Descoberta de Conhecimentos sobre o Perfil
do Candidato ao Vestibular da Unisinos,
Utilizando Técnicas de Data Mining
Carla Medeiros da Silva
Universidade do Vale do Rio dos Sinos
Trabalho de Conclusão de Curso - 2001/2
Curso de Informática - Hab. em Análise de Sistemas
Apresentação
Introdução
Objetivo Geral
Processo de Descoberta de
Conhecimentos em Banco de
Dados
Tipos de Padrões
Medidas de Interesse
Regras de Associação
Árvores de Decisão
Base de Dados
Ferramenta Desenvolvida
Fases do Processo de KDD - Regras
de Associação
Fases do Processo de KDD - Árvores
de Decisão
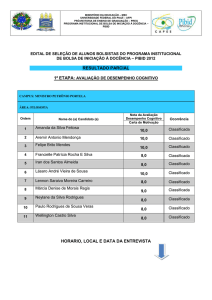
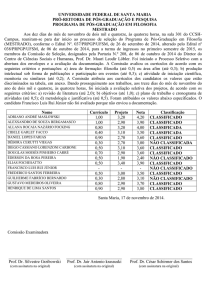
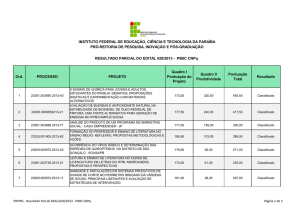
Resultados - Regras de Associação
Resultados - Árvores de Decisão
Comparativo entre as Duas Técnicas
Conclusão
Bibliografia
1
Introdução
Atualmente, as organizações têm armazenado uma grande quantidade
de dados, onde pode conter muitas informações úteis e importantes,
mas que normalmente não estão visíveis e não podem ser
descobertas utilizando-se sistemas convencionais de análise de
dados.
A mineração de dados é um processo de descoberta de
conhecimentos que tem por objetivo extrair essas informações
implícitas e potencialmente úteis.
A mineração de dados está fortemente ligada a técnicas de
aprendizado de máquina, tais como Árvores de Decisão, Redes
Neurais Artificiais, Regras de Associação e Agrupamento de Dados
(Clusterização).
Objetivo Geral
Aplicar de forma prática, sobre uma base de dados de
candidatos ao vestibular da Unisinos de 2000/1, duas
técnicas de Data Mining:
Regras de Associação
(Apriori)
Árvores de Decisão
(C4.5)
Descobrir conhecimentos para
ajudar a traçar o perfil dos
candidatos e descobrir quais as
características mais relevantes
que os levam a classificarem-se
ou não e matricularem-se ou não.
Análise comparativa entre as duas
ferramentas (Apriori e C4.5)
2
Processo de Descoberta de Conhecimentos em
Banco de Dados
O termo Descoberta de Conhecimentos em Banco de Dados
(DCBD), ou Knowledge Discovery in Databases(KDD) foi criado
para nomear o amplo processo de encontrar conhecimentos a
partir de dados brutos.
Consiste em várias etapas envolvendo a cooperação da pessoa
responsável pela análise dos dados.
Este processo, com freqüência não é executado de forma
seqüencial.
Processo de descoberta de conhecimentos em
Banco de Dados
Dados
Seleção
Pré-processamento
Seleção: selecionar e coletar o conjunto de dados
ou o subconjunto de variáveis necessárias.
Pré-processamento: limpeza dos dados,
removendo ruídos e tratando dados incompletos.
Transformação: converter os dados para um
formato apropriado.
Transformação
Data Mining: aplicação do algoritmo escolhido
sobre os dados.
Data Mining
Pós-processamento: tratamento das regras
extraídas na etapa anterior antes que elas sejam
apresentadas ao analista.
Pós-processamento
Interpretação
Interpretação: as informações resultantes do
processo são interpretadas e avaliadas,
constituindo-se em conhecimento.
Conhecimento
3
Tipos de Padrões
• Os objetivos da Mineração de Dados são a
predição e a descrição:
– Predição:
Predizer o valor futuro ou desconhecido de um atributo com
base em valores conhecidos de outros atributos da base de
dados.
– Descrição:
Encontrar padrões interessantes que estão implícitos na base
de dados.
