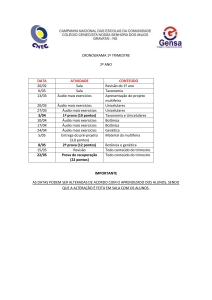
Universidade Federal do Paraná
Centro Politécnico
Curso de Engenharia Elétrica
COMPRESSÃO DE ÁUDIO – MP3
MARINA HELENA KRISAM RODRIGUES MATIELLI
Trabalho como parte de critérios
da disciplina de “Processamento
Digital de Sinais I”
Professor: Marcelo Rosa
UFPR
24/06/2007
Índice
1. Introdução...............................................................................................................pg.03
2. MP3 (MPEG-1 Audio Layer 3)..............................................................................pg.03
2.1. Características da Audição Humana................................................................pg.03
3. Codificadores por Forma de Onda e Perceptuais...................................................pg.05
3.1 Codificadores por Forma de Onda....................................................................pg.05
3.2 Codificadores Perceptuais................................................................................pg.05
4. Codificação de Áudio MP3....................................................................................pg.05
4.1 Banco de filtros................................................................................................pg. 06
4.2 DCT e MDCT ..................................................................................................pg.06
4.3 Modelo Psico-Acústico.....................................................................................pg.07
4.4 Quantificação e codificação..............................................................................pg.08
4.5 Formatação do "Stream" de Bits.......................................................................pg.09
4.6 Codificação Huffman.......................................................................................pg.09
5. Decodificação.........................................................................................................pg.10
6. Conclusão...............................................................................................................pg.11
7. Referências Bibliográficas......................................................................................pg.12
2
1. Introdução
Esse trabalho visa mostrar algumas características da compressão de áudio
principalmente da que conhecemos como mp3.
O ouvido humano tem a capacidade de ouvir freqüências de 20 a 20 kHz, freqüências
acima ou abaixo dessa faixa, ou até perto de 20 ou de 20 kHz não são detectadas pelo
ouvido humano. A principal técnica de compressão do mp3 visa suprimir essas partes
que o ouvido humano não consegue detectar. Isso pode reduzir em até 10 vezes o
tamanho de um arquivo.
O maior interesse hoje, é de salvar o áudio de forma digital, pois esse apresenta muitas
vantagens em relação ao formato analógico, tais como melhor qualidade de áudio,
facilidade de processamento e menor consumo de largura de banda.
Áudio codificado a uma freqüência de amostragem de 44.1 kHz, 16 bits por amostra,
estéreo (qualidade de CD) usa 44100x16x2 = 1.411.200 bits por segundo. Isto significa
que para transmitir tal arquivo por uma rede, é necessária uma largura de banda de 1,41
Mbits/s. Uma música de três minutos (180 segundos) de áudio nestas condições usa
180x44100x16x2 = 254.016.000 bits, ou mais de 30 MB de armazenamento no
computador. Estes dois exemplos dão uma idéia da importância da compressão de som.
2. MP3 (MPEG-1 Audio Layer 3)
A sigla MP3 é uma abreviação de MPEG Audio Layer-3. O "layer" poderia ser
definido como o nível da evolução do esquema de codificação de áudio (codec): quanto
maior, mais recente, e conseqüente redução da dimensão dos arquivos de som,
mantendo ou melhorando a qualidade de áudio. Assim sendo, MP3 é a mesma coisa que
MPEG-3, o MP3 faz parte do padrão MPEG.
O MP3 é um tipo de compressão de áudio com perda de dados, porém, essa perda é
praticamente imperceptível ao ouvido humano, pois utiliza-se dos conhecimentos das
imperfeições ou limitações da audição humana para eliminar informações do arquivo
sem afetar o que ouvimos. Assim, o MP3 consegue níveis de compressão de até 12
vezes.
2.1. Características da Audição Humana
O MP3 se baseia nas características da audição humana para comprimir arquivos. A
utilização dessas características se baseia em 3 princípios básicos:
- Faixa de freqüência audível dos seres humanos;
- Limiar de audição na faixa de freqüência audível;
- Mascaramento em freqüência e mascaramento temporal.
