COPPE/UFRJ
DESCOBERTA DE CONHECIMENTO EM BANCO DE DADOS DE SAÚDE
ATRAVÉS DA INTEGRAÇÃO DE MINERAÇÃO DE DADOS GEOGRÁFICOS E
REDES COMPLEXAS
Fátima Ferrão dos Santos
Tese de Doutorado apresentada ao Programa de Pósgraduação
em
Engenharia
Civil,
COPPE,
da
Universidade Federal do Rio de Janeiro, como parte
dos requisitos necessários à obtenção do título de
Doutor em Engenharia Civil.
Orientador: Nelson Francisco Favilla Ebecken
Rio de Janeiro
Dezembro de 2008
DESCOBERTA DE CONHECIMENTO EM BANCO DE DADOS DE SAÚDE
ATRAVÉS DA INTEGRAÇÃO DE MINERAÇÃO DE DADOS GEOGRÁFICOS E
REDES COMPLEXAS
Fátima Ferrão dos Santos
TESE SUBMETIDA AO CORPO DOCENTE DO INSTITUTO ALBERTO LUIZ
COIMBRA DE PÓS-GRADUAÇÃO E PESQUISA DE ENGENHARIA (COPPE) DA
UNIVERSIDADE FEDERAL DO RIO DE JANEIRO COMO PARTE DOS
REQUISITOS NECESSÁRIOS PARA A OBTENÇÃO DO GRAU DE DOUTOR EM
CIÊNCIAS EM ENGENHARIA CIVIL.
Aprovada por:
______________________________________________________
Prof. Nelson Francisco Favilla Ebecken, D.Sc.
______________________________________________________
Prof. Beatriz de Souza Leite Pires de Lima, D.Sc.
______________________________________________________
Prof. Alexandre Gonçalves Evsukoff, Dr.
______________________________________________________
Prof. Hélio José Côrrea Barbosa, PhD.
______________________________________________________
Prof. Gilberto Carvalho Pereira, D.Sc.
RIO DE JANEIRO, RJ –BRASIL
DEZEMBRO DE 2008
Santos, Fátima Ferrão
Descoberta de Conhecimento em Banco de Dados de Saúde
através da Integração de Mineração de Dados Geográficos e
Redes Complexas/Fátima Ferrão dos Santos. – Rio de Janeiro:
UFRJ/COPPE, 2008.
XXV, 201 p.: il.; 29,7 cm.
Orientador: Nelson Francisco Favilla Ebecken
Tese (doutorado) – UFRJ/ COPPE/ Programa de
Engenharia Civil, 2008.
Referências Bibliográficas: p. 153-163.
1. Descoberta de Conhecimento. 2. Mineração de dados
geográficos. 3. Redes Complexas. I. Ebecken, Nelson Francisco
Favilla. II. Universidade Federal do Rio de Janeiro, COPPE,
Programa de Engenharia Civil. III. Titulo.
iii
Ao Marcos, Camila e Cintia.
iv
AGRADECIMENTOS A
Camila e Cintia, minhas filhas, pela compreensão e pelas inúmeras horas em que estive
ausente;
Minha família, pelo apoio e paciência;
Aristóteles (i.m.) e Léa, meus pais, pelo incentivo;
Márcia Ferlim, minha querida amiga, pelo carinho e incentivo constante.
Luiz Pereira Calôba, pela dedicação em disciplinas de Redes Neurais Artificiais, que
muito me ajudou e motivou, meu agradecimento especial;
Christovam Barcellos, pesquisador da Fiocruz, e Kátia Valente, da Secretaria Municipal
de Saúde DST-AIDS, por disponibilizar o banco de dados;
Thelmo
Fernandes
e
Orlando
Caldas,
pelo
suporte
do
Laboratório
da
COPPE/Engenharia Civil.
Egna, secretária e toda a equipe da secretaria da COPPE/Engenharia Civil, pela ajuda,
sempre que solicitada.
CAPES, pelo suporte financeiro que viabilizou a realização desta tese.
Alexandre Evsukoff e Nelson Francisco Favilla Ebecken, professores da COPPE/UFRJ,
que apresentaram com rigor e entusiasmo as disciplinas necessárias ao desenvolvimento
desta tese;
Este último, Nelson Francisco Favilla Ebecken, meu orientador, um agradecimento
especial pela dedicação e paciência na orientação do trabalho; sempre atencioso, muito
me motivou para que fosse concluído.
v
Resumo da Tese apresentada à COPPE/UFRJ como parte dos requisitos necessários
para a obtenção do grau de Doutor em Ciências (D.Sc.)
DESCOBERTA DE CONHECIMENTO EM BANCO DE DADOS DE SAÚDE
ATRAVÉS DA INTEGRAÇÃO DE MINERAÇÃO DE DADOS GEOGRÁFICOS E
REDES COMPLEXAS
Fátima Ferrão dos Santos
Dezembro/2008
Orientador: Nelson Francisco Favilla Ebecken
Programa: Engenharia Civil
Esta tese se concentra no desenvolvimento de descoberta de conhecimento em
um banco de dados de saúde, exclusivamente da epidemia pelo vírus HIV, por meio da
integração de mineração de dados geográficos e redes complexas. O presente trabalho é
composto de três partes distintas. A primeira parte apresenta uma proposta de medida de
dependência espacial, denominada índice de influência espacial. Dependência espacial é
o impacto que a variação na localização espacial causa na variação dos atributos, ou
seja, é a medida de como os atributos são dependentes do espaço geográfico. A segunda
parte apresenta a aplicação do índice nas tarefas de mineração de dados
geográficos. Com base nos resultados obtidos com as tarefas de mineração de dados, as
fases de evolução da epidemia são identificadas. Essa parte apresenta também a
modelagem espaço-temporal e a predição da evolução da epidemia com óbito.
Finalmente, a terceira parte integra os conhecimentos obtidos usando a abordagem de
redes complexas.
vi
Abstract of Thesis presented to COPPE/UFRJ as a partial fulfillment of the
requirements for the degree of Doctor of Science (D.Sc.)
KNOWLEDGE DISCOVERY ON HEALTH DATABASES BASED ON THE
INTEGRATION OF GEOGRAPHIC DATA MINING AND COMPLEX NETWORKS
Fátima Ferrão dos Santos
December/2008
Advisor: Nelson Francisco Favilla Ebecken
Department: Civil Engineering
This thesis focuses the development of knowledge discovery in a health database,
particularly for HIV virus epidemics, through the integration of geographic data mining
and complex networks. The present work comprises three different sections. First, a
proposal for spatial dependence measure called Spatial Influence Index is presented.
Spatial dependence is a measure of the impact caused by a modification in the spatial
localization on attribute modification, thus, it measures how attributes are dependent of
the geographical space. The second section presents the application of the Index to
geographical data mining tasks. The stages of the epidemics evolution are identified
based on the results of those data mining tasks. This section also presents a spatiotemporal modeling and a forecast of the evolution of the epidemics with death. Finally
the obtained knowledge is integrated using the complex network approach.