Tipos de Padrões
– Padrões descritivos:
• Agrupamento ou Clustering: agrupar objetos em categorias ou
grupos baseados em algum critério de similaridade, de forma a
identificar aglomerações que descrevem os dados.
• Regras de Associação: encontrar relacionamentos ou padrões
freqüentes entre um conjunto de dados.
• Padrões seqüenciais: descrevem a tendência de que certos eventos
aconteçam obedecendo a uma determinada seqüência temporal.
4
Tipos de Padrões
– Padrões preditivos
• Regressão: procura-se mapear cada entidade para um valor
numérico, usando os valores existentes para prever valores
futuros.
• Classificação: examinar as características de um objeto e
atribuí-lo a um conjunto de classes predefinidas. (Árvores de
Decisão).
Medidas de Interesse em Mineração de Dados
Medidas para avaliar o quanto um padrão é bom
e/ou interessante:
– Objetivas:
» estrutura do padrão e dos dados, independente do domínio
» diminui consideravelmente a quantidade apresentada
» Graus de suporte e confiança
– Subjetivas:
» necessidades específicas e conhecimento prévio do usuário
» utilidade: ajudar a alcançar o objetivo do sistema ou usuário
» inesperabilidade: descobrir padrões surpreendentes
5
Regras de Associação
•
Esta técnica é uma das mais usadas em aplicações clássicas de KDD.
•
Aprendizado não supervisionado.
•
É uma padrão descritivo que representa a probabilidade de um conjunto de itens
aparecer em uma transação visto que outro conjunto de itens está presente.
•
Tem por objetivo encontrar relacionamentos ou padrões freqüentes entre
conjuntos de dados.
•
Dado um conjunto de transações, onde cada transação é um conjunto de itens, a
regra de associação é uma expressão:
X → Y (A transação que contém itens em X tende a conter itens em Y)
Regras de Associação
X→Y
Dentro do conceito de que uma regra é uma afirmação probabilística:
– Suporte é a probabilidade de que uma transação satisfaça X.
– Confiança é a probabilidade de que uma transação satisfaça Y, se ela satisfaz X.
Para que se encontre regras associativas é preciso descobrir todas as regras que
têm suporte e confiança maiores que os valores mínimos, especificados pelo
usuário.
6
Regras de Associação
X→Y
Algoritmo utilizado:
– Apriori (Agrawal): algoritmo para extração de regras de
associação que faz diversas passagens sobre a base de
transações para encontrar todos os conjuntos de itens
freqüentes, gerando no final da execução uma lista de
padrões (regras de associação).
– Exemplo
Regras de Associação - Exemplo
•5 itens de compra
•Suporte mínimo: 10%
•10 transações
•Confiança mínima: 80%
1,2,3
1,4,5
2,3,4
1,2,3,4
2,3
1,2,4
4,5
1,2,3,4
3,4,5
1,2,3
•9 regras de associação
Regra
3←2
2←3
2←1
4←5
3←2
2←3
4←3
2←3
1
1
5
4
Suporte
70.0%
70.0%
60.0%
30.0%
50.0%
40.0%
10.0%
1 20.0%
Confiança
85.7%
85.7%
83.3%
100.0%
80.0%
100.0%
100.0%
100.0%
X→Y
O suporte é um percentual que
determina a ocorrência de 1 item
ou um conjunto de itens no total
de transações. O item 2 ocorre 7
vezes em 10 transações, então
suporte = 70%
A confiança é a ocorrência mútua
de 2 ou mais itens em relação ao
suporte do antecedente da regra.
Os itens 2 e 3 aparecem juntos em
6 das 7 vezes que o item 2 aparece
então confiança = 85,7%
Voltar
7
Árvores de Decisão
Representações simples do conhecimento e são amplamente utilizadas
em algoritmos de classificação.
Aprendizado supervisionado.
Consistem de nodos (atributos), de arcos (provenientes do nodo,
recebem valores possíveis para esses atributos) e de nodos folha
(classes).
Árvores de Decisão - Aplicação
Instâncias representadas por pares do tipo atributo-valor;
Classes predefinidas;
Função objetivo tem uma saída discreta;
Descrições disjuntivas;
Os dados de treinamento podem conter erros;
Os dados de treinamento podem conter atributos com valores desconhecidos;
Dados suficientes.
