprogramado
Altamente paralelizado
Fracamente
(pipelined)
paralelizado
Instruções simples e em
número reduzido
Muitas instruções
complexas
Instruções de tamanho fixo
Instruções de
tamanho variável
Complexidade no compilador
Complexidade no
código
Apenas
instruções load e store podem
acessar a memória
Muitas instruções
podem acessar a
memória
Poucos modos de endereçamento
Muitos modos de
endereçamento
Referências:
–
http://pt.wikipedia.org/wiki/RISC?http://pt.wikipedia.org/wiki/CISC
?-
http://0fx66.com/blog/hardware/cisc-risc/?http://waltercunha.com/blog/index.php/2009/08/30/risc-x-cisc/?
- http://www.hardware.com.br/artigos/risc-cisc/
ABC da SOA
O que é arquitetura orientada a serviços (SOA)?
Service-Oriented Architecture (SOA) – ou, em português,
Arquitetura Orientada a Serviços – é um termo que descreve
duas coisas muito diferentes. As duas primeiras palavras
expressam uma metodologia para desenvolvimento de software. A
terceira palavra é um panorama de todos os ativos de software
de uma empresa, assim como uma planta arquitetônica é uma
representação de todas as peças que, juntas, formam uma
construção. Portanto, “service-oriented architecture” é uma
estratégia que proclama a criação de todos os ativos de
software de uma empresa via metodologia de programação
orientada a serviços.
O que é um serviço?
Serviços são porções — ou componentes — de software
construídas de tal modo que possam ser facilmente vinculadas a
outros componentes de software. A idéia por trás destes
serviços é simples: a tecnologia expressa de forma que o
pessoal de negócio possa entender, e não como um aplicativo
enigmático.
No centro do conceito de serviços está a idéia de que é
possível definir partes dos códigos de software em porções
significativas o suficiente para serem compartilhadas e
reutilizadas em diversas áreas da empresa. Com isso, algumas
tarefas passam a ser automatizadas – por exemplo, enviar uma
query para um website de relatório de crédito para descobrir
se um cliente se qualifica para um empréstimo. Se os
programadores em um banco puderem abstrair todo este código em
um nível mais alto (isto é, pegar todo o código que foi
escrito para realizar a verificação de classificação de
crédito e reuni-lo em uma única unidade chamada “obter
classificação de crédito”), eles poderão reutilizar esta
porção da próxima vez que o banco decidir lançar um novo
produto de empréstimo que requeira a mesma informação, ao
invés de ter que escrever o código a partir do zero.
Para chegar a isto, os desenvolvedores criam um invólucro
complexo em torno do código empacotado. Este invólucro é uma
interface que descreve o que a porção faz e como conectar a
ele. É um conceito antigo, que data dos anos 80, quando a
programação orientada a objetos surgiu. A única diferença é a
demanda atual por objetos de software muito maiores e mais
sofisticados.
Na operadora norte-americana Verizon, por exemplo, o serviço
“get CSR” (get customer service record, obter registro de
serviço ao cliente) é uma miscelânea complexa de ações de
software e extrações de dados que emprega infra-estrutura de
integração da empresa para acessar mais de 25 sistemas em
quatro data centers ao redor do país. Antes de criar o serviço
“get CSR”, desenvolvedores da Verizon que precisavam desta
porção crítica de dados tinham que criar links para todos os
25 sistemas — acrescentar seus próprios links sobre a teia
complexa de links que já pendiam dos sistemas populares.
Porém, com o serviço “get CSR” situado em um repositório
central na intranet da Verizon, estes desenvolvedores agora
podem usar o simple object access protocol (SOAP) para criar
um único link para a interface cuidadosamente elaborada ao
redor do serviço. Estes 25 sistemas entram em fila e marcham
imediatamente, enviando informação do cliente para o novo
aplicativo e poupando meses, ou mesmo anos, de tempo de
desenvolvimento dos desenvolvedores cada vez que eles usam o
serviço.
Existem muitas maneiras diferentes de conectar serviços, como
links de programação customizados ou software de integração de
fornecedores, mas, desde 2001, um conjunto de mecanismos de
comunicação de software conhecido como web services, criados
sobre a onipresente World Wide Web, tornou-se um método cada
vez mais popular para integrar componentes de software.
Qual é a diferença entre SOA e web services?
SOA é a arquitetura abrangente para criar aplicações dentro de
uma empresa — pense em um projeto arquitetônico — mas, neste
caso, a arquitetura demanda que todos os programas sejam
criados com uma metodologia de desenvolvimento de software
específica, conhecida como programação orientada a serviço.
Web services são um conjunto de mecanismos-padrão de
comunicação criados sobre a World Wide Web. Ou seja, os web
services são uma metodologia para conectar e comunicar.
Enquanto SOA é uma estratégia de TI.
Como sei se devo adotar uma estratégia SOA?
Sendo uma estratégia arquitetural, SOA envolve muito mais do
que o mero desenvolvimento de software. A criação de uma
arquitetura baseada em um portfólio de serviços demanda que os
CIOs elaborem um “case” convincente para uma arquitetura
corporativa, uma metodologia de desenvolvimento centralizada e
uma equipe centralizada de gerentes de projeto, arquitetos e
desenvolvedores. Também requer um CEO e uma equipe executiva
dispostos, que preparem o terreno para que o pessoal de TI
possa mergulhar em processos core da empresa. Entender estes
processos e conquistar adesão para o compartilhamento
corporativo são a pedra angular de uma transformação do
negócio baseada em SOA.
Governança é vital. Para que os serviços sejam reutilizados na
empresa, tem de haver uma metodologia de desenvolvimento de
software única e centralizada de modo que áreas diferentes não
criem o mesmo serviço de maneiras diferentes ou usem
conectores incompatíveis. Tem que haver um repositório
centralizado para que os desenvolvedores saibam onde procurar
serviços — e TI saiba por quem eles estão sendo utilizados. Os
serviços têm de ser bem documentados para que os
desenvolvedores saibam para que eles servem, como integra-los
e as regras para usá-los. Algumas empresas, por exemplo,
cobram taxas de utilização dos serviços e criam acordos de
performance para garantir que os serviços funcionem bem e não
sobrecarreguem a rede corporativa.
A maioria das empresas que avançou no caminho para SOA criou
um grupo de arquitetura centralizado para escolher processos
que serão capacitados para serviço e consultar áreas
diferentes da empresa para criar os serviços específicos. O
grupo centralizado também cria um mecanismo conveniente para
governança. Se todas as solicitações de serviço têm de passar
pelo grupo de arquitetura, as metodologias de desenvolvimento
de serviço, os projetos e os acordos de performance podem ser
gerenciados mais facilmente.
As empresas que tiveram mais êxito com SOA até agora são as
que sempre tiverem êxito com tecnologia: grandes empresas com
grandes budgets para TI cujo negócio é baseado em tecnologia
(serviços de telecomunicação e financeiros). Elas também
tendem a ter líderes de negócio envolvidos com a área de TI e
dispostos a apoiar seus projetos. Para empresas sem estas
vantagens, SOA talvez não seja tudo o que promete.