- Faixa de Freqüência Audível dos Seres Humanos: O ouvido humano só pode
detectar sons em uma faixa de freqüência que varia de 20 Hz a 20 kHz, como citado
anteriormente, porém essa faixa pode variar de indivíduo a indivíduo e também com a
idade, pois com o envelhecimento perde-se a capacidade de ouvir freqüências mais
3
altas. Assim, o MP3 utiliza-se desta limitação para comprimir áudio, pois não há
porque armazenar sons que não estejam dentro desta faixa que o ouvido humano é capaz
de detectar, pois se forem reproduzidos, não serão detectados por um ser humano.
Esta limitação permite ao MP3 alcançar altas taxas de compressão. De acordo com o
Teorema de Nyquist, para garantir a reprodução de um sinal, a freqüência de
amostragem tem de ser pelo menos duas vezes sua freqüência máxima. Neste caso, a
freqüência máxima é a freqüência máxima de capacidade de detecção do ouvido
humano, 20 kHz, e a freqüência de amostragem, segundo Nyquist, será 40 kHz. Na
prática, utiliza-se uma freqüência de amostragem de 44100 kHz, pois levam-se em
consideração 10% de tolerância e busca-se um valor produto dos quatro primeiros
números primos. (Obs. (2x3x5x7)^2 = 44100).
Assim, esta taxa de amostragem funciona como um filtro passa-baixas, removendo
todas as componentes de freqüência fora da faixa de interesse, neste caso, acima de 20
kHz.
- Limiar de Audição na Faixa de Freqüência Audível: O ouvido humano só pode
detectar sons dentro da faixa de freqüência de 20 Hz a 20 kHz, mas apesar disso, a
sensibilidade para sons dentro desta faixa não é uniforme, ou seja, a percepção da
intensidade do som varia com a freqüência em que o som se encontra. Esta
característica do ouvido humano é o Limiar de Audição, que é uma curva de percepção
da audição humana dentro da faixa de freqüências audíveis.
Assim, para comprimir áudio, o MP3 descarta amostras que se encontram abaixo deste
limiar.
- Mascaramento em Freqüência e Mascaramento Temporal: O mascaramento
auditivo é definido como a "audibilidade diminuída de um som devido à presença de
outro", ou seja, o ouvido humano só tem capacidade de detectar um som se houver dois
simultâneos.
O mascaramento em freqüência, também chamado mascaramento simultâneo, é
explicado melhor com um exemplo. Se tiver um som forte com uma freqüência de 1000
Hz, e também um som na freqüência de 1100 Hz que está a 18 dB por baixo do anterior,
o som de 1100 Hz não pode ser ouvido porque está sendo mascarado pelo som mais
forte de 1000 Hz. Isto ocorre porque o som de 1000 Hz é mais forte e está perto em
freqüência. Quanto mais perto em freqüência estão, mais fortes são os sons que podem
ser mascarados pelo som mais forte.
O mascaramento temporal ocorre antes e depois de um som forte. Se um som é
mascarado depois de um som mais forte é chamado pós-mascaramento, e se é
mascarado antes em tempo é chamado pré-mascaramento. O pré-mascaramento existe
só por um curto momento (20 ms). O pós-mascaramento tem efeito até por 200 ms.
4
3. Codificadores por Forma de Onda e Perceptuais
3.1 Codificadores por Forma de Onda
Este tipo de codificador tenta reconstruir o sinal tão exatamente quanto seja possível
depois de codificar e decodificar.
3.2 Codificadores Perceptuais
Este tipo de codificador é o mais utilizado pelo modelo MPEG, pois ao contrário dos
codificadores por forma de onda, não tentam manter o sinal exatamente como era antes
da codificação e decodificação, simplesmente tentam assegurar que o som seja
percebido pelo ouvido humano como o som original que foi comprimido. Para isso,
utiliza-se das características da audição humana já citadas anteriormente, eliminando
parte do sinal que o ouvido humano não pode perceber.
Os codificadores perceptuais transformam o som do domínio do tempo para o domínio
da freqüência, separam as diferentes freqüências em sub-bandas, e, depois, eliminam
informações não necessárias com base nas características da audição humana. A
característica mais explorada é o efeito de mascaramento.