8
Árvores de Decisão - Aprendizado
O conjunto de instâncias disponíveis é dividido tipicamente em um conjunto de
aprendizado e um conjunto de teste.
=> Questão central do problema de aprendizado de uma árvore de decisão:
Escolher o melhor atributo para ser usado no teste de cada nodo!
Conceitos importantes:
» Ganho de Informação (Information Gain)
» Entropia (Entropy)
A escolha de uma boa ordem dos testes associados aos nodos irá gerar uma boa
árvore: Simples, compacta e se possível com uma boa generalização [Occam’s
Razor].
Ganho de Informação: medida que indica o quanto um dado atributo irá
separar os exemplos de aprendizado de acordo com a sua função objetivo
(classes). Valor numérico - quantifica o ganho.
A = atributo
Ganho(S,A) = Entropia (S) -
N
Σ
v=1
| Sv | . Entropia (Sv)
|S|
N = domínio atributo
Sv = subconjunto de S onde o
atributo A possui valor V
Entropia: medida que indica a homogeneidade dos exemplos contidos em um
conjunto de dados. Permite caracterizar a “pureza” e (impureza) de uma
coleção arbitrária de exemplos.
s
Dado o conjunto S, contendo exemplo ‘+’e ‘-’que definem o conceito a ser
aprendido, a entropia relativa dos dados deste conjunto S é indicada por:
Voltar
Entropia (S) = - P+ . Log2 P+ - P . Log2 P
-
-
P+ = Nº casos positivos / Nº total de casos
P- = Nº casos negativos / Nº total de casos
9
Árvores de Decisão
– Atributos com valores numéricos
– Atributos com valores desconhecidos
– Decorando os dados
– Poda de árvores de decisão
– De árvores para regras: também podem ser representadas como
conjuntos de regras do tipo IF-THEN facilitando a leitura e compreensão
humana.
Uma árvore mais simples deverá ser aquela que melhor deve generalizar os
conceitos aprendidos.
Por isso buscamos simplificar as árvores ao máximo, seja usando a teoria da
informação (entropia e ganho), seja usando técnicas de poda das árvores e
das regras.
Árvores de Decisão
Algoritmo utilizado:
– C4.5 (Quinlan)
• aprimoramento do ID3.
•
.
• Trabalha com valores desconhecidos e valores numéricos.
• Information Gain, Entropy, Gain Ratio (busca a distribuição
ampla e não uniforme dos +/-).
• Poda árvores de decisão e deriva regras.
10
Base de Dados
A escolha da base de dados de candidatos ao vestibular deve-se ao fato de ser
uma base de dados reais e estar disponível eo domínio do problema é conhecido.
– Base bastante completa - 30 tabelas
– Tabela principal - 8.644 registros e 40 atributos
Ferramenta Desenvolvida
11
Fases do Processo de KDD
Regras de Associação
X→Y
Etapas:
– Pré-processamento:
• Algoritmo Apriori não aceita valores indefinidos para os atributos;
• Valores indefinidos ou inválidos (média = 99,99) foram ignorados.
– Transformação:
• O algoritmo não trabalha com valores numéricos contínuos, então os
atributos Idade, Ano conclusão 2grau, Qtde. vest.ant, Qtde vest. ant., Qtde.