Para empresas menores, empresas que apostaram alto em pacotes
de aplicativos integrados e empresas que já adotam estratégias
sólidas de integração de aplicativos, SOA não tem a ver com
“quando”, mas com “se”. Os CIOs têm de ser cuidadosos porque,
na arquitetura orientada a serviços, os elementos
“desenvolvimento de serviço” e “planejamento de arquitetura”
são distintos, porém não independentes — precisam ser
considerados e executados paralelamente. Serviços que são
criados isoladamente, sem levar em conta as metas de
arquitetura e de negócio da empresa, podem apresentar pouco
potencial de reutilização (um dos benefícios mais importantes
da SOA) ou fracassar por completo.
Quais as vantagens da SOA?
Antes de mais nada, os benefícios de da arquitetura orientada
a serviços devem ser contextualizados. Se sua empresa não for
grande ou complexa, isto é, se não tiver mais de dois sistemas
primários que exijam algum nível de integração, é improvável
que o modelo proporcione grandes benefícios. Em meio a todo o
hype atual em torno da SOA, esquece-se facilmente que a
metodologia de desenvolvimento em si não traz vantagens – é o
efeito que ela tem sobre uma infra-estrutura redundante e
complexa que o faz. Os arquitetos dizem que a criação de um
bom aplicativo orientado a serviços envolve mais trabalho do
que a tradicional integração de aplicativos. (Pesquisas
mostram que SOA está sendo usada para integração tradicional
de aplicativos na maioria das empresas.) Assim, o
desenvolvimento da SOA gera um custo inicial extra. Para que
este trabalho produza benefícios, portanto, SOA tem que
eliminar trabalho em outro ponto qualquer, já que a própria
metodologia não gera benefícios para o negócio. Assim, o
primeiro passo é descobrir se existem aplicativos redundantes
e mal integrados que poderiam ser consolidados ou eliminados
como resultado da adoção. Se este for o caso, então há
benefícios potenciais.
Para entender o panorama geral dos benefícios apregoados por
SOA, você precisa examiná-lo em dois níveis: primeiro, as
vantagens táticas do desenvolvimento orientado a serviços e,
segundo, as vantagens da SOA como estratégia de arquitetura
global.
Vantagens do desenvolvimento orientado a serviços:
1. Reutilização de software.
Se o pacote de códigos que constitui um serviço tiver o
tamanho e o escopo certos (um grande “se”, dizem os veteranos
em SOA), então ele poderá ser reutilizado da próxima vez que a
equipe de desenvolvimento precisar de uma função específica
para um novo aplicativo que queira desenvolver. Digamos que
uma empresa de telecomunicações tenha quatro divisões
diferentes, cada qual com seu próprio sistema para processar
pedidos. Todos estes sistemas executam determinadas funções
similares, como verificações de crédito e buscas de registros
de clientes. Mas, tendo em vista que cada sistema é altamente
integrado, nenhuma destas funções redundantes pode ser
compartilhada. O desenvolvimento orientado a serviços coleta o
código necessário para criar uma versão de “verificação de
crédito” que possa ser compartilhada pelos quatro sistemas. O
serviço pode ser uma porção de software totalmente nova ou um
aplicativo composto, consistindo de código de alguns dos
sistemas ou de todos eles. De qualquer forma, o ‘composite’ é
envolto por uma interface que oculta sua complexidade. Da
próxima vez que os desenvolvedores quiserem criar um
aplicativo que exija verificação de crédito, vão criar um link
simples para o novo aplicativo. Eles não precisam se preocupar
em conectar aos sistemas individuais — na realidade, nem
precisam saber como o código foi incluído ou de onde ele vem.
Só precisam criar uma conexão para ele.
Em uma empresa que desenvolve constantemente sistemas novos
que se apóiam em funcionalidade similar — uma empresa
seguradora com muitas divisões diferentes, cada uma com
produtos ligeiramente diferentes, por exemplo, ou uma empresa
que está sempre adquirindo outras — o tempo economizado nas
tarefas de desenvolver, testar e integrar esta
mesma
funcionalidade de software é uma vantagem.
Mas a reutilização não é garantida. Se desenvolvedores em
outras partes da empresa não souberem que os serviços existem
ou não confiarem que eles são bem construídos, ou se as
metodologias de desenvolvimento variarem dentro da empresa, os
serviços podem definhar e não se repetir. As empresas adeptas
da reutilização desenvolveram mecanismos de governança —
equipes de desenvolvimento centralizadas, metodologia única de
desenvolvimento e repositórios de serviços — para aumentar
suas chances de reutilização.
Às vezes, porém, o serviço simplesmente não é bem projetado.
Ele não realiza operações suficientes para ser amplamente
aplicável na empresa ou tenta realizar operações demais. Ou os
desenvolvedores não levaram em conta que outros possam querer
usar o serviço de maneiras diferentes. Para profissionais
experientes no assunto, o dimensionamento adequado dos
serviços — também conhecido como granularidade — é tanto uma
arte quanto uma ciência, e a má-granularidade pode reduzir
drasticamente as possibilidades de reutilização. Pesquisas do
Gartner estimam que apenas algo entre 10% e 40% dos serviços
são reutilizados.
2. Aumentos de produtividade.
Se os desenvolvedores reutilizam serviços, os projetos de
software podem andar mais rápido e a mesma equipe de
desenvolvimento pode trabalhar em mais projetos. A integração
se torna mais barata (no mínimo 30%, de acordo com estimativas
do Gartner) e mais rápida, eliminando alguns meses dos ciclos
de desenvolvimento de novos projetos. Shadman Zafar, vicepresidente sênior para arquitetura e e-services da Verizon,
diz que seu catálogo de serviços dispensou-o de montar uma
equipe de projeto para o desenvolvimento de um processo de
pedido de linha telefônica porque os serviços necessários para
compor o processo já existiam. “Com integração ponto a ponto,
teríamos uma equipe de projeto central criando a integração
geral e equipes locais para cada um dos sistemas ao qual
precisávamos integrar. Com o processo de pedido de linha
telefônica, tínhamos uma única equipe focada quase que
inteiramente em teste de uma ponta a outra”, explica. Isso
poupa tempo e recursos e melhora a qualidade de novos
aplicativos, porque o teste não é mais o último obstáculo de
um processo de desenvolvimento de aplicativos exaustivo; ele é
o foco.
3. Maior agilidade.
Mesmo que os serviços não sejam reutilizados, podem agregar
valor se facilitarem a modificação de sistemas de TI. Na
ProFlowers.com, por exemplo, não existem aplicativos
redundantes ou múltiplas unidades de negócio clamando por
serviços. Mas, com a divisão do processo de pedido de flores
em serviços discretos, cada componente pode ser isolado e
modificado conforme o necessário para lidar com os picos de
demanda que acontecem em datas festivas, segundo Kevin Hall,
CIO da ProFlowers. Quando a ProFlowers tinha apenas um
aplicativo monolítico encarregado do processo, uma única
alteração no processo ou um crescimento do volume de
transações (no dia dos namorados, por exemplo) exigia que o
sistema inteiro fosse recriado.