vii
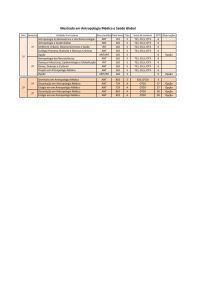
SUMÁRIO
CAPÍTULO 1 .................................................................................................................. 1
INTRODUÇÃO .............................................................................................................. 1
1.1
Introdução .......................................................................................................... 1
1.2
Motivação .......................................................................................................... 2
1.3
Objetivo ............................................................................................................. 3
1.4
Contribuição....................................................................................................... 3
1.5
Contexto ............................................................................................................. 4
1.6
Organização do Trabalho ................................................................................... 5
CAPÍTULO 2 .................................................................................................................. 8
REVISÃO BIBLIOGRÁFICA ...................................................................................... 8
2.1
Introdução .......................................................................................................... 8
2.2
Descoberta de Conhecimento em Bancos de Dados (KDD) ............................. 8
2.2.1
Mineração de Dados ........................................................................................... 9
2.2.2
Perspectivas do Processo de Descoberta do Conhecimento ............................. 10
2.2.3
KDD: Revisão Bibliográfica ............................................................................ 11
2.3
Sistema de Informações Geográficas (SIG) ..................................................... 13
2.3.1
Espaço Absoluto: Geo-campo e Geo-objeto .................................................... 13
2.3.2
SIG: Revisão Bibliográfica .............................................................................. 15
2.4
Visualizacao Geográfica .................................................................................. 15
2.4.1
Visualização Geográfica: Revisão Bibliográfica ............................................. 16
2.5
Redes Complexas ............................................................................................. 17
2.5.1
Redes Complexas: Revisão Bibliográfica ........................................................ 18
2.6
A Epidemia pelo Vírus HIV ............................................................................ 20
2.6.1
A Epidemia pelo Vírus HIV: Revisão Bibliográfica ........................................ 21
2.7
Resumo ............................................................................................................ 21
CAPÍTULO 3 ................................................................................................................ 22
PROPOSTA DE METODOLOGIA PARA DEFINIÇÃO DE PRIORIDADES .... 22
3.1
Introdução ........................................................................................................ 22
viii
3.2
Objetivo ........................................................................................................... 22
3.3
Conceitos ......................................................................................................... 22
3.3.1
Sistema ............................................................................................................. 22
3.3.2
Sistemas Complexos......................................................................................... 23
3.3.3
Redes Complexas ............................................................................................. 24
3.4
Sistemas, Software e Dados ............................................................................. 24
3.5
Metodologia ..................................................................................................... 26
3.5.1
Nível Conceitual ............................................................................................... 27
3.5.1.1
Definição de Prioridades e Objetivos ................................................ 28
3.5.2
Nível Estrutural ................................................................................................ 32
3.5.3
Nível de Implantação........................................................................................ 34
3.5.4
Nível Ontológico .............................................................................................. 34
3.6
Método para Definição de Variáveis Relevantes ............................................. 34
3.7
Resumo ............................................................................................................ 36
CAPÍTULO 4 ................................................................................................................ 37
PROPOSTA DE ÍNDICE DE INFLUÊNCIA ESPACIAL ...................................... 37
4.1
Introdução ........................................................................................................ 37
4.2
Objetivo ........................................................................................................... 37
4.3
Sistemas, Software e Dados ............................................................................. 38
4.4
Conceitos ......................................................................................................... 38
4.4.1
Matriz de Proximidade ..................................................................................... 38
4.4.2
Índice Global de Autocorrelação Espacial ....................................................... 39
4.5
Proposta de Índice de Influência Espacial ....................................................... 41
4.5.1
Cálculo do Índice de Influência Espacial ......................................................... 42
4.5.2
Índice de Influência Espacial Global................................................................ 45
4.5.3
Análise de Tendência Espacial ......................................................................... 45
4.5.4
Implantação do Índice de Influência Espacial .................................................. 46
4.5.5
Exemplo de Aplicação do IF ............................................................................ 47
ix
4.6
Resumo ............................................................................................................ 50
CAPÍTULO 5 ................................................................................................................ 51
APLICAÇÃO DO ÍNDICE EM TAREFAS DE MINERAÇÃO DE DADOS ........ 51
5.1
Introdução ........................................................................................................ 51
5.2
Objetivo ........................................................................................................... 52
5.3
Sistemas, Software e Dados ............................................................................. 52
5.4
Conceitos ......................................................................................................... 53
5.4.1
Classificação de Redes Neurais Artificiais ...................................................... 53
5.4.2
Mapas Auto-Organizáveis ................................................................................ 53
5.4.3
Avaliação de qualidade do Mapa Auto-Organizável ....................................... 55
5.4.4
Visualização do Mapa Auto-Organizável ........................................................ 55
5.4.5
Definição do número de clusters ...................................................................... 57
5.5
Aplicação do IF em Tarefas de Mineração de Dados ...................................... 59
5.6
Resultados dos Agrupamentos de Dados ......................................................... 59
5.6.1
Taxa de Crescimento da Contaminação ........................................................... 59
5.6.2
Indices Econômico-sociais, Taxa de Contaminação e IF ................................. 61
5.6.3
Categoria de Exposição .................................................................................... 63
5.6.4
Razão de Sexos................................................................................................. 69
5.6.5
Nível de escolaridade ....................................................................................... 71
5.6.6
Resultados Obtidos com o Agrupamento de Dados ......................................... 73
5.7
Resumo ............................................................................................................ 73
CAPÍTULO 6 ................................................................................................................ 75
ANÁLISE DA EPIDEMIA PELO VIRUS HIV ........................................................ 75
6.1
Introdução ........................................................................................................ 75
6.2
Objetivo ........................................................................................................... 75
6.3
Sistemas, Software e Dados ............................................................................. 75
6.4
Conceitos ......................................................................................................... 76
6.4.1
Espaço .............................................................................................................. 76
x
6.4.2
Séries Temporais .............................................................................................. 77
6.5
Primeiro Objetivo: Identificação das Fases da Epidemia ................................ 77
6.5.1
Metodologia...................................................................................................... 77
6.5.2
Proposta de Utilização do IF para Segmentação das Fases da Epidemia ......... 79
6.5.3
Identificação da Direção de Proliferação da Epidemia .................................... 80
6.5.4
Resultados obtidos............................................................................................ 81
6.6
Segundo Objetivo: Predição da Evolução da Doença com Óbito ................... 82
6.6.1
Análise de Séries Temporais ............................................................................ 82
6.6.2
Análise no Domínio do Tempo ........................................................................ 83
6.6.2.1
Autocorrelação de uma Série Temporal ............................................ 83
6.6.2.2
Correlação Cruzada entre Séries Temporais ..................................... 84
6.6.3
Análise no Domínio da Frequência .................................................................. 84
6.6.4
Decomposição Clássica de Séries Temporais .................................................. 85
6.6.5
Resultados obtidos............................................................................................ 85
6.6.5.1
Predição da Série de Óbitos: Primeiro Modelo ................................. 85
6.6.5.2
Predição da Série de Óbitos: Segundo Modelo ................................. 90
6.7
Terceiro Objetivo: Modelagem Espaço-Temporal .......................................... 96
6.8
Resumo ............................................................................................................ 98
CAPÍTULO 7 ................................................................................................................ 99
ANALISE DA EPIDEMIA COM A ABORDAGEM DE REDES COMPLEXAS 99
7.1
Introdução ........................................................................................................ 99
7.2
Objetivo ......................................................................................................... 100
7.3
Sistemas, Software e Dados ........................................................................... 100
7.4
Conceitos ....................................................................................................... 100
7.4.1
Cálculo, Medidas de Estrutura da Rede e Visualização ................................. 100
7.4.2
Redução da Rede ............................................................................................ 101
7.4.2.1
7.4.3
Visão Global .................................................................................... 102
Vetores e Partições ......................................................................................... 103
xi
7.4.4
Medidas de Centralidade ................................................................................ 105
7.4.5
Coesão da Rede, Densidade e Conectividade ................................................ 106
7.4.6
A força das Conexões Fracas ......................................................................... 108
7.4.7
K-Cores .......................................................................................................... 108
7.4.8
Centralidade de uma rede ............................................................................... 108
7.4.8.1
7.4.9
Rede em Estrela ............................................................................... 108
Distância e Caminho ...................................................................................... 110
7.4.9.1
Proximidade da Centralidade .......................................................... 113
7.4.10
Intermediação ................................................................................................. 114
7.4.11
Pontes ............................................................................................................. 115
7.4.12
Rede-ego e Conceito de Restrição.................................................................. 117
7.4.12.1
Rede-ego.......................................................................................... 119
7.5
Objetivo ......................................................................................................... 122
7.5.1
Primeiro Objetivo: Difusão da Epidemia ....................................................... 122
7.5.1.1
Contágio .......................................................................................... 122
7.5.1.2
Exposição e Limiar.......................................................................... 123
7.5.1.3
Relação entre a Densidade e o Tempo de Difusão .......................... 133
7.5.2
Segundo Objetivo: Definição da Massa Crítica ............................................. 134
7.6
Resultados Obtidos ........................................................................................ 136
7.7
Resumo .......................................................................................................... 137
CAPÍTULO 8 .............................................................................................................. 139
PROPOSTA DE MEDIDA DE INTERAÇÃO ESPACIAL ................................... 139
8.1
Introdução ...................................................................................................... 139
8.2
Objetivo ......................................................................................................... 139
8.3
Sistemas, Software e Dados ........................................................................... 140
8.4
Medida de Interação Espacial ........................................................................ 140
8.4.1
Cálculo da Interação Espacial ........................................................................ 141
8.5
Resultados obtidos ......................................................................................... 141
xii
8.6
Resumo .......................................................................................................... 146
CAPÍTULO 9 .............................................................................................................. 148
CONSIDERAÇÕES FINAIS ..................................................................................... 148
9.1
Conclusões ..................................................................................................... 148
9.2
Trabalhos Futuros .......................................................................................... 152
REFERÊNCIAS BIBLIOGRÁFICAS ..................................................................... 153
ANEXO A - Agrupamento de Bairros por Área e Índices Econômico-sociais ..... 164
ANEXO B - Agrupamento de Bairros por Índices Econômico-Sociais ................. 165
ANEXO C - Agrupamento de Bairros por Índices Econômico-Sociais (Parte 2) . 166
ANEXO D - Agrupamento de Bairros por Indices Econômicos-sociais (Parte 3) 167
ANEXO E - Tabelas de Medidas de Centralidade por Bairro ............................... 168
ANEXO F - Algoritmo Cálculo de Tendência Espacial .......................................... 170
ANEXO G - Indicadores Econômico-sociais ........................................................... 173
ANEXO H - Mapa da Estrutura da Rede Complexa de Bairros. .......................... 174
ANEXO I - Mapa de Valores de Grau (número de conexões) da Rede ................. 176
ANEXO J - Mapa de Valores de Centralidade de Bairros ..................................... 177
ANEXO K - Mapa de Valores de Restrição Agregada da Rede de Bairros. ........ 178
ANEXO L - Mapa de Valores de Densidade Egocêntrica da Rede de Bairros ..... 179
ANEXO M - Mapa de Valores de Limiar da Rede de Bairros ............................... 180
ANEXO N - Dicionário de Dados. ............................................................................ .181
xiii
LISTA DE FIGURAS
Figura 2.1a Geo-campo (INPE)
14
Figura 2.1b Geo-objeto: análise da saúde segundo a renda familiar,
14
município do Rio de Janeiro.
Figura 3.1 Infra-estrutura de dados
32
Figura 4.1. Medida de proximidade baseada no compartilhamento do lado do
38
polígono
Figura 4.2 Eixo de coordenadas com origem no centróide de O1 usado no
42
cálculo da direção de O2 em relação a O1
Figura 4.3 Índice de influência espacial
44
Figura 4.4 Mapa temático de taxa de notificações de AIDS por bairro, 1997,
44
município do Rio de Janeiro
Figura 4.5 Linhas imaginárias de direções-padrão a partir do polígono central
45
Figura 4.6 Valores observados e preditos pela RNA com IF na camada de
49
entrada
Figura 4.7 Valores observados e preditos pela RNA sem o IF na camada de
49
entrada
Figura 5.1 Modelo de neurônio j, com entrada xk e saída f (J)
51
Figura 5.2a Imagem fatiada usando estimador de densidade Kernel para o
56
atributo total de ocorrências de aids por setor censitário, visualização software
Spring, 2005, município do Rio de Janeiro.
Figura 5.2b. Estrutura do mapa auto-organizável de notificações de aids por
56
setor censitário, após cem épocas de treinamento da rede SOM bidimensional
20 x 40, desenvolvido no Matlab, 2005, município do Rio de Janeiro.
Figura 5.3. Cálculo dos valores dx, dy e dz da U-matriz, visualização software
xiv
57
Statistica.