4. Codificação de Áudio MP3
A codificação de MP3 é um processo que transforma áudio PCM em áudio com
qualidade razoável e tamanho significamente reduzido. A entrada de áudio é
transformada frame por frame de componentes no domínio do tempo para componentes
no domínio da freqüência pela Transformada Rápida de Fourier (FFT) e depois passada
no sistema de Mascaramento de Freqüências, esse processo é o processo do Modelo
Psico-Acústico, que determina o limiar de mascaramento de cada sub-banda.
Ao mesmo tempo o áudio é enviado ao bloco de transformação híbrido, que possui um
Banco de Filtros, que separa o sinal em 32 sub-bandas, e então passa o sinal pelo
sistema de MDCT (Transformada Discreta Cosseno Modificada) para compensar a
baixa precisão do banco de filtros e comprimir o sinal em uma faixa de poucas
freqüências.
A saída do sistema de transformação hibrida é enviada ao sistema de codificação da
seqüência de bits, que quantifica os valores espectrais e conta o número de bits do
código de Huffman necessário para codificar os valores. A codificação de Huffman é
escolhida como a ferramenta codificadora sem perdas. No caso do ruído de
quantificação exceder o limiar de mascaramento, o MP3 amplifica o fator de escala da
energia da sub-banda espectral.
No sistema de controle de distorção, há o ajuste da sub-banda espectral para regular a
qualidade e então, a informação é unida com o áudio comprimido para resultar em
arquivo MP3 válido.
A quantificação está exemplificada na figura a seguir.
5
Figura 1: Visão Geral da Codificação do MP3.
4.1 Banco de Filtros
Um banco de filtros é um arranjo de filtros passa-banda que separa o sinal de entrada de
áudio em 32 sub-bandas. É desejável projetar o banco de filtros de uma forma que as 32
sub-bandas possam ser recombinadas para recuperar o sinal original.
Estas sub-bandas estão igualmente separadas em freqüência, e não representam
exatamente as bandas críticas do ouvido.
O banco de filtros utiliza a propriedade da seletividade de freqüência limitada do ouvido
humano, que varia em precisão de menos de 100 Hz para as freqüências audíveis mais
baixas, até mais de 4 k Hz para as mais altas, assim, o espectro audível pode ser
particionado em bandas críticas que representam a seletividade do ouvido humano.
Ele serve para isolar diferentes componentes de freqüência de um sinal, podendo então
codificar freqüências mais importantes com uma resolução ótima e as menos
importantes com uma resolução mais baixa. As pequenas diferenças nessas freqüências
são significativas e então deve ser usado um esquema de codificação que preserve estas
diferenças, porém, as freqüências menos importantes não precisam ser exatas, e pode
então, ser utilizado um esquema de codificação mais rude.
O processo layer III utiliza na saída do banco de filtros a Transformada Discreta
Cosseno Modificada (MDCT) para compensar a baixa precisão do banco de filtros.
4.2 DCT e MDCT
A DCT é freqüentemente usada em processamento de sinal e imagem, especialmente
pela compressão de dados com perdas, pois tem uma forte propriedade de “energia de
compactação”: a maior parte da informação do sinal tende a ficar concentrada em
algumas poucas componentes de baixa freqüência da DCT.
Por isso, a DCT é usada em compressão de imagem JPEG, MJPEG, MPEG, e
compressão de vídeo DV. A MDCT é usada em AAC, Vorbis e compressão de áudio
MP3.
6
A figura a seguir, mostra uma imagem comprimida com DCT e com DFT. Para ambas
as transformadas, há a magnitude do espectro à esquerda e o histograma à direita. A
DCT concentra a maior parte do sinal nas baixas freqüências.
Figura 2: DCT comparada à DFT.
4.3 Modelo Psico-Acústico
Este modelo é usado para determinar a qualidade de uma implementação dada do
codificador. Ele realiza duas funções: decide que tipo de bloco usar e calcula a taxa
sinal-a-máscara, que é o valor do sinal na banda dividido pelo limiar de mascaramento.
Ele primeiro converte o áudio do domínio do tempo para o domínio da freqüência,
usando a FFT para obter uma boa resolução de freqüência para o cálculo correto dos
limiares de mascaramento. A saída da FFT é usada primeiramente para analisar que tipo
de sinal está sendo processado.
Um sinal estacionário faz com que o modelo escolha um bloco longo e um sinal mais
transitório resulta em um bloco curto. O tipo de bloco é usado depois na parte da MDCT
do algoritmo.