vest. periodo, Grau objetivas, Grau redação, Grau total e Media final foram
transformados em valores discretos;
• Tabela principal com dados espalhados em outras tabelas;
• Os dados unificados são gravados na tabela QuadroNorm;
• Metodologia: nomes abreviados mais significativos, com identificação
do atributo;
Fases do Processo de KDD
Regras de Associação
X→Y
• Ainda na etapa de transformação, a ferramenta possibilita definir um subconjunto
de atributos a serem processados;
• Três arquivos texto, são então gerados, no formato apropriado para serem lidos
pelo Apriori:
» todos os candidatos e Classificado ou Não classificado - RA-Todos
» todos os candidatos e Matriculado e Não matriculado - RA-TodosMatricula
» candidatos classificados e Matriculado e Não matriculado - RA-Classificados
Amostra de 10
transações de um
arquivo do tipo
RA-Todos, c/ 5
atributos
selecionados
Publica Diurno FreqCursinho instMae-1Grau SustentoProprio Classificado
Publica Noturno NaoFreqCursinho instMae-Superior SustentoProprio Classificado
Particular Noturno NaoFreqCursinho instMae-1Grau SustentoProprio NaoClassificado
Publica Diurno NaoFreqCursinho instMae-2Grau NaoTrabalha Classificado
Particular Diurno NaoFreqCursinho instMae-1Grau SustentoProprio NaoClassificado
Particular Diurno FreqCursinho instMae-Superior NaoTrabalha Classificado
Publica Diurno NaoFreqCursinho instMae-1Grau SustentoProprio Classificado
Particular Diurno NaoFreqCursinho instMae-2Grau NaoTrabalha Classificado
Particular Diurno FreqCursinho instMae-Superior NaoTrabalha Classificado
Outros Noturno NaoFreqCursinho instMae-1Grau SustentoProprio NaoClassificado
12
Fases do Processo de KDD
Regras de Associação
X→Y
– Data Mining:
• Aplicação do algoritmo Apriori sobre os três arquivos, gerados na etapa anterior;
• Configuração dos parâmetros: limite de confiança e suporte, tamanho mínimo e
máximo das regras e medida de diferença dos graus de confiança das regras.
– Pós-processamento:
• Regras são tratadas através de diferentes métodos, permanecendo as
interessantes;
• Selecionar regras que possuam um determinado conjunto de atributos em seu
antecedente ou conseqüente;
• Seleção baseada no domínio;
• Ordenação das regras: suporte e confiança.
Fases do Processo de KDD
Árvores de Decisão
Etapas:
– Pré-processamento:
• Registros que possuíam ate 2 valores desconhecidos ou inválidos
foram preservados, colocando “?”
• 634 registros eliminados.
– Transformação:
• Tabela principal com dados espalhados em outras tabelas;
• Os dados são unificados, gravados na tabela QuadroNorm2;
• Metodologia: nomes abreviados mais significativos;
13
Fases do Processo de KDD
Árvores de Decisão
• Arquivos requeridos pelo algoritmo:
– de definições: determinam as classes e o nome e domínio de cada atributo
Classificado, NaoClassificado.
Idade:
Tipo 2Grau:
Forma 2Grau:
continuous.
Supletivo, PPT, AtEnsinoMedio, Tecnico/Profiss,
Magisterio, Outro.
Publica, Particular, Outros.
Turno 2Grau:
Nivel Instrucao Mae:
Particip Econ Famil:
Diurno, Noturno, Outro.
Analfabeto, 1Grau, 2Grau, Superior, NaoSei.
NaoTrabalha, SustentoProprio, SustentaFamilia,NaoInformou.
– de dados: cada linha representa uma instância, com classes predefinidas
Amostra de 5
transações de um
arquivo do tipo
AD-Todos, c/ 6
atributos
selecionados
17, ?, Particular, Noturno, 2Grau, NaoTrabalha, Classificado
17, PPT, Publica, Diurno, Superior, NaoTrabalha, Não Classificado
17, Tecnico/Profiss, ?, Diurno, Superior, NaoTrabalha, Classificado
18, AtEnsinoMedio, Particular, Diurno, 2Grau, NaoTrabalha, Classificado
22, Supletivo, ?, Noturno, 1Grau, SustentoProprio, Não Classificado
Fases do Processo de KDD
Árvores de Decisão
• Três tipos de arquivos texto, são então gerados, com os respectivos
arquivos de definições, no formato apropriado para serem lidos pelo C4.5:
» todos os candidatos e Classificado ou Não classificado - AD-Todos
» todos os candidatos e Matriculado e Não matriculado - AD-TodosMatricula
» candidatos classificados e Matriculado e Não matriculado - AD-Classificados
14
Fases do Processo de KDD
Árvores de Decisão
– Data Mining:
• Aplicação do algoritmo C4.5 sobre os três arquivos, gerados na etapa
anterior;
• Nesta mesma etapa, o próprio algoritmo faz a poda da árvore construída.
– Pós-processamento:
• Substituir a árvore de decisão por regras;
• Podar as regras (generalização).