Figura 5.4a Índice Calinski-Harabasz calculado para os dados originais.
58
Figura 5.4b Índice Calinski-Harabasz calculado para os vetores resultantes da
58
rede SOM.
Figura 5.5 Resultado do agrupamento de dados de bairros por taxa de
59
crescimento da epidemia, visualização software Statistica, 1982 a 2005,
município do Rio de Janeiro.
Figura 5.6 Taxa de contaminação por bairro, 1982 a 1992, município do Rio
60
de Janeiro.
Figura 5.7 Resultado do agrupamento de bairros com atributo IF, visualização
60
software Spring, 1982 a 2005, município do Rio de Janeiro.
Figura 5.8 Valor do IF por bairro, 1982 a 1999, município do Rio de Janeiro.
61
Figura 5.9 Agrupamentos de bairros (principais agrupamentos) com vetor de
62
características composto pelos atributos IF, taxa de contaminação e índices
econômico-sociais.
Figura 5.10 Agrupamento de bairros com vetor de características composto
63
pelos atributos IF, taxa de contaminação e índices econômico-sociais,
visualização software Spring.
Figura 5.11 Total de casos de aids por categoria de exposição, 1982 a 2005,
64
município do Rio de Janeiro.
Figura 5.12a Notificações de aids em homossexuais, 1982 a 1985, município
65
do Rio de Janeiro.
Figura 5.12b Notificações de aids em heterossexuais, 1982 a 1985, município
66
do Rio de Janeiro.
Figura 5.12c Notificações de aids em homossexuais, 1982 a 1988, município
do Rio de Janeiro.
xv
66
Figura 5.12d Notificações de aids em heterossexuais, 1982 a 1988, município
67
do Rio de Janeiro.
Figura 5.12e Notificações de aids em homossexuais, 1982 a 1999, município
67
do Rio de Janeiro.
Figura 5.12f Notificações de aids em heterossexuais, 1982 a 1999, município
68
do Rio de Janeiro.
Figura 5.13 Percentual de homens e mulheres, 1982 a 2005, município do Rio
69
de Janeiro.
Figura 5.14 Razão de sexos, 1982 a 2005, município do Rio de Janeiro.
69
Figura 5.15a Percentual de homens contaminados vivos por bairro, 2005,
70
município do Rio de Janeiro.
Figura 5.15b Percentual de mulheres contaminadas vivas do bairro, 2005,
71
município do Rio de Janeiro.
Figura 5.16 Anos de estudo de pacientes com notificações de aids, 1982 a
72
1999, município do Rio de Janeiro.
Figura 5.17 Percentual de chefes de família do bairro com renda de até dois
72
salários mínimos, 2005, município do Rio de Janeiro.
Figura 6.1 Valores percentuais em relação ao total de casos e em relação à
76
população do bairro, 1982 a 2005, [ principais bairros ], município do Rio de
Janeiro.
Figura 6.2 Bairros com dez maiores variações do IF, 1982 a 1999, município
77
do Rio de Janeiro.
Figura 6.3 Dendrograma e gráfico de bairros, taxa da população contaminada
78
pelo vírus HIV e IF, por bairro, 1983, município do Rio de Janeiro.
Figura 6.4 Dendrograma e gráfico de bairros, taxa da população contaminada
xvi
79
pelo vírus HIV e IF, 1984, município do Rio de Janeiro.
Figura 6.5a Taxa de contaminação da aids por bairro, 1988, município do Rio
81
de Janeiro e retas na direção 90º e 225º a partir do centróide de Copacabana.
Figura 6.5b Taxa de contaminação da aids por bairro, 1999, município do Rio
81
de Janeiro e retas na direção 90º e 225º a partir do centróide de Copacabana..
Figura 6.6 Prevalência de IFd por fase, município do Rio de Janeiro.
82
Figura 6.7a Série de óbitos normalizada, 1985 a 2005, município do Rio de
86
Janeiro.
Figura 6.7b Série de óbitos normalizada, sem tendência e sem sazonalidade,
86
1985 a 2005, município do Rio de Janeiro.
Figura 6.8 Espectograma da série de óbitos, obtido por intermédio da FFT.
87
Figura 6.9 Espectograma da série de óbitos após a retirada das freqüências
87
dominantes.
Figura 6.10 Série residual sem ciclos senoidais.
88
Figura 6.11 Função de autocorrelação da série residual.
88
Figura 6.12 Função de autocorrelação parcial da série residual.
89
Figura 6.13 Período de teste, série real e previsão.
90
Figura 6.14 Série de óbitos e série de pacientes com escolaridade de um a três
91
anos, após a retirada de tendência e da sazonalidade, 1985 a 2005, município
do Rio de Janeiro.
Figura 6.15 Séries de óbitos e CD+4 inferior a 350 células/mm3, após a
91
retirada de tendência e sazonalizadade, 1985 a 2005, município do Rio de
Janeiro.
Figura 6.16a Correlação cruzada entre a série de óbitos e série de pacientes
com escolaridade de um a três anos, 1985 a 2005, município do Rio de Janeiro
xvii
92
Figura 6.16b Correlação cruzada entre a série de óbitos e série de pacientes na
92
faixa etária de 35 a 39 anos, após a retirada de tendência e da sazonalidade,
1985 a 2005, município do Rio de Janeiro
Figura 6.16c Correlação cruzada entre a série de óbitos e série de pacientes na
93
faixa etária de 30 a 34 anos, após a retirada de tendência e da sazonalidade,
1985 a 2005.
Figura 6.16d Correlação cruzada entre a série de óbitos e série de notificações
93
de aids, após a retirada de tendência e da sazonalidade, 1985 a 2005.
Figura 6.17 Valores observados e previstos, visualização Statistica.
Figura 7.1a Rede reduzida de bairros e unidades, visão global, 1982 a 1999,
96
102
município do Rio de Janeiro.
Figura 7.1b Rede reduzida de bairros e unidades, visão contextual, 1982 a
103
1999, município do Rio de Janeiro.
Figura 7.2a Análise estatística Crame’s V e Rajski entre taxas de
104
contaminação de homossexuais por bairro, software Pajek, 1992 e 1999,
município do Rio de Janeiro.
Figura 7.2b Rede formada por unidades hospitalares utilizadas e bairros de
106
residência dos pacientes contaminados pelo vírus HIV, 1985, município do
Rio de Janeiro, visualização com NetDraw.
Figura 7.3 Distribuição de freqüência de bairros por número de conexões,
107
município do Rio de Janeiro.
Figura 7.4 Valor de k-core por bairro, município do Rio de Janeiro.
109
Figura 7.5 Rede estrela de pacientes que residem no município do Rio de
110
Janeiro e que realizaram diagnóstico de infecção pelo vírus HIV em outro
município, 1982 a 2005.
xviii
Figura 7.6 Cronologia de notificações de aids, 1982 a 1985, município do Rio
112
de Janeiro.
Figura 7.7 Centralidade do bairro, 2005, município do Rio de Janeiro.
114
Figura 7.8 Bi-componentes e vértices-corte, 2005, município do Rio de
116
Janeiro.
Figura 7.9 Tríade incompleta.
117
Figura 7.10 Exemplo de rede.
118
Figura 7.11 Valores de restrição agregada de bairros, município do Rio de
121
Janeiro.
Figura 7.12 Valores de densidade egocêntrica de bairros, município do Rio de
122
Janeiro.
Figura 7.13 Curva de contágio (bairros com notificações), 1982 a 1996,
123
município do Rio de Janeiro.
Figura 7.14 Rede de bairros por ordem de contaminação e valor de exposição,
125
1984, município do Rio de Janeiro.
Figura 7.15 Limiar médio e freqüência acumulada de bairros com o primeira
127
notificação de aids no ano, 1982 a 1993, município do Rio de Janeiro.
Figura 7.16 Rede de bairros com ocorrência da epidemia, 1982 a 1985,
130
município do Rio de Janeiro.
Figura 7.17 Rede de bairros com ocorrência da epidemia, 1982 a 1987,
130
município do Rio de Janeiro.
Figura 7.18 Rede de bairros, 1982 a 1987, município do Rio de Janeiro.
xix
131
Figura 7.19 Medida de intermediação da rede de bairros contaminados
131
representada pelo tamanho do vértice, 1982 a 1985, município do Rio de
Janeiro.
Figura 7.20 Medida de intermediação da rede de bairros contaminados
132
representada pelo tamanho do vértice, 1982 a 1987, município do Rio de
Janeiro.
Figura 7.21 Medida de intermediação da rede de bairros contaminados
132
(tamanho do vértice) e a taxa de contaminação do período seguinte 1992 (cor),
1982 a 1987, município do Rio de Janeiro.
Figura 7.22 Valor de limiar por vértice da rede de bairros, município do Rio de
133
Janeiro.
Figura 8.1 Gráfico Bipartite, de interação entre bairro-unidade, sem considerar
140
o tempo.
Figura 8.2 Total de pares bairro-unidade (eixo y) que compartilham
142
exatamente Pc pacientes (eixo x).
Figura 8.3 Distância média dos pares (eixo y) que compartilham Pc pacientes
142
(eixo x).
Figura 8.4 Medida de Interação Espacial – IE (eixo y) que compartilham Pc
143
pacientes (eixo x).
Figura 8.5a Rede de bairros e unidades hospitalares, 1985, município do Rio
145
de Janeiro, visualização com NetDraw.
Figura 8.5b Rede de bairros e unidades hospitalares, 1988, município do Rio
xx
145
de Janeiro, visualização com NetDraw.
Figura 8.6 Total de interações entre bairros (lista parcial) e respectivas
146
unidades hospitalares de saúde, 1985 a 2005, município do Rio de Janeiro.
