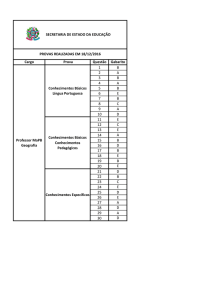
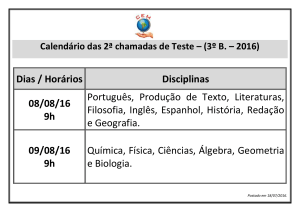
ANÁLISE DE DESEMPENHO DE BANCO DE DADOS DE CÓDIGO ABERTO JUNTO A
TECNOLOGIA JAVA PARA ARMAZENAMENTO E RECUPERAÇÃO DE IMAGENS
MÉDICAS
Gil Mendes Carelli1, Lucas Venezian Povoa2, Luciana Brasil Rebelo dos Santos3
1 Graduando em Tecnologia em Análise e Desenvolvimento de Sistemas, Bolsista PIBIFSP, IFSP, Câmpus Caraguatatuba,
[email protected].
2 Mestre em Ciência da Computação, Orientador, Professor, IFSP, Câmpus Caraguatatuba, [email protected].
3 Doutora em Computação Aplicada, Professora, IFSP, Câmpus Caraguatatuba, [email protected].
Área de conhecimento (Tabela CNPq): Banco de Dados – 1.03.03.03-0
Apresentado no
7° Congresso de Iniciação Científica e Tecnológica do IFSP
29 de novembro a 02 de dezembro de 2016 - Matão-SP, Brasil
RESUMO: Sistemas de Informação da Saúde demandam alto volume de armazenamento e grande
poder de processamento para lidar com imagens médicas, como por exemplo, tomografias mamárias e
radiografias. Este artigo apresenta a comparação de desempenho entre sistemas de banco de dados
Relacional e Chave-Valor juntos a tecnologia Java para armazenamento e recuperação de imagens
médicas, em especial tomografias mamárias.
PALAVRAS-CHAVE: SQL; NoSQL; orientação a objetos; saúde, tomografia.
PERFORMANCE ANALYSIS OF OPEN SOURCE DATABASES WITH JAVA FOR
MEDICAL IMAGE PERSISTENCE AND RETRIEVAL
ABSTRACT: Health information systems require high-volume storage and high processing power to
handle medical images, This paper presents the parcial results of a research developed in order to
analyse and compare open source database management systems and programming language to store
and retrive medical images.
KEYWORDS: SQL; NoSQL; object oriented ; healthcare, tomography.
INTRODUÇÃO
Picture Archiving and Communication Systems (PACS) [1] é um tipo de sistema de
informação proveniente do domínio da Saúde, o qual possui a finalidade de captar, armazenar,
transmitir e apresentar imagens digitais (e.g., tomografia mamária, radiografia) e informações
relacionadas (e.g., dados demográficos, relatórios de diagnostico, histórico clínico).
PACSs lidam diretamente com tipos de dados que exigem alto poder de processamento e
grande capacidade de armazenamento. i.e., imagens médicas como tomografias e radiografias.
Desenvolver sistemas que lidam com esse tipo de dado atendendo o requisito não funcional de rápido
tempo de resposta é um desafio intrínseco e está diretamente relacionado às tecnologias adotadas [2].
Nos últimos anos, diversos tipos de modelos de banco de dados, e naturalmente sistemas
gerenciadores baseados nesses, surgiram com propostas completamente diferentes do modelo
relacional e da SQL. Dessa forma, foram estabelecidos três principais grupos de banco de dados
denominados SQL, NoSQL e NewSQL, os quais buscam prover, principalmente, funcionalidades
com a maior efciência possível.
O objetivo deste resumo é apresentar a análise de desempenho entre os sistemas de banco de
dados de código aberto PostgreSQL e MongoDB junto a tecnologia Java para o armazenamento de
tomografias mamárias. O restante deste artigo está assim organizado. A Seção 2 descreve os
métodos e ferramentas empregados para as análises. A Secão 3 apresenta os resultados obtidos e a
comparação entre o desempenho dos banco de dados. Finalmente, a Seção 4 expõe as considerações
finais e aponta alguns trabalhos futuros.