No novo sistema, os servidores reagem aos picos de atividade
durante cada fase do processo de pedido, transferindo
capacidade para o serviço específico que está precisando mais
dela. O sistema está muito mais previsível e não houve
interrupções desde que o processo capacitado por serviço foi
implantado, no início de 2002, de acordo com Hall. “Visto que
podemos escalar horizontalmente [mais servidores] e
verticalmente [dividindo os serviços], não tenho que comprar
hardware de acordo com as cargas mais altas”, afirma.
Vantagens de uma estratégia SOA:
1. Melhor alinhamento com o negócio.
A arquitetura orientada a serviços é o panorama geral de todos
os processos e fluxos de negócio de uma empresa. Significa que
o pessoal de negócio pode visualizar, pela primeira vez, como
a empresa é construída em termos de tecnologia. Quando
projetos de TI são apresentados em termos de atividades e
processos de negócio e não na forma de aplicativos complexos,
o pessoal de negócio pode apreciar e suportar melhor os
projetos de TI. “Quando eu disse que tínhamos 18 versões de
‘verificação de crédito’ ligeiramente diferentes embutidas em
aplicativos diferentes, em agências diferentes, os diretores
das agências entenderam por que era problemático e apoiaram a
criação de uma única versão que fosse usada por todos”,
recorda Matt Miszewski, CIO para o estado de Wisconsin.
A visão grandiosa da SOA é que, quando TI capacitar plenamente
para serviços os processos importantes de um negócio, o
pessoal de negócio poderá assumir controle sobre modificar e
mesclar os diferentes serviços em novas combinações de
processo próprias. Mas esta visão ainda está a muitos anos de
distância.
2. Uma maneira melhor de vender arquitetura para o negócio (e
TI).
Há tempos a arquitetura corporativa tem sido o conceito que
não ousa dizer seu nome. Alguns CIOs chegam ao ponto de não
usar o termo com os colegas por medo de assustá-los, perdê-los
ou simplesmente entediá-los. Arquitetura corporativa sempre
foi uma empreitada grande, complexa e cara. Seu ROI, com
freqüência, é nebuloso para o negócio. Padronizar, mapear e
controlar ativos de TI não torna o negócio claramente mais
flexível, capaz ou lucrativo. Como resultado, os esforços de
arquitetura de TI muitas vezes fracassam ou se tornam
completamente centrados em TI. A arquitetura orientada a
serviços proporciona o valor ao negócio que, na velha
arquitetura corporativa, raramente passava de uma vaga
promessa. Reutilização, maior produtividade e agilidade em TI
e uma infra-estrutura de software ajustada para processos de
negócio específicos são as iscas para vender uma iniciativa de
arquitetura corporativa para o negócio. Mas lembre-se de que
arquitetura não é para todos. Empresas pequenas ou empresas
extremamente descentralizadas talvez não consigam justificar
uma equipe centralizada de gerentes de projeto, arquitetos e
desenvolvedores.
Como equilibrar a necessidade de planejamento de arquitetura
em SOA com a necessidade de provar o valor para o negócio
rapidamente?
Planejamento arquitetural consome tempo. O desenvolvimento
orientado a serviços, baseado em princípios de programação
conhecidos e padrões de tecnologia amplamente disponíveis
(SOAP, HTTP e assim por diante), pode ser muito mais veloz.
Mas os dois têm que acontecer paralelamente, ensinam os
especialistas. “Fazemos projetos de desenvolvimento conforme o
necessário e, paralelamente, temos um projeto plurianual, mais
longo, de mapear os processos e criar serviços no nível
corporativo”, diz Kurt Wissner, diretor de arquitetura
corporativa e desenvolvimento da American Electric Power
(AEP). “As pessoas precisam ver o benefício da SOA muito
rapidamente. É por isso que gosto de projeto; do contrário,
você não tem nada tangível para vender a ninguém sobre a razão
de fazer o que está fazendo.” Ajudaria ter o plano
arquitetural e o mapeamento de processo implantados antes de
criar os serviços (para aumentar as chances de reutilização),
mas o planejamento de arquitetura não apresenta retorno no
curto prazo, o que pode ser devastador. “Tentei um plano
ambicioso demais em outra empresa e fracassei”, lembra
Wissner. “Criamos um grande plano de arquitetura de milhões de
dólares que duplicou o que já tínhamos. O plano não apresentou
muito valor em relação à integração ponto a ponto tradicional
e nossos esforços não deram em nada. Se você já começa com a
empresa inteira, são muitos os riscos de fracassar.”
Ao abordar o planejamento empresarial em porções menores na
AEP, Wissner pode se recuperar mais facilmente de revezes.
“Tivemos tropeços, mas conseguimos tomar atitudes corretivas
porque não era nada muito grande”, diz.
Como sei quais serviços vão gerar mais valor em troca do meu
investimento?
Quando estiver em dúvida, comece com processos que envolvem
clientes, afetam diretamente a receita e abordem um ponto
nevrálgico da empresa. De acordo com pesquisa realizada em
2006 pelo Business Performance Management Institute, mudanças
em necessidades e preferências de clientes são o principal
motor de mudança em processos de negócio ou de adoção de novos
aplicativos, seguidas por ameaças competitivas e novas
oportunidades de receita. “Aplicativos de ponta são os que
fornecem o maior valor para o negócio e têm um bom conjunto de
requisitos de mudança que surgem com muita freqüência”, diz
Daniel Sholler, vice-presidente de pesquisa do Gartner. “Se
você puder aprimorar estes aplicativos em 10%, é melhor do que
aprimorar aplicativos de nível mais baixo em 50%.” Obviamente,
acrescenta Sholler, a SOA pode não fornecer mais valor do que
um bom aplicativo empacotado, por exemplo. “Mas, se é algo que
você mesmo teria que criar de qualquer forma, então tem que
ser orientado a serviço.”
Como SOA vai afetar meu grupo de TI?
Se você tem uma empresa descentralizada, prepare-se para
lutar. SOA leva à centralização. Na realidade, pede
centralização. “Você precisa ter alguém liderando, você
precisa ter um indivíduo ou uma pequena equipe gerenciando a
arquitetura”, aconselha Mike Falls, engenheiro sênior de
sistemas da Fastenal, empresa de suprimentos industriais e de
construção. “Se for cada equipe por si, elas podem acabar
adotando maneiras diferentes de criar serviços. Você precisa
de um grupo, um conjunto de pesquisas e alguém para garantir
que os grupos de desenvolvimento se atenham à metodologia de
desenvolvimento de serviço.”
À medida que o portfólio de serviços cresce, o processo de
desenvolvimento pode começar a assemelhar-se a uma linha de
montagem. “Transforma-se em uma fábrica”, diz Wissner, da AEP.
“Você tem equipes de projeto diferentes através das quais
canaliza o trabalho e elas podem aumentar e diminuir conforme
o necessário.”