Figura 8.7 Unidade de saúde mais utilizada por bairro, a tonalidade cinza
representa uma unidade hospitalar, 1982 a 2005, município do Rio de Janeiro.
xxi
146
LISTA DE TABELAS
Tabela 4.1 Estrutura de árvore com informações de relação espacial por objeto
46
Tabela 4.2. Seleção de polígonos com a relação espacial de direção e distância
47
Tabela 4.3a Resultados da RNA de predição da taxa de contaminação por
48
bairro com IF
Tabela 4.3b Resultados da RNA de predição da taxa de contaminação por
49
bairro sem IF
Tabela 5.1 Atributos econômico-sociais de um dos agrupamentos.
62
Tabela 5.2 Resultado do agrupamento de dados por categoria [somente o
64
agrupamento com os maiores valores], períodos de 1982 até 1985 e 1986 até
1988, município do Rio de Janeiro.
Tabela 5.4 Resultado do agrupamento de bairros por categoria de exposição
68
[somente o agrupamento com os maiores valores], valor máximo por categoria,
1982 a 2005, município do Rio de Janeiro.
Tabela 5.5 Tabela de bairros com maiores reduções da razão de sexos, 1989 e
70
1999.
Tabela 5.6 Bairros com maior percentual de pacientes com escolaridade de 8 a
72
11 anos.
Tabela 6.1 Índice de Influência Espacial por direção-padrão, 1988 e 1999.
80
Tabela 6.2 Espectro cruzado entre as séries de óbitos e de escolaridade de um a
94
três anos.
Tabela 6.3 Espectro cruzado entre as séries de óbitos e de escolaridade de1 a 3
94
anos.
Tabela 6.4 Erros de treinamento e verificação da RNA MLP de 3 camadas.
xxii
95
Tabela 6.5 Resultado parcial da RNA para predição da taxa de contaminação
97
para cinco bairros.
Tabela 7.1 Distribuição de freqüência de distância (total de vértices) entre uma
112
notificação de aids e a anterior, 1982 a 1985, município do Rio de Janeiro.
Tabela 7.2. Tabela comparativa de limiar médio e freqüência acumulada de
127
bairros com o primeira notificação de aids no ano, 1982 a 1992, município do
Rio de Janeiro.
Tabela 7.3 Bairros com os maiores valores de limiar e respectiva taxa de
contaminação no ano da primeira ocorrência de aids.
xxiii
129
LISTA DE SÍMBOLOS
d
dimensão do vetor de características xk
dij
distância entre os neurônios i e j
du
distância calculada a partir dos valores dx, dy e dz
dx
distância entre o vetor de código de um neurônio e o seu vizinho à direita
dy
distância entre o vetor de código de um neurônio e o seu vizinho abaixo
dz
distância entre o vetor de código de um neurônio e o seu vizinho na diagonal
Eq
erro de quantização vetorial
I
espaço de entrada da rede neural SOM
kj
j-ésimo componente do vetor xk, j = 1, ..., d
m
dimensão horizontal da rede neural SOM
n
dimensão vertical da rede neural SOM
O
polígono ou objeto (geo-objeto)
U
espaço de saída da rede neural SOM
W
matriz de proximidade
wij
elementos da matriz de proximidade
wj
vetor de código ou pesos do neurônio j
x, y
coordenadas geodésicas relativas ao centróide do polígono (área)
xk
vetor de características da rede neural SOM k = 1, ..., n
xxiv
LISTA DE SIGLAS E ABREVIATURAS
AIDS
síndrome de imunodeficiência humana adquirida.
BMU
neurônio vencedor na fase competitiva da RNA, do termo em inglês Best
Match Unit.
DALY
anos de vida saudável perdidos por morte prematura, deficiência ou
incapacidade.
EVA
exploratory visual analisys.
FFT
Fast Fourier Transform
GPS
sistema de posicionamento global, do termo em inglês Global
Positioning System.
HIV
vírus da imunodeficiência humana adquirida
IBGE
Instituto Brasileiro de Geografia e Estatística.
IF
índice de influência espacial local.
IFd
índice de influência espacial direção d.
INPE
Instituto Nacional de Pesquisa Espacial.
KDD
descoberta de conhecimento em bases de dados, do termo em inglês,
knowledge discovery in databases.
MLP
rede de múltiplas camadas, do termo em inglês Multi-Layer Perceptron.
OMS
Organização Mundial de Saúde.
PAJEK
software livre de análise exploratória de redes sociais.
RNA
rede neural artificial.
SIG
sistema de informações geográficas.
SOM
mapa auto-organizável do termo em inglês, Self-Organizing Map.
SPRING
software livre de manipulação de banco de dados geográficos
desenvolvido pelo INPE.
SQL
linguagem de manipulação do termo em inglês, Structured Query
Language.
SWOT
análise dos pontos fortes e fracos, das oportunidades e ameaças, do termo
em inglês, strentghs, weakness, opportunities and threats.
UDI
usuário de drogas injetáveis (categoria de exposição)
xxv
CAPÍTULO 1
INTRODUÇÃO
1.1 Introdução
O cálculo infinitesimal funciona tornando visível o que é infinitamente pequeno. Sem
ele, não há como compreender o que mantém o avião no ar. O que faz com que objetos
caiam no chão quando os largamos é a gravidade. Mas são as equações newtonianas do
movimento e da mecânica que nos permitem ver as forças invisíveis, que fazem que
uma maçã caia da árvore até o chão.
A Descoberta de Conhecimento em Bases de Dados torna visível os padrões existentes
em grandes volumes de dados. O desenvolvimento de tecnologias, como a internet e os
sistemas de informação em geral, prescinde do desenvolvimento de ferramentas que
auxiliem o homem na tarefa de analisar, interpretar e relacionar esses dados,
transformando-os em conhecimento útil e viabilizando o desenvolvimento de estratégias
de ação.
Inúmeras pesquisas têm comprovado a importância da informação no fortalecimento da
competitividade e no sucesso de empresas. A habilidade de identificarem-se riscos e
oportunidades de negócio torna-se mais complexa em razão da abundância de dados e,
principalmente, da rapidez do fluxo de informações. Esta pesquisa se posiciona neste
contexto: analisar grandes volumes de dados, sempre com o foco no negócio da
empresa.
Na área de saúde pública o foco deveria ser a redução dos índices de
morbidade e mortalidade da população.
A descoberta de conhecimento em bases de dados é definida como a busca efetiva por
conhecimentos úteis e novos. Esse processo é usualmente denominado KDD, do inglês,
knowledge discovery in databases.
KDD é um processo, de várias etapas, não trivial, interativo e iterativo, para
identificação de padrões compreensíveis, válidos, novos e potencialmente úteis
a partir de grandes conjuntos de dados (FAYYAD et. al., 1996).
1
Esta pesquisa propõe-se a ampliar o conceito de novo. Considerou-se todo o
conhecimento útil, ainda que não necessariamente desconhecido. Consoante com essa
proposta, o conhecimento prévio que foi analisado por uma nova abordagem e que,
como conseqüência, criou suposições ou simplesmente ampliou o conhecimento sobre o
objeto estudado, foi considerado tão importante como o conhecimento novo.
Nesse sentido, a descoberta de conhecimento em bases de dados deve ser conceituada
como a busca por padrões que propiciem o desenvolvimento ou a competitividade de
uma empresa. O aumento da competitividade ocorre devido à informação adquirida que
auxiliará na identificação de riscos e oportunidades e no conhecimento dos pontos fortes
e fracos do negócio. Na área de saúde, a competitividade poderia ser medida por
intermédio da redução das taxas de mortalidade e morbidade.
Buscaram-se relacionar todos os dados ao espaço geográfico, por meio da mineração de
dados espaciais. Segundo AGRAWAL (1994), a principal diferença entre a mineração
de dados convencional e a espacial é que a primeira utiliza números e categorias, e a
segunda, além de números e categorias, utiliza linhas, polígonos e pontos, o que a torna
mais complexa. Além disso, a mineração de dados clássica faz uso de dados explícitos,
e atributos espaciais sempre são implícitos. Finalmente, na mineração de dados clássica,
cada entrada de dados é independente das demais, e padrões espaciais sempre possuem
alta correlação entre atributos de vizinhança e proximidade.
1.2 Motivação
A mineração de dados geográficos integrada a redes complexas introduz novos desafios
e problemas. A principal motivação da pesquisa baseou-se na necessidade crescente de
técnicas de mineração de dados específicas para dados espaciais. Essa necessidade é
explicada pela disponibilidade de dados de satélites e de mapas urbanos digitais de
cidades, além da ampliação da coleta de dados com uso de sistemas GPS (global
positioning systems). O desenvolvimento de tecnologias possibilita armazenar grandes
volumes de dados. No entanto, a capacidade de analisar estes dados, transformando-os
em conhecimento útil é muito inferior à capacidade de produção e armazenamento.
2
1.3 Objetivo
O objetivo principal é realizar a descoberta de conhecimento em uma base de dados de
notificações de contaminação pelo vírus HIV.
Os objetivos mais específicos são:
Propor uma medida de dependência espacial.
Aplicar a proposta na análise da epidemia pelo vírus HIV, no município do Rio de
Janeiro.
Integrar os resultados da mineração de dados geográficos usando redes complexas.
1.4 Contribuição
A principal contribuição desta pesquisa são os resultados da descoberta de
conhecimento em bases de dados propriamente ditas, ou seja, são os resultados obtidos
com as tarefas de mineração de dados na base de dados de notificações da epidemia
pelo vírus HIV.
A descoberta de conhecimento é complexa porque nos obriga a pensar sobre como
objetos e relacionamentos podem ser identificados e representados e como padrões até
então desconhecidos podem ser descobertos em grandes bases de dados. Não há uma
técnica, mas diversas técnicas que, usadas pelo especialista da área, podem resultar em
conhecimento novo e útil.
A proposta de realizar a descoberta de conhecimento, integrando-se tarefas de
mineração de dados geográficos e redes complexas é mais uma contribuição. Ressaltese ainda, o índice de influência espacial proposto e utilizado nas tarefas de mineração
de dados geográficos.