Resultados - Regras de Associação
X→Y
– Problemas:
• grande quantidade de regras geradas;
• valores dos atributos estão bem distribuídos entre candidatos classificados
e não classificados e matriculados e não matriculados;
• é possível identificar tendências, mas não foi possível identificar padrões
realmente interessantes e novos, com alto grau de suporte e confiança;
• muitas regras triviais;
• regras redundantes;
• com limite de confiança alto (80%), os itens Classificado e Não Classificado
e Matriculado e Não Matriculado não aparecem como conseqüente das
regras.
15
Resultados - Regras de Associação
X→Y
Regras Triviais
FreqCursinho <- MtPre1
(18.7%, 96.5%)
NaoFreqCursinho <- MtPre7
(56.6%, 97.9%)
TrabalhoIntegral <- LcInt-Trabalho
(13.8%, 82.9%)
SustentoProprio <- TrabalhoIntegral
LcInt-s/Acesso <- UtInt-Nunca
(33.2%, 96.2%)
UtInt-Nunca <- UtMic-NaoNaoTenho
(10.8%, 85.1%)
LcInt-s/Acesso <- UtMic-NaoNaoTenho
UtMic-SimTenho <- LcInt-Casa
(41.4%, 88.3%)
(10.8%, 85.2%)
(29.8%, 94.0%)
UtInt-DominioParcial <- LcInt-OutrosLocais
QtAnt1 <- cc2Gr2
(20.6%, 88.3%)
(44.5%, 89.0%)
Voltar
Resultados - Regras de Associação
X→Y
Regras Redundantes
NaoFreqCursinho
<-
QtPer1
NaoFreqCursinho
<-
NaoClassificado
(45.3%, 81.0%)
QtPer1 (25.9%, 80.4%)
Voltar
16
Resultados - Regras de Associação
X→Y
– Soluções:
• selecionar atributos mais importantes;
• agrupar valores dos atributos;
• medida adicional que calcula a diferença entre os graus de confiança das
regras;
• para eliminar regras triviais, descartar todas as regras com aquelas
combinações de itens como conseqüente e antecedente;
• estabelecer limites de confiança mais baixos (50%).
Resultados - Regras de Associação
X→Y
– Resultados - Arquivos do tipo RA-Todos
• Arquivo RA-Tod34:
– Configuração:
» quase todos os atributos, menos notas e município;
» 670 itens
» 8.644 transações
» suporte 10% e confiança 80%
– 44.640 regras
– Aplicando a medida de diferença dos graus de confiança com limite de 20%,
31.026 regras foram eliminadas, restando 13.614 regras
• Como é praticamente impossível selecionar padrões importantes entre uma
grande quantidade de regras, optou-se por gerar vários arquivos, com
seleções diferentes de atributos.
17
Resultados - Regras de Associação
X→Y
Regras importantes, ordenadas pelo grau de suporte:
NaoFreqCursinho
QtPer1
(45.3%, 81.0%)
Não Classificado <- Noturno
QtPer1 <- Noturno
(28.1%, 64.1%)
(28.1%, 63.7%)
Publica <- Noturno
(28.1%, 60.4%)
Classificado <- Diurno Particular FreqCursinho
(21.7%, 64.8%)
Particular <- Diurno Classificado FreqCursinho
(20.7%, 67.8%)
Não Classificado <- QtPer1 Noturno
Particular <- QtPer3
(17.9%, 66.0%)
(15.6%, 67.5%)
Classificado <- Diurno QtPer3
(13.5%, 64.4%)
NaoFreqCursinho <- Não Classificado Publica Noturno
Classificado <- Particular QtPer3
(10.8%, 73.1%)
(10.6%, 65.3%)
Resultados - Regras de Associação
X→Y
A partir de inúmeros testes, contatou-se que algumas características tendem a
aparecer juntas. Dois conjuntos de itens foram destacados:
•
•
•
•
•
Classificado
Particular
QtPer3
Diurno
FreqCursinho
•
•
•
•
•
NaoClassificado
Publica
QtPer1
Noturno
NaoFreqCursinho
18
Resultados - Regras de Associação
X→Y