Depois que a “fábrica” SOA está produzindo a todo vapor,
prepare-se para acrescentar mais gerentes de projeto,
analistas de negócio e arquitetos à medida que a produtividade
dos desenvolvedores aumenta, diz Haal, da ProFlowers. “Dois
desenvolvedores agora podem fazer o trabalho de seis”,
observa. “Isso significa que os arquitetos e gerentes de
projeto estão se esforçando para acompanhar o trabalho dos
engenheiros. Provavelmente estamos realizando 50% de trabalho
a mais do que há três anos.”
Estes programadores precisam entender programação orientada a
objeto e aplicativos distribuídos — o que implica
investimentos em treinamento. Segundo pesquisa de
CIO/Computerworld, apenas 25% dos entrevistados têm as equipes
de que necessitam para adotar arquitetura orientada a serviços
— 49% planejam ter ou já têm programas de treinamento para que
a equipe atual trabalhe a todo vapor.
Fonte: CIO
Arquitetura
TCP/IP
e
Protocolos
O conjunto de protocolos TCP/IP foi projetado especialmente
para ser o protocolo utilizado na Internet. Sua característica
principal é o suporte direto a comunicação entre redes de
diversos tipos. Neste caso, a arquitetura TCP/IP é
independente da infra-estrutura de rede física ou lógica
empregada. De fato, qualquer tecnologia de rede pode ser
empregada como meio de transporte dos protocolos TCP/IP, como
será visto adiante.
Endereçamento IP
Existem duas versões dos protocolo IP: IPV4 e IPV6. A primeira
é utilizada atualmente e está se esgotando devido a quantidade
devido ao número de máquinas conectadas na Internet
utilizando-o. Já o IPV6 está vindo para solucionar esse
problema de escassez, sendo uma versão melhorada.
IPV4
Os endereços IP são compostos por 4 blocos de 8 bits (32
bits), sendo representados de 0 a 255, ou seja, as 256
possibilidades dos 8 bits. Cada bloco é chamado de “octeto”. A
sua utilização em “octetos” é apenas para facilitar a
visualização, mas quando processados, são apenas números
binários. Total de endereços IP é de 4.294.967.296.
Existem algumas faixas de IP que são reservadas para redes
locais, que são as que iniciam da seguinte forma:
10.x.x.x
192.168.x.x
172.16.x.x até 172.31.x.x
O endereço IP é formado por duas informações principais: o
endereço de rede e o endereço de host dentro da rede. Veja o
exemplo do IP “10.0.0.4”, onde o primeiro octeto, o “10”, é o
endereço de rede, já o segundo até o quarto octeto “0.0.4” é o
endereço de host. Outro exemplo seria o IP “172.22.45.23”,
onde “172.22” é o endereço de rede e “45.23” é o endereço de
host.
Existe também algumas regras quanto a validade de um IP, sendo
os listados abaixo como inválidos:
0.xxx.xxx.xxx – Nenhum IP pode começar com zero. Somente
utilizado é para responder às requisições DHCP de uma
máquina que entrou na rede;
127.xxx.xxx.xxx – Chamado de “loopback”. Seria o
endereço reservado para testes e para interface chamada
de “loopback”, ou seja, a própria máquina.
255.xxx.xxx.xxx, xxx.255.255.255, xxx.xxx.255.255 –
Nenhum identificador de rede pode ser 255 e nenhum
endereço de host pode ser composto apenas de endereços
255, independente de classe do endereço.
xxx.0.0.0, xxx.xxx.0.0 – Nenhum identificador de host
pode ser composto apenas de zeros, pois são endereços
reservados da rede.
xxx.xxx.xxx.255, xxx.xxx.xxx.0 – Nenhum endereço de
classe C pode terminar com 0 ou 255, pois são utilizados
para envio de pacotes broadcast.
Classes de Endereçamento IP
Inicialmente os endereços IP foram divididos em classes que
reservam um número diferente de octetos para o endereçamento
da rede, sendo elas chamadas de A, B, C, D e E. Dentre elas,
apenas as classes A, B e C são utilizadas realmente, pois a D
e E são para utilização futura. Veja abaixo a separação das
classes:
Classe A:
Com tamanho de 8 bits no endereço de rede;
Tamanho de 24 bits para endereços de hosts;
O primeiro octeto decimal entre 1 e 126;
Utiliza máscara de rede 255.0.0.0;
Total de redes de 27-2 = 126;
Total de hosts de 224-2 = 16.777.214;
Classe B:
Com tamanho de 16 bits no endereço de rede;
Tamanho de 16 bits para endereços de hosts;
O primeiro octeto decimal entre 128 e 191;
Utiliza máscara de rede 255.255.0.0;
Total de redes de 214-2 = 16.380;
Total de hosts de 216-2 = 65.532;
Classe C:
Com tamanho de 24 bits no endereço de rede;
Tamanho de 8 bits para endereços de hosts;
O primeiro octeto decimal entre 192 e 223;
Utiliza máscara de rede 255.255.255.0;
Total de redes de 221-2 = 2.097.150;
Total de hosts de 28-2 = 254;
Classe D:
Reservado para multicasting;
Sendo o primeiro octeto decimal entre 224 e 239;
Classe E:
Reservado para pesquisas;
Sendo o primeiro octeto decimal entre 240 e 247;
IPV6
Como já falei anteriormente, o IPV6 veio para resolver o
problema da escassez de endereços IP do IPV4.
Os endereços IP são compostos por 8 blocos de 4
caracteres do sistema hexadecimal em cada bloco, ou seja, 16
caracteres, totalizando 128 bits, sendo representados de 0 à
F, ou seja, as 16 possibilidades para cada caracter. Cada
bloco é chamado de “octeto”. A sua utilização em “octetos” é
apenas para facilitar a visualização, mas quando processados,
são apenas números binários. Total de endereços IP é
de 340.282.366.920.938.463.463.374.607.431.768.211.456.
Veja
um
exemplo
endereço: 2001:247f:6c24:17da:cd89:d4e2:bcd7:a36e
de
Algumas outras características:
Autoconfiguração do endereço, não sendo mais necessário
o uso do DHCP;
Endereçamento hierárquico, o que simplifica as tabelas
de encaminhamento das tabelas dos roteadores da rede, o
que diminui a carga de processamento deles;
O cabeçalho foi totalmente remodelado;
Cabeçalhos de extensão para guardar detalhes adicionais;
Suporte a qualidade diferenciada para conexões
diferenciadas para áudio e vídeo;
Capacidade de extensão, podendo adicionar novas
especificações de forma simples;
Encriptação. Suporte a extensões que permitem opções de
segurança.
Um detalhe curioso sobre o endereçamento no IPV6 é a sua
capacidade de ser encurtado. Veja o seguinte exemplo de
endereço: 2001:247f:0000:0000:cd89:d4e2:bcd7:a36e. Onde tem os
blocos com 0000, podemos simplesmente substituir por um único
zero, ficando 2001:247f:0:0:cd89:d4e2:bcd7:a36e ou até
mesmo 2001:247f::cd89:d4e2:bcd7:a36e
Pode-se ainda:
Utilizar letras minúsculas e maiúsculas;
Utilizar as regras de abreviação, como omitir zeros à
esquerda e representar zeros contínuos por “::“
Tipos de endereços
Unicast – O endereço identifica apenas uma interface de rede.