A proposta não possui paralelo na literatura pesquisada.
3
1.5 Contexto
A definição estática da Organização Mundial da Saúde (OMS) que definia a saúde
como o estado de completo bem-estar foi superada. Nas definições atuais, ela é
dependente da dinâmica social e de políticas econômicas e culturais. Assim sendo, os
níveis de padrão sanitário dependem muito mais de políticas econômicas, sociais e de
aspectos culturais do que da intervenção da medicina propriamente dita. A idéia de que
a saúde relaciona-se com as condições ambientais e de vida da população é muito
antiga. Entretanto, somente a partir do desenvolvimento da medicina social, nos séculos
XVIII e XIX, pesquisas sistemáticas deram subsídios a essa tese. Estudos como
Mortalidade Diferencial na França, realizado por Villermé, são citados na reconstituição
da história da saúde pública, mostrando a íntima relação entre a questão social, a
degradação ambiental e os indicadores negativos de saúde.
Em 1986, na conferência de Otawa, foi definido o conceito do que se considera
promoção de saúde. O documento A New Perspective on the Health of Canadians
(LALONDE, 1978), conhecido como Informe Lalonde, posiciona a questão da saúde
com base em uma perspectiva sociopolítica, técnica, econômica e médica por
intermédio dos chamados determinantes da saúde de um povo: condições e estilos de
vida, situação ambiental, desenvolvimento da biologia e organização da assistência à
saúde.
A Lei 8080/1990, que regulamentou o capítulo da Constituição Federal de 1988,
referente à saúde da população brasileira, relaciona, de forma inequívoca, os níveis de
saúde à organização social e econômica do País.
Pelos motivos expostos, observou-se a oportunidade de utilizarem-se representações
computacionais mais adequadas para capturar conhecimento sobre saúde. SIGs
oferecem um conjunto de estruturas de dados e algoritmos capazes de representar a
grande diversidade de concepções do espaço.
4
1.6 Organização do Trabalho
O presente trabalho é composto de três partes distintas. A primeira parte apresenta o
objetivo, os conceitos e uma proposta de medida de dependência espacial, denominada
índice de influência espacial. Dependência espacial é o impacto que a variação na
localização espacial causa na variação dos atributos, ou seja, é a medida de como os
atributos são dependentes do espaço geográfico.
Esta parte é composta por quatro
capítulos.
A segunda parte, composta pelos capítulos cinco e seis, apresenta a aplicação do índice
nas tarefas de mineração de dados geográficos, grande parte delas realizada
intermédio de Mapas Auto-Organizáveis (KOHONEN, 2001).
por
Com base nos
resultados obtidos com as tarefas de mineração de dados geográficos, foram
identificadas as fases de evolução da epidemia. Esta parte inclui dois modelos para
predição da evolução da epidemia com óbito. Apresenta também uma modelagem
espaço-temporal.
Finalmente, a terceira parte integra os conhecimentos obtidos usando a abordagem de
redes complexas, sendo composta pelos capítulos sete, oito e nove.
O presente capítulo apresenta a proposta, o objetivo e a contribuição da pesquisa. Os
conceitos necessários ao entendimento do capítulo, quando houver, são apresentados em
tópico especifico. O tópico Sistemas, Software e Dados assim como o tópico Resumo
são repetidos em cada capítulo.
No segundo capítulo, os principais conceitos sobre KDD, SIG, visualização geográfica e
redes sociais, essenciais para o entendimento deste trabalho, são apresentados de forma
sucinta.
O terceiro capítulo apresenta uma proposta de metodologia para KDD.
Esta
metodologia se propõe a integrar a abordagem tradicional, conforme a proposta por
FAYYAD et. al. (1996) à abordagem estratégica com foco na identificação de riscos e
oportunidades, pontos fortes e fracos, conforme proposto PORTER (1989) e KAPLAN
5
(2004). A metodologia propõe que a descoberta de conhecimento seja executada em
três fases: conceitual, estrutural e de implantação. A metodologia proposta foi aplicada
no presente trabalho.
O quarto capítulo apresenta uma proposta de medida de dependência espacial,
denominada índice de influência espacial. Dependência espacial é a medida de como os
atributos são dependentes do espaço geográfico.
Uma aplicação do índice é
apresentada, por intermédio de uma tarefa de mineração de dados, cujo objetivo é
realizar a predição da taxa de contaminação de um bairro, baseada nas respectivas taxas
dos bairros vizinhos. Demonstrou-se que a consideração do índice proposto nesta
tarefa, reduziu o erro associado à predição.
O quinto capítulo apresenta uma aplicação do índice de influência espacial como
medida de conectividade, com o objetivo de segmentar as fases de evolução da
epidemia. Nessa fase da pesquisa, o objetivo principal foi identificar padrões através
dos agrupamentos de dados. Os resultados comprovaram que a epidemia é o resultado
de elementos tão heterogêneos como condições econômicas, condições sanitárias,
parceiro sexual e nível social, citando somente alguns.
O sexto capítulo apresenta a análise da evolução da epidemia pelo vírus HIV. Apresenta
uma aplicação do índice de influência espacial como medida de conectividade, com o
objetivo de segmentar as fases de evolução da epidemia.
Apresenta ainda, o
desenvolvimento de dois modelos para predição da evolução da aids com fechamento
óbito e uma modelagem espaço-temporal.
No sétimo capítulo, a epidemia é analisada com a abordagem de redes complexas. Os
padrões identificados, resultantes da mineração de dados geográficos, serão analisados
com essa abordagem. O capítulo apresenta a influência da estrutura da rede formada na
difusão da epidemia e o momento da formação da massa critica na evolução da
epidemia.
O oitavo capítulo apresenta uma proposta para analisar o movimento dos pacientes
entre bairros e unidades hospitalares de saúde.
Esse estudo contribuiu para a
compreensão da epidemia. Definiu-se um critério de interação espacial baseado no total
6
de ocorrências comuns ao par formado pelo bairro e unidade hospitalar. A análise
indicou uma forte correlação entre bairro-unidade e espaço geográfico, conforme
esperado. Outras análises e conclusões são apresentadas.
O nono capítulo é a conclusão. Não existe uma explicação puramente técnica ou uma
determinação social que justifique o desenvolvimento da epidemia. O conhecimento
das redes, das relações complexas que as formam e das interações operadas nos levará a
compreender, um pouco mais, a epidemia.
O estudo buscou entender as muitas traduções do desenvolvimento da epidemia pelo
vírus HIV. A mais expressiva tradução, operada pelos atores dessa rede complexa, foi a
necessidade de ações mais ofensivas ao combate, tratando desigualmente os bairros do
município. O estudo tenta provar que ações específicas, com foco nas regiões com as
maiores taxas de contaminação, podem criar condições para melhoria em relação aos
índices atuais de contaminação da população do município do Rio de Janeiro.
7
CAPÍTULO 2
REVISÃO BIBLIOGRÁFICA
2.1 Introdução
O presente capítulo apresenta a revisão bibliográfica das principais áreas abordadas.
Entretanto, não há a pretensão de aprofundar os assuntos. Nesse caso, as referências
apresentadas na revisão bibliográfica de cada tema podem ser úteis. O objetivo do
capítulo é apresentar os principais conceitos e, principalmente, como a pesquisa se
beneficiou dos mesmos.
2.2 Descoberta de Conhecimento em Bancos de Dados (KDD)
O desenvolvimento da descoberta de conhecimento em bases de dados coincide com a
viabilização de grandes bases de dados.
A complexidade do processo KDD está na
dificuldade em perceber e interpretar corretamente inúmeros fatos observáveis e, na
dificuldade em conjugar dinamicamente tais interpretações, tornando-as úteis ao
processo de decisão. KDD refere-se às etapas que produzem conhecimentos a partir de
dados relacionados e sua principal característica é a extração não trivial de informações
implicitamente contidas em uma base de dados.
Os objetivos compreendem as características esperadas do modelo de conhecimento a
ser produzido ao final do processo. Tais objetivos retratam, portanto, restrições e
expectativas dos especialistas acerca do modelo de conhecimento a ser gerado e podem
ser classificados em dois grupos: (1) verificação e (2) descoberta.
A verificação
objetiva comprovar uma hipótese do usuário. Na descoberta, objetiva-se encontrar
novos padrões.
descrição.
A descoberta de padrões, por sua vez, se divide em predição ou
Na predição, os padrões são usados para prever o comportamento de
determinado fenômeno do mundo real. Na descrição, os padrões são usados na tentativa
de descrever esse fenômeno através de um modelo.
8
O processo KDD é interativo e iterativo, envolvendo várias etapas, nas quais algumas
decisões são feitas pelo usuário. Diferentes abordagens para o desenvolvimento do
processo foram apresentadas. FAYYAD et. al. (1996) propôs o desenvolvimento em
nove etapas:
1.
Desenvolvimento do conhecimento sobre o problema e os objetivos do usuário;
2.
Definição dos dados que serão utilizados no processo de
descoberta de
conhecimento;
3.
Limpeza dos dados e pré-processamento;
4.
Redução e transformação dos dados;
5.
Definição da tarefa de mineração de dados;
6.
Escolha do algoritmo de mineração de dados;
7.
Mineração de dados: regras de associação, regressão, agrupamento de dados, etc.
8.
Avaliação dos resultados;
9.
Consolidação do conhecimento descoberto, incorporação desse conhecimento
nos respectivos processos ou sistemas ou, simplesmente, documentar e transmitir esse
conhecimento aos usuários do sistema.
Apesar da proposta de FAYYAD et. al. (1996) aparentemente sugerir um processo
seqüencial, o processo KDD é circular. Ao longo do processo, o modelo é avaliado com
relação ao cumprimento das expectativas definidas.
Os resultados finais obtidos
compreendem fundamentalmente o modelo de conhecimento descoberto. A expressão
modelo de conhecimento indica qualquer abstração de conhecimento, expresso em
alguma linguagem, que descreve algum conjunto de dados (FAYYAD et. al., 1996).