A saída do modelo então, consiste dos valores para os limiares de mascaramento ou
ruído permitido para cada sub-banda, que são aproximadamente equivalentes às bandas
críticas da audição humana. Existe ruído de quantificação num sinal digital devido à
existência de um número limitado de valores discretos para representar o sinal original.
7
Se o ruído de quantificação pode ser mantido abaixo do limiar de mascaramento para
cada sub-banda, então o resultado da compressão não deveria ser distinguido do sinal
original.
4.4 Quantificação e Codificação
A quantificação é feita por um quantificador de lei de potência, que automaticamente
codifica os valores maiores com menos exatidão. Os valores que foram quantificados
são codificados por codificação Huffman, que adapta a codificação às diferentes
estatísticas locais dos sinais musicais.
No processo de obtenção do MP3, deve-se determinar um valor de ganho global (que
determina o tamanho do passo da quantificação) e os fatores de escala (que determinam
fatores da forma do ruído para cada sub-banda), que devem ser aplicados antes da
quantificação real.
O processo de achar o ganho e os fatores de escala de cada banda ótimos para um bloco,
taxa de bits e saída a partir do modelo perceptual é feito pelos dois seguintes laços de
iteração aninhados:
- Laço de iteração interior (laço da taxa de bits):
No laço de iteração interior, se o número de bits resultante da codificação exceder o
número de bits disponível para codificar um bloco de dados, ajusta-se o valor de ganho
global para resultar em um passo de quantificação maior, que leva a valores
quantificados menores. Repete-se esta operação até que se consiga uma demanda de bits
para a codificação Huffman suficientemente pequena.
- Laço de iteração exterior (laço de controle de ruído):
Este laço é executado para que o ruído fique abaixo do limiar de mascaramento para
cada banda crítica. Para isso, são aplicados fatores de escala a cada sub-banda,
começando com o valor de fator de escala igual a 1. Se o ruído de quantificação for
maior que o ruído permitido para cada sub-banda, ajusta-se o fator de escala desta subbanda para reduzir este ruído.
Para se conseguir um ruído menor de quantificação, é necessário um maior número de
passos de quantificação e consequentemente, uma taxa de bits mais alta. Então, o laço
de iteração interior deve ser repetido toda vez que forem usados novos fatores de escala.
O laço interior sempre converge (no caso extremo, fazendo o passo de quantificação o
suficientemente grande para zerar todos os valores espectrais).
O laço exterior pára quando alguma das seguintes condições se cumpre:
1. Nenhuma das bandas tem demasiado ruído (o laço converge).
2. A próxima iteração amplificaria uma das bandas mais do o que é permitido.
3. Todas as bandas dos fatores de escala terem sido amplificadas pelo menos uma
vez.
8
4.5 Formatação do "Stream" de Bits
O último passo no processo de codificação é produzir um "stream" de bits de acordo
com o padrão MPEG.
O formatador de bits armazena o áudio codificado e alguns dados adicionais em quadros
(frames), onde cada quadro contém informação de 1152 amostras de áudio por canal.
Um quadro consiste de um cabeçalho e dados de áudio junto com teste de erros e dados
subordinados opcionais. O cabeçalho descreve entre outras coisas, qual camada (layer),
taxa de bits e freqüência de amostragem estão sendo usadas pelo áudio codificado.
4.6 Codificação Huffman
A codificação Huffman se baseia no comprimento e na freqüência de ocorrência dos
caracteres do áudio a ser codificado. Os dados codificados por Huffman e a sua
informação colateral são colocados na parte de dados de áudio, e a informação colateral
especifica que tipo de bloco, tabelas de Huffman e fatores de ganho das sub-bandas
usar.
O esquema de Huffman utiliza uma tabela de freqüência de ocorrências para cada
símbolo (ou caractere) na entrada. Esta tabela pode ser derivada da própria entrada ou
de dados que são representativos da entrada.
Para poder atribuir aos caracteres mais freqüentes os códigos binários de menor
comprimento, constrói-se uma árvore binária baseada nas probabilidades de ocorrência
de cada símbolo.
Nesta árvore, as folhas representam os símbolos presentes nos dados, associados com
suas respectivas probabilidades de ocorrência; os nós intermediários representam os
símbolos presentes em suas subárvores e a raiz representa a freqüência de todos os
símbolos no conjunto de dados.