Desse modo, um pacote enviado a um endereço unicast é entregue
a uma única interface. Cada endereço IPv4 unicast inclui uma
ID de rede e uma ID de host.
Unicast
Multicast – Multicast é a entrega de informação para múltiplos
destinatários simultaneamente usando a estratégia mais
eficiente onde as mensagens só passam por um link uma única
vez e somente são duplicadas quando o link para os
destinatários se divide em duas direções.
Multicast
Anycast – Um pacote destinado a um endereço multicast é
enviado para todas as interfaces do grupo, mas somente um
deles é escolhido. Há também uns um-à-muitos associação entre
endereços de rede e endpoints de rede: cada endereço de
destino identifica um jogo de endpoints do receptor, mas
somente um deles é escolhido em todo o tempo dado para receber
a informação de qualquer remetente dado.
Anycast
Broadcast – Permite que a informação seja enviada para todas
as maquinas de uma LAN, MAN, WAN e TANS, redes de
computadores e sub-redes.
Broadcast
Camadas TCP/IP
TCP/IP é um acrônimo para o termo Transmission Control
Protocol/Internet Protocol Suite, ou seja é um conjunto de
protocolos,
deram seus
estrutura de
paradigma de
onde dois dos mais importantes (o IP e o TCP)
nomes à arquitetura. O protocolo IP, base da
comunicação da Internet é um protocolo baseado no
chaveamento de pacotes (packet-switching).
Os protocolos TCP/IP podem ser utilizados sobre qualquer
estrutura de rede, seja ela simples como uma ligação ponto-aponto ou uma rede de pacotes complexa. Como exemplo, pode-se
empregar estruturas de rede como Ethernet, Token-Ring, FDDI,
PPP, ATM, X.25, Frame-Relay, barramentos SCSI, enlaces de
satélite, ligações telefônicas discadas e várias outras como
meio de comunicação do protocolo TCP/IP.
A arquitetura TCP/IP, assim como OSI realiza a divisão de
funções do sistema de comunicação em estruturas de camadas. Em
TCP/IP as camadas são:
Aplicação
Transporte
Inter-Rede
Rede
Modelo OSI e TCP/IP
Vamos analisar cada uma das camadas da Arquitetura TCP/IP e
vamos falar sobre os protocolos que são utilizados em cada uma
delas.
1- Camada Física / Enlace / Host /
Rede
A camada de rede é responsável pelo envio de datagramas
construídos pela camada Inter-Rede. Esta camada realiza também
o mapeamento entre um endereço de identificação de nível
Inter-rede para um endereço físico ou lógico do nível de Rede.
A camada Inter-Rede é independente do nível de Rede.
Também chamada camada de abstração de hardware, tem como
função principal à interface do modelo TCP/IP com os diversos
tipos de redes (X.25, ATM, FDDI, Ethernet, Token Ring, Frame
Relay, sistema de conexão ponto-a-ponto SLIP, etc.). Como há
uma grande variedade de tecnologias de rede, que utilizam
diferentes velocidades, protocolos, meios transmissão,
etc. esta camada não é normatizada pelo modelo, o que provê
uma das grandes virtudes do modelo TCP/IP: a possibilidade de
interconexão e interoperação de redes heterogêneas.
Os protocolos existentes nesta camada são:
Protocolos com estrutura de rede própria (X.25, FrameRelay, ATM)
Protocolos de Enlace OSI (PPP, Ethernet, Token-Ring,
FDDI, HDLC, SLIP, …)
Protocolos de Nível Físico (V.24, X.21)
Protocolos de barramento de alta-velocidade (SCSI,
HIPPI, …)
Protocolos de mapeamento de endereços (ARP – Address
Resolution Protocol) – Este protocolo pode
considerado também como parte da camada Inter-Rede.
ser
2-Camada de Rede / Inter-Rede /
Internet
Esta camada realiza a comunicação entre máquinas vizinhas
através do protocolo IP. Para identificar cada máquina e a
própria rede onde estas estão situadas, é definido um
identificador, chamado endereço IP, que é independente de
outras formas de endereçamento que possam existir nos níveis
inferiores. No caso de existir endereçamento nos níveis
inferiores é realizado um mapeamento para possibilitar a
conversão de um endereço IP em um endereço deste nível.
Os protocolos existentes nesta camada são:
Protocolo de transporte de dados: IP – Internet
Protocol;
Protocolo de controle e erro: ICMP – Internet Control
Message Protocol;
Protocolo de controle de grupo de endereços: IGMP –
Internet Group Management Protocol;
Protocolos de controle de informações de roteamento como
BGP, OSPF e o RIP;
Protocolo ARP “Address Resolution Protocol” – Permite
certo computador se comunicar com outro computador em
rede quando somente o endereço de IP é conhecido pelo
destinatário.
Protocolo RARP “Reverse Address Resolution Protocol”
– Faz o contrario do protocolo ARP, ao invés de obter o
endereço MAC da maquina, o protocolo RARP requisita o
endereço de IP.
O protocolo IP realiza a função mais importante desta camada
que é a própria comunicação inter-redes. Para isto ele realiza
a função de roteamento que consiste no transporte de mensagens
entre redes e na decisão de qual rota uma mensagem deve seguir
através da estrutura de rede para chegar ao destino.
O protocolo IP utiliza a própria estrutura de rede dos níveis
inferiores para entregar uma mensagem destinada a uma máquina
que está situada na mesma rede que a máquina origem. Por outro
lado, para enviar mensagem para máquinas situadas em redes
distintas, ele utiliza a função de roteamento IP. Isto ocorre
através do envio da mensagem para uma máquina que executa a
função de roteador. Esta, por sua vez, repassa a mensagem para
o destino ou a repassa para outros roteadores até chegar no
destino.
3-Camada de Transporte
Esta camada reúne os protocolos que realizam as funções de
transporte de dados fim-a-fim, ou seja, considerando apenas a
origem e o destino da comunicação, sem se preocupar com os
elementos intermediários. A camada de transporte possui dois
protocolos que são o UDP (User Datagram Protocol) e TCP
(Transmission Control Protocol).
O protocolo UDP realiza apenas a multiplexação para que várias
aplicações possam acessar o sistema de comunicação de forma
coerente.
O protocolo TCP realiza, além da multiplexação, uma série de
funções para tornar a comunicação entre origem e destino mais
confiável. São responsabilidades do protocolo TCP: o controle
de fluxo, o controle de erro (checksum), a sequenciação e a
multiplexação de mensagens.
A camada de transporte oferece para o nível de aplicação um
conjunto de funções e procedimentos para acesso ao sistema de
comunicação de modo a permitir a criação e a utilização de
aplicações de forma independente da implementação. Desta
forma, as interfaces socket ou TLI (ambiente Unix) e Winsock
(ambiente Windows) fornecem um conjunto de funções-padrão para
permitir que as aplicações possam ser desenvolvidas
independentemente do sistema operacional no qual rodarão.