2.2.1 Mineração de Dados
A descoberta de padrões em dados tem recebido diversas denominações incluindo
mineração de dados, extração de conhecimento, processamento de padrões e outras.
Historicamente, o termo mineração de dados tem sido utilizado para a análise
exploratória de dados quando não existe uma hipótese “a priori” a ser validada
(FAYYAD et. al, 1996). Na visão atual, mineração de dados é a denominação de uma
9
das etapas do processo KDD e refere-se à aplicação de algoritmos sobre os dados para a
descoberta de padrões.
O processo KDD evoluiu a partir de áreas de pesquisa como aprendizado de máquina,
reconhecimento de padrões, estatística, inteligência artificial, computação de alto
desempenho e visualização de dados, entre outras. Usualmente KDD utiliza essas
técnicas, em uma etapa do processo denominada mineração de dados. Isso distingue
KDD de áreas de pesquisa a partir das quais ele evoluiu. A escolha da técnica de
mineração de dados a ser utilizado depende da tarefa de descoberta do conhecimento a
ser realizada. Tarefas típicas de mineração de dados são descoberta de associações,
agrupamento de dados, classificação, sumarização e predição.
RAINSFORD e RODDICK (1999) apresentam significativas abordagens sobre
mineração de dados.
2.2.2 Perspectivas do Processo de Descoberta do Conhecimento
Segundo RAMAKRISHMAN e GRAMA (1999) a construção do conhecimento do
processo KDD ocorre em quatro perspectivas: indução, compreensão, consulta e
aproximação.
A indução é a perspectiva mais comum, tendo sua origem na inteligência artificial (IA)
e no conceito de aprendizagem por exemplos (machine learning). HUNT et al. (1996)
foi um dos primeiros pesquisadores a estudar o conceito de aprendizagem por exemplos,
utilizando árvores de decisão para realizar operações de classificação. Recentemente,
CAI et al. (1991): HAN e FU (1995) implementaram algoritmos que utilizam esse
conceito em operações de bancos de dados. Basicamente, um algoritmo de indução
baseia-se na generalização e sumarização dos relacionamentos entre atributos de um
conjunto de dados. O principal objetivo da indução é extrair regras genéricas dos dados
e identificar irregularidades. Vários autores, como HAN et al. (1996) e WANG et al.
(1997) têm pesquisado métodos de indução com objetivo de extrair generalizações de
dados espaciais.
10
A perspectiva da compreensão orienta a seleção de um modelo em mineração de dados.
Um modelo é considerado bom quando utiliza qualquer variável, relacionamento ou
comportamento relevante e ignora os irrelevantes. Um modelo deve capturar a essência
do conhecimento do objeto de estudo buscando a simplicidade.
Na perspectiva denominada consulta, a construção do conhecimento ocorre através de
consultas convencionais às bases de dados. Grande parte dos sistemas gerenciadores de
bancos de dados não é adequada ao processo de descoberta de conhecimento.
Entretanto, vários esforços têm sido realizados para adequar as linguagens de consulta,
como o SQL, às necessidades das tarefas de KDD. Um exemplo é a abordagem que
utiliza regras de semântica para formular uma consulta, como as propostas de HSU e
KNOBLOCK (1996); SHEKKAR et. al. (1993); SIEGEL (1998) e a abordagem FOIL
QUINLAN (1990).
Finalmente, a perspectiva de aproximação baseia-se no conhecimento prévio de um
modelo. A pesquisa do esquema (de dados) de um banco de dados, a fim de encontrar
conhecimento útil e até então desconhecido, é um exemplo. Outro exemplo é a matriz
de aproximação linear utilizada para identificar padrões em textos sem utilizar a busca
por palavras-chave, conhecida por Latent Semantic Indexing e patenteada por Bellcore.
2.2.3 KDD: Revisão Bibliográfica
Pesquisas sobre o processo KDD e mineração de dados são inúmeras, como as
propostas de FAYYAD et. al. (1996) e MATHEUS et. al. (1993), entre outros. Uma
revisão de ferramentas e softwares utilizados no processo KDD e na tarefa de mineração
de dados foi apresentada por GOEBEL e GRUENWALD (1999).
Propostas para a
tarefa de redução dos dados foram apresentadas por REINARTZ (1999).
Uma das principais tarefas de mineração de dados, o agrupamento de dados consiste em
separar os registros de uma base de dados em agrupamentos (usualmente referenciados
pela palavra em inglês cluster) de tal forma que os elementos de um agrupamento
compartilhem de propriedades comuns. Diferente da tarefa de classificação, que utiliza
rótulos predefinidos, o agrupamento de dados precisa automaticamente identificar os
11
grupos de dados (FAYYAD et. al. 1996). A análise de cluster é uma técnica utilizada
para identificar as relações existentes entre um número de variáveis com o objetivo de
explicar um conjunto de fenômenos.
Essa técnica permite retirar uma extraordinária
quantidade de informações e conhecer a existência de certos padrões nos dados.
A análise de cluster estuda os componentes das variáveis, identificando dimensões
abstratas, classificando os dados, unindo-os pelas semelhanças ou pelas diferenças. A
maioria dos métodos de agrupamento utiliza métodos de particionamento, como Kmeans, no qual o usuário define alguns parâmetros e a quantidade de grupos (k-clusters)
nos quais os registros serão distribuídos. Algoritmos apropriados realizam o cálculo de
distâncias entre os elementos de dados, visando identificar o centróide e estabelecer os
limites que formam o agrupamento ao redor do centróide.
A qualidade do resultado do agrupamento também depende da medida utilizada pelo
método para calcular a similaridade, além de sua habilidade de descobrir algum ou
todos os padrões escondidos. Alguns exemplos de agrupamento de dados que utilizam
regras de similaridade são: Clustering Applications based upon randomized Search
(CLARANS) em NG e HAN (1994) e Balanced Iterative Reducing and Clustering
(BIRCH) em ZHANG et. al. (1996). Duas extensões do CLARANS (ESTER et. al.
1995) são Spatial Dominant Algorithm (SD-CLARANS) e Non-spatial Dominant
Algorithm (DSD-CLARANS) para dados espaciais e não espaciais respectivamente.
A classificação examina rótulos ou categorias predefinidas, separando os dados de
acordo com critérios, modelos e regras. Muitos algoritmos de classificação baseiam-se
em métodos estatísticos como distribuição de probabilidade, matrizes de correlação de
coeficientes e formulação de hipóteses para extrair classes de um conjunto de dados.
algoritmos de classificação ID3 e C4.5 foram apresentados por QUILAN (1986) e
(1993) e árvore de classificação e regressão (CART) por BREIMAN et. al. (1984).
A descoberta de regras de associação abrange a identificação de itens que
freqüentemente ocorrem de forma simultânea em transações de bancos de dados. É um
tipo especial de análise de dependência, conforme apresentado por AGRAWAL et. al.
(1996).
12
A generalização consiste em encontrar uma descrição concisa dos dados. O objetivo é
prover múltiplas perspectivas dos dados, permitindo a identificação de características
que existem somente em algum nível conceitual (nível de abstração). A generalização
apresenta características similares à generalização utilizada em cartografia.
Os
sistemas DBMiner (HAN et. al. 1996) e GeoMiner (HAN et. al., 1997) são exemplos de
sistemas de descoberta de conhecimento em bases de dados que realizam a tarefa de
generalização.
2.3 Sistema de Informações Geográficas (SIG)
O termo sistema de informação geográfica (SIG) é aplicado para sistemas que realizam
o tratamento computacional de dados geográficos. A principal diferença de um SIG para
um sistema de informação convencional é sua capacidade de armazenar tanto os
atributos não espaciais como as geometrias dos diferentes tipos de dados geográficos.
Um importante conceito é a distinção entre espaço absoluto e espaço relativo. Espaço
absoluto, também chamado cartesiano, é um conjunto de coisas e eventos, uma estrutura
para localizar pontos, trajetórias e objetos. Espaço relativo é o espaço constituído pelas
relações espaciais entre coisas.
Uma das escolhas básicas que fazemos na modelagem dos fenômenos geográficos é
definir se utilizaremos representações no espaço absoluto ou no espaço relativo. Esta
escolha depende primordialmente do tipo de análise desejada.
Relações de
conectividade como “Qual é a mortalidade por epidemia do vírus HIV de meus
vizinhos?” requerem a representação no espaço relativo.
No presente trabalho, as
relações de conectividade foram consideradas, assim como as questões da álgebra de
mapas, utilizada para responder perguntas como: “Que áreas possuem contaminação
superior a 25% e renda familiar inferior a dois salários mínimos?”, nesse caso,
utilizando-se o espaço absoluto.
2.3.1 Espaço Absoluto: Geo-campo e Geo-objeto
Existem dois modelos formais para entidades geográficos no espaço absoluto: geocampos e geo-objetos. O modelo de geo-campos enxerga o espaço geográfico como
13
uma superfície contínua, sobre a qual variam os fenômenos a serem observados. Por
exemplo, um mapa de vegetação associa a cada ponto do mapa um tipo específico de
cobertura vegetal. O modelo de geo-objetos representa o espaço geográfico como uma
coleção de entidades distintas, onde cada entidade é definida por uma fronteira fechada.
O geo-objeto é uma entidade geográfica singular e indivisível, caracterizada por sua
identidade, suas fronteiras, e seus atributos. Um geo-objeto é uma relação [id, a1,...an,
G], onde id é um identificador único, G é um conjunto de partições 2D conexas e
distintas {R1,...,Rn} do espaço
,, e ai são os valores dos atributos A1,...,An.
2
As Figuras 2.1a e 2.1b representam, respectivamente, um geo-campo (uma imagem da
cidade do Rio de Janeiro) e um conjunto de geo-objetos (os bairros dessa cidade). A
variável associada à imagem da Figura 2.1a é a reflectância do solo, medida pelo sensor
óptico do satélite. Os geo-objetos associados aos bairros do Rio de Janeiro são
apresentados numa gradação de tons de cinza, cuja intensidade é proporcional à renda
familiar na Figura 2.1b (SANTOS, F.F. e EBECKEN, N.F.F, 2006).