O processo de codificação se inicia unindo dois símbolos de menor freqüência que
estejam unidos em um nó ao qual é atribuída a soma de suas freqüências. Forma-se
então um novo nó, que é tratado como se fosse um dos símbolos do alfabeto e
comparado com os demais de acordo com sua freqüência. Esse processo é repetido até
que todos os símbolos estejam unidos sob um único nó.
As arestas da árvore são associadas a um dos dígitos binários (0 ou 1), O código
correspondente a cada símbolo é então determinado percorrendo-se a árvore e anotandose os dígitos das arestas percorridas desde a raiz até a folha que corresponde ao símbolo
desejado.
O algoritmo para construção desta árvore é o seguinte:
9
enquanto tamanho(alfabeto) > 1:
S0 := retira_menor_probabilidade(alfabeto)
S1 := retira_menor_probabilidade(alfabeto)
X := novo_nó
X.filho0 := S0
X.filho1 := S1
X.probabilidade := S0.probabilidade + S1.probabilidade
insere(alfabeto, X)
fim enquanto
X = retira_menor_símbolo(alfabeto) # nesse ponto só existe um símbolo.
para cada folha em folhas(X):
código[folha] := percorre_da_raiz_até_a_folha(folha)
fim para
Figura 3: Algoritmo para construção da árvore de Huffman.
Um exemplo de árvore binária de Huffman é mostrado na figura a seguir:
Figura 4: Árvore de Huffman
5. Decodificação
O processo de decodificação de um arquivo MP3 consiste em três fases: decodificação
de seqüência de bits, desquantificação e mapeamento freqüência – tempo.
A fase de decodificação de seqüência de bits sincroniza a seqüência de bits codificada e
outras informações de cada frame, dando como resultado os códigos de bits de
Huffman, as informações de decodificação de Huffman e as informações de fator de
escala para a próxima fase.
No processo de desquantificação, os coeficientes de freqüência gerados pelo bloco de
MDCT na codificação são reconstruídos, e então os cálculos de desquantificação são
baseados na saída de decodificação de Huffman e na informação do fator de escala.
10
As informações são utilizadas na última fase, que realiza uma série de operações de
MDCT inversa e uma análise do filtro de sub-banda no codificador. Reduzindo os
blocos de aliasing, o sistema põe mais componentes nos coeficientes desquantificados,
assim, pode-se obter uma reprodução mais correta da análise do filtro de sub-banda.
Aplica-se a inversão de freqüência para compensar a redução do número de amostras
usado na análise do filtro de sub-banda. Depois, um filtro de sub-banda sintetizado é
aplicado aos sinais para resultar na saída de áudio PCM.
A figura a seguir mostra estes processos.
Figura 5: Processo de Decodificação.
6. Conclusão
Utilizando essas técnicas de compressão, o MP3 consegue níveis de compressão que
ascendem até 90% do sinal digital. Para atingir estes níveis de compressão o MP3
aproveita, além das técnicas habituais de compressão, o conhecimento das imperfeições
ou limitações na audição, para eliminar aquilo que não é relevante ao ouvido humano.
Então, o MP3 pode ser considerado como um bom padrão de compressão de áudio com
perdas, pois para a maioria dos seres humanos as perdas são imperceptíveis e utilizandose das limitações do ouvido humano, consegue eliminar uma grande parte do sinal,
fazendo com que ele fique com um tamanho muito reduzido em relação a outros
padrões de compressão de áudio. Só as pessoas com ouvido absoluto vêem a diferença.
Ou seja, para a maioria das pessoas é uma compressão satisfatória.
11
7. Referências Bibliográficas
http://en.wikipedia.org/wiki/Discrete_cosine_transform#Informal_overview
http://www.img.lx.it.pt/~fp/cav/ano2006_2007/MEEC/Trab_15/CAV_MP3/pages/que
stoestecnicas.html
http://en.wikipedia.org/wiki/Modified_discrete_cosine_transform
http://en.wikipedia.org/wiki/Huffman_coding
http://en.wikipedia.org/wiki/Psychoacoustic
http://www.img.lx.it.pt/~fp/cav/ano2006_2007/MEEC/Trab_1/Paper_MP3.pdf
12