4-Camada
de
Aplicação
Apresentação / Sessão
/
A camada de aplicação reúne os protocolos que fornecem
serviços de comunicação ao sistema ou ao usuário. Pode-se
separar os protocolos de aplicação em protocolos de serviços
básicos ou protocolos de serviços para o usuário:
Protocolos de serviços básicos, que fornecem serviços para
atender as próprias necessidades do sistema de comunicação
TCP/IP: DNS, BOOTP, DHCP
Protocolos de serviços para o usuário: FTP, HTTP, Telnet,
SMTP, POP3, IMAP, TFTP, NFS, NIS, LPR, LPD, ICQ, RealAudio,
Gopher, Archie, Finger, SNMP e outros
Questões de Concursos
(FGV – 2010 – CODESP-SP – Analista de Sistemas – Tipo 1) No
que diz respeito ao Modelo de Referência OSI/ISO e arquitetura
TCP/IP, são protocolos da camada de rede:
a) IP, ARP e ICMP.
b) TCP, RARP e IP.
c) BGP, FTP e UDP.
d) ICMP, UDP e FTP.
e) ARP, TCP e RARP.
(CESPE – 2007 – TRE-AP – Técnico Judiciário – Programação de
Sistemas) Na arquitetura TCP/IP, entre os protocolos
envolvidos na camada de rede encontram-se o IP e o
a) TCP.
b) UDP.
c) RSTP.
d) ICMP.
e) HTTP.
(CESPE – 2010 – INMETRO – Pesquisador – Ciência da Computação)
Para interligar LAN, ou segmentos de LAN, são utilizados
dispositivos de conexão, que podem operar em diferentes
camadas da arquitetura TCP/IP. Assinale a opção que indica o
dispositivo que opera em todas as cinco camadas do modelo
TCP/IP.
a) Hub
b) Gateway
c) Bridge
d) Roteador
e) Switch
(CESPE – 2010 – INMETRO – Pesquisador – Ciência da Computação)
O único serviço que é realizado tanto pelo protocolo TCP
quanto pelo protocolo UDP da camada de transporte da
arquitetura TCP/IP é
a) controle de fluxo.
b) controle de envio.
c) controle de congestionamento.
d) controle de recebimento.
e) checksum.
(CESPE – 2011 – Correios – Analista de Correios – Engenheiro –
Engenharia de Redes e Comunicação) Julgue os seguintes itens
com base no modelo de referência TCP/IP. Os serviços DNS são
imprescindíveis para a comunicação em redes TCP/IP, já que,
sem eles, a camada de rede se torna totalmente inoperante,
fazendo que, em nenhuma situação, ocorra comunicação IP.
( ) Certo
( ) Errado
(CESPE – 2011 – Correios – Analista de Correios – Analista de
Sistemas – Suporte de Sistemas) A camada física do protocolo
TCP/IP mantém suporte a aplicações do usuário e interage com
vários programas, para que estes se comuniquem via rede.
( ) Certo
( ) Errado
(FCC – 2010 – TCE-SP – Agente da Fiscalização Financeira –
Informática – Produção e Banco de Dados) Pela ordem, da mais
baixa (1ª) até a mais alta (4ª), as camadas do modelo de
referência TCP/IP são
a) Inter-redes, Rede, Transporte e Sessão.
b) Inter-redes, Host/rede, Transporte, e Aplicação.
c) Inter-redes, Transporte, Sessão e Aplicação.
d) Host/rede, Inter-redes, Transporte e Sessão.
e) Host/rede, Inter-redes, Transporte e Aplicação.
(CESPE – 2011 – Correios – Analista de Correios – Analista de
Sistemas – Suporte de Sistemas) A camada de aplicação na
arquitetura TCP/IP equivale às camadas de aplicação,
apresentação e sessão da arquitetura OSI.
( ) Certo
( ) Errado
(FCC – 2011 – TRT – 24ª REGIÃO (MS) – Analista Judiciário –
Tecnologia da Informação) São protocolos da camada 3 (rede,
inter-redes ou internet) do modelo TCP/IP de cinco camadas:
a) IPSec e DNS.
b) SMTP e TCP.
c) 802.11 Wi-Fi e SMTP.
d) SNMP e TCP.
e) IPSec e ICMP.
(IPAD – 2010 – Prefeitura de Goiana – PE – Administrador de
Redes – 1) Os protocolos da arquitetura TCP/IP são organizados
em camadas. Acerca desse assunto, analise as seguintes
afirmativas:
1. A camada física está relacionada a características
elétricas e mecânicas do meio de transmissão.
2. Os protocolos TCP e UDP fazem parte da camada de rede.
3. Os protocolos HTTP e FTP fazem parte da camada de
transporte.
Assinale a alternativa correta:
a) Apenas uma das afirmativas é falsa.
b) Apenas as afirmativas 1 e 2 são falsas.
c) Apenas as afirmativas 1 e 3 são falsas.
d) Apenas as afirmativas 2 e 3 são falsas.
e) As afirmativas 1, 2 e 3 são falsas.
Gabarito e Comentários das
Questões
(FGV – 2010 – CODESP-SP – Analista de Sistemas – Tipo 1) No
que diz respeito ao Modelo de Referência OSI/ISO e arquitetura
TCP/IP, são protocolos da camada de rede:
Letra “A”. Veja aqui mesmo no artigo, onde informo os
protocolos utilizados na camada de rede: IP, ARP, RARP, ICMP,
IGMP.
Uma outra dica pra resolver essa questão era só lembrar que o
protocolo TCP e UDP fazem parte da camada de Transporte, e por
eliminação nos restaria a nossa resposta.
(CESPE – 2007 – TRE-AP – Técnico Judiciário – Programação de
Sistemas) Na arquitetura TCP/IP, entre os protocolos
envolvidos na camada de rede encontram-se o IP e o
Letra “D”. Praticamente serve a mesma explicação da questão
acima.
(CESPE – 2010 – INMETRO – Pesquisador – Ciência da Computação)
Para interligar LAN, ou segmentos de LAN, são utilizados
dispositivos de conexão, que podem operar em diferentes
camadas da arquitetura TCP/IP. Assinale a opção que indica o
dispositivo que opera em todas as cinco camadas do modelo
TCP/IP.
Letra “B”. O Hub trabalha na camada Física/Enlace. Switch na
camada de Enlace, porque trabalha com o endereço MAC. Os
Switch Layer 3 e Roteadores trabalham com o IP na camada de
Rede.
(CESPE – 2010 – INMETRO – Pesquisador – Ciência da Computação)
O único serviço que é realizado tanto pelo protocolo TCP
quanto pelo protocolo UDP da camada de transporte da
arquitetura TCP/IP é
Letra “E”. O protocolo TCP é baseado na conexão encapsulada no
IP. Ele garante a entrega dos pacotes, sendo feito o envio de
forma sequencial, realizando um checksum que valida tanto o
cabeçalho, quanto os dados do pacote. Se houver perda do
pacote ou ele estiver corrompido, será feita a retransmissão
do que houve falha.
(CESPE – 2011 – Correios – Analista de Correios – Engenheiro –
Engenharia de Redes e Comunicação) Julgue os seguintes itens
com base no modelo de referência TCP/IP. Os serviços DNS são
imprescindíveis para a comunicação em redes TCP/IP, já que,
sem eles, a camada de rede se torna totalmente inoperante,
fazendo que, em nenhuma situação, ocorra comunicação IP.