MÉTODOS E FERRAMENTAS
Para o desenvolvimento deste resumo foi utilizada a tecnologia Java 8 [3]. Os sistemas
gerenciados de banco de dados analisados foram PostgreSQL 9.3.13 [4] e Mongodb 2.4.9 [5]. Foi
utilizada a versão stable de cada banco de dados adequada para o sistema operacional utilizado nos
testes.
O ambiente para a realização dos testes foi composto por uma máquina virtual com o sistema
operacional Ubuntu Desktop 14.04 LTS com 2 GB de memória RAM, 20 GB de HD e 2 núcleos de
processamento operando a 2.83 GHz. O computador hospedeiro da máquina virtual também utiliza
Ubuntu Desktop 14.04 LTS com 6 GB de memoria RAM, HD SATA de 500GB e um processsador de
4 núcleos operando a 2.83 GHz.
Para a realização dos testes foi desenvolvido um framework [6] com a tecnologia Java capaz
de persistir imagens médicas. A Figura 1 ilustra o diagrama de classes UML que representa a
arquitetura do framework desenvolvido utilizando o padrão Model, View, Control (MVC) [7].
Figura 1: Diagrama de classes UML do framework desenvolvido e utilizado para as análises de desempenho.
As classes pertencentes à camada database foram desenvolvidas utilizando o driver versão
9.4.1208 [8] para a conexão com o banco de dados PostgreSQL e a versão 3.2.2 [9] para o banco de
dados Mongodb. Essas classes são responsáveis pela interação com os sistemas de banco de dados.
Na camada model foi criada a classe para representar as imagens médicas, utilizando um
número de identificador único, o nome da imagem e um Array de bytes contendo a informação binária
da imagem.
A camada dao para a persistência das imagens foi desenvolvida utilizando o padrão Data
Access Object (DAO) [10]. As classes dessa camada recebem o objeto da camada model, preparam as
instruções de persistência e as passam para a camada database executar.
Na camada control foi criada a classe que recebe os parâmetros de configuração no momento
da execução do programa. Essa classe é responsável por verificar os argumentos inseridos, validando
os mesmos e passando para a camada service o comando que deve ser executado pelo programa.
A camada service conta com uma classe responsável por receber o comando a ser executado,
requisita uma conexão com o banco de dados escolhido e passada para a camada dao os objetos
necessários para a persistência de uma ou mais imagens.
Nos testes de persistência foram realizadas inserções sequenciais com uma, duas, quatro e oito
imagens em uma mesma transação. Cada teste foi executado cem vezes, sendo que entre cada
execução foi realizada a limpeza do cache da memória RAM e da área de swap do sistema
operacional. A métrica de desempenho adotada foi o tempo de execução medido em milissegundos, o
qual foi coletado com a ferramenta time [11].
As seguintes etapas foram completadas na realização de cada teste: definição do sistema de
Banco de Dados a ser testado, definição e validação dos dados que serão utilizados, execução e
finalização do teste. Para cada teste excutado o sistema de Banco de Dados é reiniciado, é feita a
marcação do tempo de execução da operação de persistência e seu resultado salvo em um arquivo
externo e o teste finalizado. O teste é interrompido e finalizado caso os dados escolhidos não sejam
válidos.
RESULTADOS E DISCUSSÕES
Os testes foram realizados com dois sistemas gerenciadores de banco de dados, PostgreSQL
(pgsql) e MongoDB (mongo). Cada sistema gerenciador foi testado em quatro baterias diferentes,
sendo que cada bateria foi composta por cem execuções. Cada bateria utilizou em suas execuções uma,
duas, quatro e oito imagens, respectivamente.
O Figura 2 apresenta os histogramas das quatro diferentes baterias em conjunto de cada
sistema gerenciador utilizado. Os resultados mostram que a maioria dos tempos de execução do pgsql
foram inferiores aos tempos de execução do mongo. Além disso, grande parte dos resultados se
concentrou no intervalo entre 0,35 e 0,45 segundos para o pgsql e entre 0,50 e 0,75 segundos para o
mongo.
Figura 2: Histogramas contemplando os tempos de execução em segundos das quatro diferentes baterias de cada
sistema gerenciador de banco de dados.