Figura 2.1a Geo-campo (INPE)
Figura 2.1b Geo-objeto: análise da saúde segundo
renda familiar, município do Rio de Janeiro.
A diferença essencial entre um geo-campo e um geo-objeto é o papel da fronteira. A
fronteira de um geo-campo é uma divisão arbitrária relacionada apenas com a
capacidade de medição. Na figura acima, os limites da imagem correspondem apenas a
eventuais limitações do instrumento sensor e não do fenômeno medido. Assim, o geocampo pode ser divido em partes e ainda assim manter sua propriedade essencial (que é
14
sua função de atributo). Por outro lado, um geo-objeto é essencialmente definido por
sua fronteira, que o separa do mundo exterior. O geo-objeto não pode ser dividido e
manter suas propriedades essenciais. Dentro da fronteira, todas as propriedades do geoobjeto são constantes. É bastante comum lidarmos com um conjunto de geo-objetos que
representam uma partição consistente do espaço; isto é, os recobrimentos espaciais
destes objetos não se interceptam e eles possuem o mesmo conjunto de atributos. Estas
características fazem com que possamos agrupar estes objetos numa coleção.
Uma coleção de geo-objetos é a relação [id, o1,...on, A1,..., An], onde id é um
identificador único, e o1,...on são geo-objetos que possuem os atributos A1,..., An.
Usualmente, se Ri for a região geográfica associada a oi, temos Ri
Rj = ∅,
i
j
.
Deste modo, uma coleção reúne geo-objetos cujas fronteiras não se interceptam, e têm o
mesmo conjunto de atributos. O uso de coleções de geo-objetos é bastante freqüente em
bancos de dados geográficos, pois é muito conveniente tratar geo-objetos similares de
forma consistente. Na presente pesquisa, utilizaram-se os termos polígono e objeto para
denominar geo-objetos.
2.3.2 SIG: Revisão Bibliográfica
As pesquisas desenvolvidas para integração e análise dos dados aqui denominados geo
referenciados, tem surgido em áreas tradicionais, como métodos estatísticos, assim
como Inteligência Artificial, citando DRUCK et. al. (2004) e CASANOVA et. al.
(2005).
2.4 Visualizacao Geográfica
O termo visualização geográfica refere-se à apresentação de geometrias dos diferentes
tipos de dados geográficos para a exploração de dados, geração de hipóteses, solução de
problemas e descoberta de conhecimento (MacEACHEREN, 2000).
Constitui um
processo de pesquisa e “rastreamento” que envolve o pensamento cognitivo e a
descoberta de conhecimento através da interação homem-máquina. A visualização
geográfica é utilizada em inúmeras disciplinas sendo mais conhecida na cartografia.
15
Os mecanismos de visualização devem oferecer suporte para apreensão cognitiva dos
aspectos relevantes dos dados pesquisados (MacEACHEREN, 2004). A construção de
conhecimento ocorre através da interação com uma ou várias representações visuais.
Toda representação visual influencia a forma como interpretamos e analisamos os dados
e, conseqüentemente, a construção do conhecimento.
Diferentes técnicas de
representação visual possibilitam diferentes formas de construção do conhecimento
através dos diferentes estágios do processo.
Assim sendo, é crucial o uso de
representação visual apropriada à construção do conhecimento.
Cada SIG possui
características que o distingue dos demais. Além disso, os usuários do sistema usam
suas idiossincrasias, experiências, conhecimento e habilidades pessoais na construção
do conhecimento o que torna sua implementação uma tarefa difícil e complexa.
2.4.1 Visualização Geográfica: Revisão Bibliográfica
O uso da visualização geográfica na análise exploratória de dados, análise de dados,
mineração de dados e descoberta de conhecimento tem origem no trabalho pioneiro de
ASIMOV (1985), CHERNOFF (1978), HASLETT et. al. (1990), TUKEY(1977) e
TUFTE (1990), baseada na premissa que “mapas descrevem dados” e em BERTIN
(1985), MACKINLAY (1986), TRIESMAN (1986) que, com outros pesquisadores,
estudaram variáveis visuais, como forma e posição, e como essas variáveis podem ser
usadas na construção de mapas.
O termo Exploratory Visual Analysis (EVA) foi criado por estatísticos para descrever
métodos exploratórios que se baseiam no domínio visual. Recentemente, ferramentas
de visualização que auxiliam as atividades de mineração de dados foram propostas por
(KEIM e KRIEGEL, 1996; LEE e ONG, 1996) que criaram o termo Visual Data
Mining (VDM).
MacEACHREN et. al. (1999) iniciou a pesquisa de métodos de
descoberta de conhecimento baseado em exploração visual. As diferenças entre EVA e
VDM são sutis. EVA tende a ser mais interativo, baseando-se na percepção do usuário,
sem o controle rígido do formato de dados.
De forma contrária, o VDM utiliza
algoritmos específicos para encontrar padrões a partir das características numéricas dos
dados e de teorias estatísticas, reconhecimento de padrões e aprendizagem de máquina.
VDM tende a ser usado em grandes bases de dados. EVA tende a ser mais utilizado em
16
arquivos com grande dimensão de atributos, porém, com pequena quantidade de
instâncias.
RIBARSKY et. al. (1999) integrou as vantagens das duas abordagens para explorar
dados temporais e introduziu o termo Discovery Visualization para enfatizar a
importância da visualização na interação homem-máquina. A visualização geográfica
recebeu diferentes denominações. Na comunidade de banco de dados a denominação
mais utilizada é Visual Datamining (RIBARSKY et. al., 1999), enquanto o termo
Exploratory Visual Analysis ou Exploratory Data Analysis são mais utilizados por
estatísticos como TUKEY (1977), CHERNOFF (1978) ASIMOV(1985). Na geografia,
o termo mais utilizado é Exploratory Spatial Data Analysis.
Ferramentas para auxiliar a mineração de dados baseadas na visualização geográfica
foram desenvolvidas por LEE e ONG (1996) e KEIM e KRIEGEL (1996). Alguns
métodos de visualização geográfica para a descoberta de conhecimento foram propostos
por MacEACHREN et. al. (1999) e HAN et. al. (1999).
Uma visão geral da
geoinformação sob o ponto de vista de sistemas foi apresentada por WORBOYS e
DUCKHAM (2004).
DRUCK et.
al. (2004) apresentou uma discussão sobre as
questões de análise espacial de dados geográficos e CASANOVA et. al. (2005) sobre
banco de dados geográficos.
2.5 Redes Complexas
A pesquisa de Redes Complexas baseia-se na teoria de grafos. Alguns conceitos como
arco e linha de conexão são importantes. Uma linha pode ser direcionada ou não
direcionada. Uma linha direcionada chama-se arco, enquanto uma linha não direcionada
chama-se linha de conexão. Usualmente, em redes complexas, uma escolha é
representada por arcos (com direção), porque uma escolha nem sempre é recíproca.
Como exemplo, na análise da epidemia do vírus HIV, utilizaram-se os conceitos de
redes complexas para identificar a relação entre bairros. Assim sendo, a relação entre
um paciente que assiste em um bairro e freqüenta uma unidade hospitalar de outro
bairro, não implica na existência da conexão em sentido contrário.
17
Um grafo direto ou dígrafo contém um ou mais arcos. Uma relação que não é
direcionada (pacientes com vírus HIV da mesma família) é representada por uma linha
de conexão porque ambos os indivíduos estão igualmente envolvidos na relação. Um
grafo não direcionado não contém arcos: todas suas linhas são linhas de conexão.
Formalmente, um arco é um par de vértices ordenados onde o primeiro vértice é o
emissor (o final do arco) e o segundo o receptor do vínculo (a cabeça do arco). Um arco
aponta de um emissor para um receptor. Em contrapartida, uma linha de conexão, que
não tem direção é representada por um par desordenado. Não tem importância qual
vértice é primeiro ou segundo no par. Deve ser observado, porém, que uma linha de
conexão equivale, geralmente, a um arco bidirecional.
A rede de pacientes e unidades de saúde possui linhas múltiplas porque o mesmo
paciente pode utilizar inúmeras unidades de saúde. Entretanto, quando um grafo é
simples, significa que não possui linhas múltiplas. Além disso, um grafo simples não
direcionado não contém laços (arco para o próprio vértice), enquanto os laços são
permitidos num grafo simples direcionado.
Finalmente, uma rede consiste de um grafo e informações adicionais nos vértices ou
linhas do grafo. Os valores de linha geralmente indicam a força de uma relação. A
informação adicional é irrelevante para a estrutura da rede, porque a estrutura depende
do padrão de vínculos.
2.5.1 Redes Complexas: Revisão Bibliográfica
A teoria das redes tem origem com o matemático Euler, responsável pelas primeiras
pesquisas nessa área e pela teoria dos grafos. O grafo é um conjunto de nós, conectados
por arestas que, em conjunto, formam uma rede. Na sociologia, a teoria dos grafos é
uma das bases do estudo das redes sociais, ancorado na Análise Estrutural, proveniente
das décadas de 60 e 70. A análise das redes sociais parte de duas grandes visões do
objeto de estudo: as redes internas e as redes personalizadas. O primeiro aspecto é
focado na relação estrutural da rede com o grupo social – as redes são assinaturas de
identidade social, o padrão de relações do indivíduo mapeia as preferências e as
18
características dos próprios envolvidos na rede. O segundo aspecto diz que o papel de
um indivíduo poderia ser compreendido não apenas através dos grupos – redes – a que
ele pertence, mas também através das posições que ele tem dentro dessas redes. A
análise estrutural das redes complexas baseia-se na interação como primado
fundamental do estabelecimento das relações entre os agentes humanos, que originarão
as redes complexas.