ERRADO. O DNS (Sistema de Nomes de Domínio) é um sistema para
atribuição de nomes a computadores e serviços de rede,
organizado numa hierarquia de domínios. As redes TCP/IP, tais
como a Internet, utilizam o DNS para localizarem computadores
e serviços através de nomes amigáveis. Sendo assim, se o
usuário souber o endereço IP do que ele está querendo se
comunicar, ele poderá utilizar a rede normalmente, só será
mais “trabalhoso” ter que saber os IPs de todos em sua rede, o
que torna inviável em redes corporativas.
(CESPE – 2011 – Correios – Analista de Correios – Analista de
Sistemas – Suporte de Sistemas) A camada física do protocolo
TCP/IP mantém suporte a aplicações do usuário e interage com
vários programas, para que estes se comuniquem via rede.
ERRADO. Este é um trabalho da camada de Aplicação.
(FCC – 2010 – TCE-SP – Agente da Fiscalização Financeira –
Informática – Produção e Banco de Dados) Pela ordem, da mais
baixa (1ª) até a mais alta (4ª), as camadas do modelo de
referência TCP/IP são
Letra “E”. Mostrei os diversos nomes para cada uma das camadas
neste artigo. Baseada na questão, temos a resposta Host/rede,
Inter-redes, Transporte e Aplicação.
(CESPE – 2011 – Correios – Analista de Correios – Analista de
Sistemas – Suporte de Sistemas) A camada de aplicação na
arquitetura TCP/IP equivale às camadas de aplicação,
apresentação e sessão da arquitetura OSI.
CERTO. Veja a figura desta postagem.
(FCC – 2011 – TRT – 24ª REGIÃO (MS) – Analista Judiciário –
Tecnologia da Informação) São protocolos da camada 3 (rede,
inter-redes ou internet) do modelo TCP/IP de cinco camadas:
Letra “E”. Mas só para esclarecer quanto a quantidade de
camadas. Alguns autores identificam um total 5 camadas, como
citada na questão, que seriam: Físico, Link, Internet,
Transporte e Aplicação. Mas Tannenbaum e a própria RFC adotam
apenas 4.
(IPAD – 2010 – Prefeitura de Goiana – PE – Administrador de
Redes – 1) Os protocolos da arquitetura TCP/IP são organizados
em camadas. Acerca desse assunto, analise as seguintes
afirmativas:
1. A camada física está relacionada a características
elétricas e mecânicas do meio de transmissão.
2. Os protocolos TCP e UDP fazem parte da camada de rede.
3. Os protocolos HTTP e FTP fazem parte da camada de
transporte.
Assinale a alternativa correta:
Letra “D”. Analisando cada uma das afirmativas: 1-Correto; 2Errado, pois o TCP e UDP fazem parte da camada de Transporte;
3-Errado, já que o HTTP e FTP são da camada de Aplicação.
Sistema de Gerenciamento de
Banco
de
Dados
ClienteServidor
Em
sua
forma
mais
simples,
um banco de dados cliente servidor (C/S) divide o
processamento do banco de dados entre dois sistema:
o cliente (geralmente um PC) executando a aplicação
do banco de dados, e o servidor do banco de dados que executa
todo o DBMS ou parte dele.
O servidor de arquivos da LAN continua oferecendo recursos
compartilhado, com impressora e espaço em disco para
aplicações. O servidor de banco de dados pode executar no
mesmo PC do servidos de arquivo, ou, como acontece mais
habitualmente, em seu próprio computador, que virar em termo
de tamanho, desde um PC até um mainframe. A aplicação
de banco de dados no cliente, citado como sistema auxiliar,
manipula todo o processamento de entrada e saída de tela e
usuário.
O sistema especializado no servidor manipula o processamento
dedados e os acessos de discos. Por exemplo, um usuário no
sistema auxiliar cria uma solicitação, conhecida como
consulta, de dados do banco de dados, e a aplicação auxiliar
envia a solicitação através da rede para o servidor.
O servidor debanco de dados faz a verdadeira operação de busca
e retorna somente os dados que preencham corretamente a
consulta do usuário.
A vantagem imediata do sistema cliente servidor é óbvio:
dividindo o processamento entre dois sistemas, a intensidade
do trafego de dados na rede diminui consideravelmente. O
latência também aumenta, executando-se o BDMS num sistema de
alta potência, sem incorrer na despesa de atualização de todo
sistema cliente, que seria necessário se todo o processamento
fosse feito num PC local.
A
maior
desvantagem
dos
sistemas
de banco de dados cliente servidor é que eles exigem que
os dados sejam armazenados num único sistema. Isto pode ser um
grande problema para as grande empresas, que talvez precisem
suportar usuário de banco de dados espalhado por uma ampla
região geográfica ou que precisem compartilhar parte dosbancos
de dados dos seus departamentos com outros departamentos ou
com um hospedeiro central. Estas situações exigem um método de
distribuição de dados entre diversos hospedeiros ou pontos.
Cliente / Servidor
Na arquitetura centralizada, existe um computador com grande
capacidade de processamento, o qual é o hospedeiro do SGBD e
emuladores para os vários aplicativos. Esta arquitetura tem
como principal vantagem a de permitir que muitos usuários
manipulem grande volume de dados. Sua principal desvantagem
está no seu alto custo, pois exige ambiente especial para
mainframes e soluções centralizadas.
Na Cliente-Servidor, o cliente (front_end) executa as tarefas
do aplicativo, ou seja, fornece a interface do usuário (tela,
e processamento de entrada e saída). O servidor (back_end)
executa as consultas no DBMS e retorna os resultados ao
cliente. Apesar de ser uma arquitetura bastante popular, são
necessárias soluções sofisticadas de software que
possibilitem: o tratamento de transações, as confirmações de
transações (commits), desfazer transações (rollbacks),
linguagens de consultas (stored procedures) e gatilhos
(triggers). A principal vantagem desta arquitetura é a divisão
do processamento entre dois sistemas, o que reduz o tráfego de
dados na rede.
Vantagens
Suas soluções são menos dispendiosas do que as de
minicomputadores ou mainframes alternativos de
necessidades de infraestrutura de inicialização;
Suas soluções permitem que o usuário final utilize a GUI
do microcomputador, aprimorando, assim, a funcionalidade
e a simplicidade. Em particular, a utilização do
navegador da web, universalmente disponível, em conjunto
com modelos de Java e .NET, fornece uma interface
familiar ao usuário final;
Mais pessoas no mercado de trabalho possuem habilidades
com PC do que com mainframe. A maior parte dos alunos da
nova geração está aprendendo habilidades de programação
Java e .NET;
O PC é bem mais estabelecido no local de trabalho. Além
disso, o crescimento do uso da internet como um canal de
negócios, aliado aos avanços de segurança (SSL, Redes
Privadas Virtuais, autenticação de multifatores, etc.),
fornece plataforma mais confiável e segura para as
transações comerciais;
Existem várias ferramentas de análise e consulta de
dados para facilitar a interação com muitos SGBDs
disponíveis no mercado de PCs;
Há uma considerável vantagem de custos para o
desenvolvimento de aplicações offloading do mainframe
para PCs poderosos.