– Resultados - Arquivos do tipo RA-Classificados
Matriculado
Matriculado
Matriculado
Matriculado
<- (100.0%, 81.9%)
<- Media2a<4 (67.4%, 85.3%)
<- QtPer1 (38.7%, 93.9%)
<- QtPer2 (36.4%, 80.5%)
Media2a<4
Media4a<6
Media4a<6
Matriculado (81.9%, 70.2%)
Matriculado (81.9%, 26.9%)
NaoMatriculado (18.1%, 40.4%)
Media4a<6
Media4a<6
QtPer1 (38.7%, 16.4%)
QtPer3 (36.3%, 43.5%)
QtPer1
QtPer3
QtPer1
QtPer3
QtPer1
QtPer1
QtPer1
Não Matriculado (18.1%,
Não Matriculado (18.1%,
Matriculado Media2a<4
Matriculado Media2a<4
13.0%)
35.1%)
(57.5%, 50.3%)
(57.5%, 12.6%)
Noturno (20%, 60.3%)
Publica (40.9%, 48.6%)
Particular (56.6%, 30.6%)
Resultados - Árvores de Decisão
– Problemas:
• valores dos atributos estão bem distribuídos entre candidatos classificados
e não classificados e matriculados e não matriculados;
• árvores muito grandes e largas demais, com informações muito
espalhadas;
• pequeno número de casos encobertos por cada nodo folha;
• mesmo após a poda as árvores continuam grandes.
19
Resultados - Árvores de Decisão
– Soluções:
• selecionar atributos mais importantes;
• agrupar valores dos atributos.
Resultados - Árvores de Decisão
– Resultados - Arquivos do tipo RA-Todos
Arquivo num reg num atrib tam arv. orig. taxa erro tam arv podada taxa erro
Tod89
8010
13
4085
16.4%
949
28.5%
Tod90
8010
6
1200
30.9%
354
34.2%
Tod97
8010
4
58
39.6%
12
39.8%
Tod98
8010
5
634
35.3%
130
38.1%
Tod99
8010
6
314
37.3%
27
39.4%
Tod100
8010
5
154
38.5%
30
39.7%
Tod101
8010
4
45
39.8%
13
40.8%
Tod102
8010
5
134
39.1%
13
40.2%
Seleção de atributos
20
Resultados - Árvores de Decisão
Seleção de atributos dos arquivos:
Tod
Tod
Tod
Tod
Tod
Tod
Tod
Tod
89
90
97
98
99
100
101
102
1- Turno 2grau
X
X
X
X
X
X
X
X
2- Tipo 2grau
X
X
3- Forma 2grau
X
X
X
X
4- Cursinho
X
Atributos
5- Qtde vest. periodo
6- Nível instrucao mãe
X
7- Nível instrucao pai
X
8- Idade
X
9- Atividade remun.
X
10- Particip. econ. famil.
X
11- Motivo pre vest.
X
12- Utiliza internet
X
13- Local uso internet
X
14- Utiliza Micro
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
X
Voltar
Resultados - Árvores de Decisão
– Árvore de decisão podada do arquivo Tod97
Simplified Decision Tree:
Turno 2Grau = Noturno: Não Classificado (2230.3/875.5)
Turno 2Grau = Diurno:
|
Qtde Vest Periodo > 1 : Classificado (3553.7/1305.1)
|
Qtde Vest Periodo <= 1 :
|
|
Forma 2Grau = Publica: Não Classificado (1098.0/542.0)
|
|
Forma 2Grau = Particular: Classificado (1030.9/489.6)
|
|
Forma 2Grau = Outros: Classificado (53.0/19.9)
Turno 2Grau = Outro:
|
Forma 2Grau = Publica: Não Classificado (15.0/6.8)
|
Forma 2Grau = Particular: Classificado (18.0/9.0)
|
Forma 2Grau = Outros: Classificado (11.0/5.6)
21
Resultados - Árvores de Decisão
Resultados - Arquivos do tipo AD-Todos
– Duas classes:
• 53.3% classificaram-se
• 46.76% não classificaram-se
– Taxa de erro:
• 39.8% é alta
Resultados - Árvores de Decisão
Resultados - Arquivos do tipo AD-Classificados
– o fato da taxa de erro das árvores podadas ser baixo não indica que a
árvore aprendeu o problema;
– classe Não Matriculado ocorre poucas vezes (18.1%) entre os candidatos
classificados;
– taxa de erro das árvores podadas, em torno de 16%.