A Tabela 1 apresenta as medidas de centralidade e dispersão das amostras coletadas de cada
sistemas gerenciador. De forma geral é possível notar o menor tempo de execução obtido pelo pgsql
com média de 0,45 segundos ao passo que o mongo teve tempo médio de 0,76 segundos. Além da
superioridade no tempo médio, o pgsql também apresenta maior estabilidade nas operações de
inclusão de dados, com desvio-padrão de 0,09 contra 0,15 do mongo. Também é possível notar que
pior tempo de execução do pgsql é igual ao melhor tempo de execução mongo.
Tabela 1: Medidas de centralidade e dispersão das amostras dos tempos de execução das baterias realizadas para
cada sistema gerenciador de banco de dados empregado.
Banco de Dados
Média
Desvio-Padrão
Máximo
Mínimo
PostgreSQL
0.45
0.09
0.60
0.34
MongoDB
0.76
0.15
1.52
0.60
Para gerar maiores evidências das diferenças no tempo de execução dos dois sistemas de
banco de dados foi realizado um teste de hipótese t-Student utilizando um nível de confiância de 5%
para confrontar estatisticamente as duas amostras. O teste resultou no valor p igual a 1, o que define a
aceitação da hipótese nula definida como a média do pgsql menor ou igual a média do mongo.
CONSIDERAÇÕES FINAIS E TRABALHOS FUTUROS
Este resumo apresenta a análise de desempenho de dois sistemas de banco de dados de código
aberto, PostgreSQL e MongoDB, para o armazenamento de imagens médicas. O PostgreSQL
apresentou média de tempo de execução inferior a média do MongoDB, além de um desvio-padrão
inferior. Esses dados evidenciam que o primeiro sistema gerenciador possui melhor desempenho na
inserção de imagens médicas com melhor estabilidade, i.e., menor variação nos tempos de execução.
Como trabalhos futuros serão adicionados mais sistemas gerenciadores de banco de dados
com diferentes abordagens, como por exemplo, orientado a grafo, chave-valor e BigTable. Além disso,
serão realizado testes com diferentes linguagens de programação junto as implementações de
referência do seu ambiente de execução.
AGRADECIMENTOS
Os autores agradecem o suporte financeiro parcial dado pelo Instituto Federal de Educação,
Ciẽncia e Tecnologia de São Paulo (IFSP) por meio de bolsa de Inciação Científica Institucional.
REFERÊNCIAS
[1] H. OOSTERWIJK,PACS fundamentals, OTech, 2004.
[2] S. R. Delfino, L. V. Povoa, and A. C. R. Pinto, Análise de persistência de imagens médicas:
uma comparação entre os sistemas de bancos de dados mysql, postgresql e derby, Retec-Revista
de Tecnologias, vol. 5, no. 1, pp. 7-13, 2012.
[3] Oracle
Corporation
and
its
Aliates,
Openjdk,
<http://goo.gl/H2dGJ5>. Acessado em: 10 de julho de 2016.
[4]
The PostgreSQL Global Development Group,
Postgresql,
<https://goo.gl/JoXYQ2>. Acessado em: 10 de julho de 2016.
2016.
Disponível em:
2016. Disponível em:
[5] MongoDB, Inc., Mongodb, 2016. Disponível em: <https://goo.gl/Ou875h>. Acessado em: 10 de
julho de 2016.
[6] G. M. Carelli and L. V. Povoa, Medical Database Analysis Framework, 2016. [Online].
Available: https://goo.gl/e0FpJz
[7] G. Moreira, N. Steppat, F. King, G. Silveira, S. Lopes, P. Silveira. Introdução a Arquitetura e
Design de Software, Campus, 2012.
[8] The PostgreSQL Global Development Group, PostgreSQL JDBC Driver, 2016. Disponível em:
<https://goo.gl/j4K4t5>. Acessado em: 10 de julho de 2016.
[9] MongoDB,
Inc., Mongodb Java Driver, 2016. Disponível em: <https://goo.gl/yIfO1X>.
Acessado em: 10 de julho de 2016.
[10] J. JENKOV, DAO, 2016. Disponível em: <http://goo.gl/Mc5Bte>. Acessado em: 10 de julho de
2016.
[11] GNU. time, 2016. Disponível em: <http://goo.gl/UkRHYZ>. Acessado em: 10 de julho de 2016.