Desvantagens
A arquitetura cliente/servidor cria um ambiente mais
complexo no qual diferentes plataformas (LANs, Sistemas
Operacionais, etc.) costumam ser difíceis de gerenciar;
Um aumento no número de usuários e de locais de
processamento costumam abrir espaço para problemas de
segurança;
O ambiente cliente/servidor torna possível a
disseminação do acesso aos dados a um círculo de
usuários muito mais amplos. Esse ambiente amplia a
demanda por pessoal com profundo conhecimento de
computadores e aplicativos. Os encargos de treinamento
elevam o custo de manutenção do ambiente.
Mapa Mental de Arquitetura e
Organização de Computadores –
Hardware
Mapa Mental de Arquitetura e Organização de Computadores –
Hardware
Mapa Mental de Arquitetura e Organização de Computadores Hardware
Mapa Mental de BD – Banco de
Dados Relacional
Mapa Mental de BD – Banco de Dados Relacional
Mapa Mental de BD - Banco de Dados Relacional
Arquiteturas OLAP
Vejam abaixo os conceitos e a demonstração comparativas das
arquiteturas OLAP quanto a desempenho, escalabilidade,
investimentos e outros detalhes importantes.
Conceitos iniciais
Cubo de dados é uma estrutura multidimensional que expressa a
forma na qual os tipos de informações se relacionam entre si.
É formado pela tabela de fatos e pelas tabelas de dimensão que
a circundam e representam possíveis formas de visualizar e
consultar os dados. O cubo armazena todas as informações
relacionadas a um determinado assunto, de maneira a permitir
que sejam montadas várias combinações entre elas, resultando
na extração de várias visões sobre o mesmo tema (HOKAMA et al.
2004, p. 49).
O Slice/Dice é uma das principais características de uma
ferramenta OLAP. É uma operação com responsabilidade de
recuperar o micro-cubo dentro do OLAP, além de servir para
modificar a posição de uma informação, alterar linhas por
colunas de maneira a facilitar a compreensão dos usuários e
girar o cubo sempre que tiver necessidade.
MOLAP
Características:
Arquitetura OLAP tradicional;
Os dados são armazenados em cubos dimensionais, em
formatos proprietários, e não em banco de dados
relacionais;
O usuário trabalha, monta e manipula os dados do cubo
diretamente no servidor.
Vantagens:
Alto desempenho: os cubos são construídos para uma
rápida recuperação de dados;
Pode executar cálculos complexos: todos os cálculos são
pré-gerados quando o cubo é criado e podem ser
facilmente aplicados no momento da pesquisa de dados.
Desvantagens:
Baixa escalabilidade: sua vantagem de conseguir alto
desempenho com a pré-geração de todos os cálculos no
momento da criação dos cubos, faz com que o MOLAP seja
limitado a uma pouca quantidade de dados. Esta
deficiência pode ser contornada pela inclusão apenas do
resumo dos cálculos quando se construir o cubo;
Investimentos altos: este modelo exige enormes
investimentos adicionais como cubo de tecnologia
proprietária.
Termos-chave:
Armazenamento dos dados em cubos dimensionais e em
formato proprietário;
Alto desempenho;
Execução de cálculos complexos;
Baixa escalabilidade;
Investimentos altos.
ROLAP
Características:
Os dados são armazenados em banco de dados relacionais;
A manipulação dos dados armazenados no banco de dados
relacional é feita para dar a aparência de operação
Slice/Dice tradicional;
Na essência, cada ação de Slice/Dice é equivalente a
adicionar uma cláusula WHERE em uma declaração SQL.
Vantagens:
Alta escalabilidade: usando a arquitetura ROLAP, não há
nenhuma restrição na limitação da quantidade dados a
serem analisados, cabendo essa limitação sendo do
próprio banco de dados relacional utilizado;
Pode alavancar as funcionalidades inerentes do banco de
dados relacional: Muitos bancos de dados relacionais já
vêm com uma série de funcionalidades e a arquitetura
ROLAP pode alavancar estas funcionalidades.
Desvantagens:
Baixo desempenho: cada relatório ROLAP é basicamente uma
consulta SQL (ou várias consultas SQL) na banco de dados
relacional e uma consulta pode ser consumir muito tempo
se houver uma grande quantidade de dados;
Limitado pelas funcionalidades SQL: ROLAP se baseia
principalmente na geração instruções SQL para consultar
a base de dados relacional, porém essas instruções não
suprem todas as necessidades (por exemplo, é difícil de
realizar cálculos complexos utilizando SQL). Portanto,
usar ROLAP é se limitar ao que instruções SQL podem
fazer.
Termos-chave:
Alta escalabilidade;
Pode alavancar as funcionalidades inerentes do banco de
dados relacional;
Baixo desempenho;
Limitado pelas funcionalidades SQL.
HOLAP
Características:
HOLAP tenta combinar as vantagens de MOLAP e ROLAP,
extraindo o que há de melhor de cada uma, ou seja, a
alta performance do MOLAP com a melhor escalabilidade do
ROLAP;
Para informações do tipo síntese, HOLAP utiliza cubos
dimensionais para um desempenho mais rápido;
Quando for necessário mais detalhe de uma informação,
HOLAP pode ir além do cubo multidimensional para o banco
de dados relacional utilizado no armazenamento dos
detalhes.
Vantagens:
Alto desempenho: os cubos dimensionais apenas armazenam
síntese das informações;
Alta escalabilidade: os detalhes das informações são
armazenados em um banco de dados relacional.
Desvantagens:
Arquitetura de o maior custo: é modelo que possui o
maior custo de aquisição.
Termos-chave:
Alto desempenho;
Alta escalabilidade;
Arquitetura de o maior custo.
DOLAP
Característica:
São as ferramentas que, a partir de um cliente qualquer,
emitem uma consulta para o servidor e recebem o cubo de
informações de volta para ser analisado na estação
cliente.
Vantagens:
Pouco tráfego que na rede: todo o processamento OLAP
acontece na máquina cliente;
Sem sobrecarregar o servidor de banco de dados: como
todo o processamento acontece na máquina cliente, o
servidor fica menos sobrecarregado.
Desvantagem:
Limitação do cubo de dados: o tamanho do cubo de dados
não pode ser muito grande, caso contrário, a análise
passa a ser demorada e/ou a máquina do cliente pode não
suportar em função de sua configuração.
Termos-chave:
Pouco tráfego que na rede;
Sem sobrecarregar o servidor de banco de dados;
Limitação do cubo de dados.
Síntese das arquiteturas em
Desempenho, Escabilidade e
Custo
Síntese das arquiteturas em Desempenho, Escabilidade e
Custo
Síntese das arquiteturas em
Termos-chave
Síntese das arquiteturas em Termos-chave
Mapa Mental
Mapa Mental de Data Warehouse - Arquiteturas OLAP
Autor: Rogério Araújo