Resultados - Arquivos do tipo AD-TodosMatricula
– tendências iguais às geradas pelos arquivos do tipo AD-Todos.
Tabela de resultados
22
Resultados - Árvores de Decisão
– Resultados - Arquivos do tipo AD-Classificado e
AD-TodosMatricula
Arquivo
nº reg.
nº atrib. tam. arv. orig. taxa erro tam. árv. podada taxa erro
Class103
4270
5
1012
10.5%
74
16.2%
Class104
4270
4
972
10.7%
150
15.6%
Class105
4270
5
950
10.3%
99
16.1%
Class106
4270
6
1154
9.9%
104
16.1%
Class107
4270
3
573
13.7%
49
16.9%
Class111
4270
9
1146
7.3%
100
16.1%
TdMat115
8010
10
3535
20.9%
822
32.1%
TdMat116
TdMat119
TdMat120
TdMat122
8010
8010
8010
8010
4
3
5
7
51
58
224
516
42.2%
42.5
41.2
38.9
18
1
31
56
42.4%
43.60%
42.20%
41.10%
Voltar
Comparativo entre as Duas Técnicas
Regras de Associação
• Algoritmo Apriori
X→Y
Árvores de Decisão
• Algoritmo C4.5
• Padrões descritivos – aprendizado não supervisionado • Padrões preditivos – aprendizado supervisionado
• Encontrar padrões interessantes relacionados ao fato • Classificar as características dos candidatos
do candidato ter se classificado ou não e se
matriculado ou não e outros relacionamentos entre os
outros itens
• Não aceita valores numéricos
• Aceita valores numéricos
• Os diferentes itens contidos nas transação é que são
considerados, independente de atributos
• Os atributos, com seus valores, são considerados para
construção das árvores
• Dificuldade em encontrar regras interessantes com os • Todos os caminhos das árvores levam aos itens
itens Classificado e Não Classificado e Matriculado e
Classificado ou Não Classificado e Matriculado e
Não Matriculado no consequente
Não Matriculado
• Maior dificuldade para interpretar as regras e
configurar os parâmetros de entrada
• Fáceis de interpretar
23
Conclusão
– A aplicação do Data Mining para o problema proposto foi bastante
complexa, além de consumir muito tempo;
– Considerando o processo de KDD, o retorno à etapas anteriores é
constante;
– Os algoritmos de mineração geraram uma grande quantidade de
padrões, devido à grande quantidade de atributos e muitos valores
possíveis diferentes;
– Além de consultas SQL, outros algoritmos e/ou métodos de análise
estatística poderiam ser utilizados para auxiliar na seleção e
agrupamento de atributos;
Conclusão
– Apesar de não conseguir resultados muito satisfatórios com as
árvores de decisão geradas, esta técnica foi mais adequada para a
aplicação proposta, e mais fácil de selecionar os padrões interessantes;
– Regras de associação são mais adequadas para problemas onde todos
os itens tem a mesma importância;
– Características dos candidatos estão muito espalhadas.
24
Conclusão
Tendências
– candidatos que cursaram 2º grau noturno, tendem a não se classificarem;
– 2º grau diurno, que estão prestando vestibular somente na Unisinos, não
se classificarem e que estão prestando outros, se classificarem;
– quanto maior o nível de instrução da mãe, maior a probabilidade de
classificação;
– o padrão de vida geral do candidato contribui para sua classificação;
– candidatos classificados, com boa média, que cursaram 2º grau em
escola particular diurno, e que estão prestando vestibulares em outras
Universidades também, tendem a não se matricularem na Unisinos.
Conclusão
Considerando essas tendências:
– definir um segmento de mercado, considerando o perfil do candidato, e
trabalhar o planejamento de marketing sobre este segmento;
– planejar estratégias para evitar a fuga dos bons alunos para outras
Universidades.
25
Conclusão
Perspectivas
– repetir o processo com os dados do vestibular da Unisinos de outros
semestres;
– utilizar outros algoritmos e técnicas para selecionar e agrupar padrões;
– desenvolver algoritmos para eliminar regras triviais e redundantes.
26