A partir de Euler, destacaram-se Rényi e Erdös, matemáticos, que foram responsáveis
pelo modelo de grafos randômicos, que pretendia explicar como se formariam as redes
complexas. Nesse modelo de Rényi e Erdös, os nós se conectariam aleatoriamente (por
isso a formação dos grafos seria randômica) e as redes seriam igualitárias, pois todos os
nós que as formavam deveriam ter mais ou menos a mesma quantidade de conexões, e a
mesma chance de receber novas conexões.
MILGRAM (1969) realizou experimento para observar o grau de separação entre as
pessoas: cartas enviadas aleatoriamente a vários indivíduos, solicitando que eles a
enviassem a um alvo específico que, caso não conhecessem, deveria ser acionado
através de outra pessoa. Após a chegada das cartas, concluiu-se que as pessoas estariam
a poucos graus de separação umas das outras. Por isso, a denominação de Mundo
Pequeno. Esse modelo pode ser especialmente aplicado às redes sociais: cada indivíduo
tem amigos e conhecidos em todo o mundo, que por sua vez, conhecem outras pessoas.
Sendo assim, as pessoas estariam conectadas por poucos graus de separação.
GRANOVETTER (1973) apresentou os conceitos de laços fracos e de laços fortes.
Segundo o autor, os laços fracos são mais importantes que os laços fortes na
manutenção da rede, pois conectariam grupos diversos, dando aos grupos características
de rede. As redes complexas apresentam padrões altamente conectados, tendendo a
formar pequenas quantidades de conexões entre cada indivíduo. Modelo semelhante ao
de ERDOS e RÉNYI (1960): laços estabelecidos entre pessoas próximas, além dos
laços estabelecidos aleatoriamente entre alguns nós transformariam a rede num mundo.
Assim sendo, a distância média entre duas pessoas no mundo não ultrapassaria um
número pequeno de pessoas, bastando que existissem entre os grupos alguns laços
aleatórios.
19
Modelo das Redes sem Escalas foi proposto por BARABÁSI (2002), que faz críticas
aos modelos de Erdös e Rényi. O autor discorda da concepção de que, nas redes
complexas, as conexões entre os vértices são estabelecidas de modo aleatório. Segundo
Barabási, há uma ordem na dinâmica de estruturação das redes, sendo alguns nós
altamente conectados, diferentemente dos demais, com poucas conexões. Os nós ricos,
denominados hubs ou conectores tendem a receber sempre mais conexões.
Inúmeras pesquisas sobre redes complexas têm sido desenvolvidas, como os de NOOY
et. al. (2005).
2.6 A Epidemia pelo Vírus HIV
A disseminação do vírus da aids começou há cerca de 100 anos, no antigo Congo Belga,
hoje República Democrática do Congo, na África, conforme relatado na revista Nature
(setembro, 2008), em artigo assinado por pesquisadores da Universidade do Arizona,
nos Estados Unidos. Eles conseguiram determinar quando e de onde partiu o vírus por
meio da comparação genética das duas amostras mais antigas de HIV existentes, dos
anos de 1959 e 1960. A pesquisa concluiu que as amostras se originaram em um
mesmo hospedeiro humano, que teria vivido entre 1884 e 1924. A teoria mais aceita é
a de que o vírus HIV surgiu a partir do vírus SIV, encontrado no sistema imunológico
de chimpanzés e macacos-verdes. O SIV é um vírus altamente mutante que não faz mal
nenhum a esses animais. Entretanto, ao entrar em contato com o organismo humano,
ele sofreu uma mutação e se transformou no HIV.
O mais provável é que essa
contaminação tenha ocorrida através do hábito comum na África, de comer macacos. A
partir do Congo, o vírus atingiu os Estados Unidos por meio de um único infectado, em
1969. Há relatos médicos a partir desse período sobre o aparecimento inexplicável de
doenças como o sarcoma de Karposi, um tipo raro de câncer de pele, e pneumonia,
principalmente entre homossexuais. Em 1981, a aids adquiriu contornos de epidemia e
foi identificada formalmente como doença.
Dois anos depois, o HIV foi isolado.
Calcula-se que existam mais de quarenta milhões de pessoas contaminadas no mundo.
20
2.6.1 A Epidemia pelo Vírus HIV: Revisão Bibliográfica
Inúmeras pesquisas sobre a epidemia da aids foram realizadas, conforme bibliografia
pesquisada.
Entretanto, as pesquisas abordam a análise estatística, como as de
SCWARCWALD et. al. (2000), que analisou a disseminação da epidemia no Brasil,
no período de 1987 a 1996. MATTOS (1999) apresenta uma abordagem sobre as
políticas públicas sobre a aids no Brasil. A pesquisa de MANN e TARANTOLA
(1996) apresenta a análise da aids no mundo.
Não foi encontrada na bibliografia
pesquisada, estudo que utilize a descoberta de conhecimento em bases de dados sobre a
epidemia pelo vírus HIV, assim como sobre qualquer vírus.
2.7 Resumo
O capítulo apresentou brevemente os principais conceitos que são usados na pesquisa.
Entretanto, não faz parte do escopo, abordar complemente os conhecimentos sobre as
distintas áreas que dão suporte à pesquisa. Nesse caso, as referências apresentadas são
suficientes para introduzir o conhecimento sobre os assuntos.
A pesquisa se propõe a realizar a Descoberta de Conhecimento em Bases de Dados
(KDD) em um banco de dados de saúde, mais especificamente sobre a epidemia pelo
vírus HIV no município do Rio de Janeiro. Para atingir esse objetivo, propõe-se realizar
a descoberta de conhecimento em bases de dados através da mineração de dados
geográficos e redes complexas.
Diferentes termos têm sido utilizados nessas áreas de pesquisa. O termo
Geocomputação descreve o uso de técnicas computacionais no auxílio à solução de
problemas em geografia (GAHEGAN, 1999) e como técnicas para revelar padrões
escondidos em grandes bases de dados geográficas. Inclui ainda a análise estatística
espacial, visualização de dados geoespaciais, modelos dinâmicos de interação espacial,
entre outros. Por outro lado, diferentes propostas de Descoberta de Conhecimento em
Base de Dados (KDD) espaço-temporal têm sido apresentadas contemplando desde a
visualização geográfica dos dados até algoritmos completos, conforme bibliografia
apresentada por RODDICK e SPILLIOPOULOU (1999).
21
CAPÍTULO 3
PROPOSTA DE METODOLOGIA PARA DEFINIÇÃO DE PRIORIDADES
3.1 Introdução
Este capítulo apresenta uma proposta de metodologia para definição de prioridades e
objetivos da descoberta de conhecimento em bases de dados. Essa metodologia se
propõe a integrar a abordagem tradicional a uma abordagem estratégica. A metodologia
não se propõe a substituir a proposta de FAYYAD et. al. (1996), mas a complementá-la.
O capítulo divide-se nos seguintes tópicos: 2. Objetivo; 3. Conceito; 4. Sistemas,
Software e Dados; 5. Metodologia; e 6. Resumo.
3.2 Objetivo
Tem-se como objetivo apresentar uma metodologia para definição de prioridades da
descoberta de conhecimento em bases de dados. A metodologia é uma ferramenta
desenvolvida com o objetivo de: (i) ajudar a classificar e apresentar a numerosa
quantidade de informações necessárias para o processo de definição de prioridades; (ii)
identificar as lacunas do conhecimento sobre o assunto pesquisado por intermédio do
processo KDD; e (iii) estabelecer, com a participação dos principais atores, as
prioridades da pesquisa.
3.3 Conceitos
3.3.1 Sistema
Um sistema pode ser definido como um agrupamento coerente de componentes que
operam como um todo e que apresentam uma individualidade, ou seja, distinguem-se de
outras entidades por fronteiras reconhecíveis. Há muitas variedades de sistemas, as
quais podem ser classificadas em três grandes grupos, conforme a interação de seus
componentes. No primeiro, as interações dos componentes são fixas, como em uma
máquina. No segundo, as interações dos componentes são irrestritas, como o gás. E
finalmente, no terceiro, as interações são fixas e variáveis como ocorre em uma célula.
22
Os sistemas com interações fixas e variáveis dependem da natureza e da forma das
interações de seus componentes ao longo de sua existência. Assim, o sistema
apresentará um novo comportamento sempre que componentes forem adicionados,
removidos ou rearranjados, ou então, sempre que houver modificação nas interações.
3.3.2 Sistemas Complexos
Os conceitos de holismo e reducionismo auxiliam o entendimento de sistemas
complexos. O holismo foi proposto por Aristóteles. A frase que o sintetiza é: “O todo é
maior que a soma das partes”. Dessa forma, as propriedades de um sistema complexo
não podem ser determinadas pelo simples conhecimento da propriedade de seus
componentes. O holismo sustenta a teoria da complexidade.
O reducionismo pode ser visto como a visão oposta do holismo. Segundo o
reducionismo, um sistema complexo pode ser explicado pelo processo de redução às
suas partes constituintes fundamentais. Um exemplo é uma figura arbitrária em um
arquivo Metafile poder ser descrita pelos objetos geométricos que a compõem.
Holismo e reducionismo podem assim ser vistos como conceitos complementares e,
portanto, ambos se mostram úteis na formalização do conhecimento sobre sistemas
complexos. A teoria da complexidade procura explicar como as interações das partes
conduzem a um comportamento global emergente. Esse comportamento pode ser
sinergético, no sentido de que o trabalho ou o esforço coordenado de vários subsistemas
é empregado na realização de uma tarefa complexa. Considerando-se a hipótese de
existência de múltiplos componentes que estabeleçam interações variadas, o efeito das
interações impede que o conhecimento dos componentes leve ao conhecimento do
sistema como um todo. Colônia de formigas, sistema econômico, clima e sistema
nervoso são exemplos de sistemas complexos.
23
3.3.3 Redes Complexas
Estas são grafos que apresentam algumas propriedades específicas, como o atendimento
à Lei de Potência, que ocorre quando existem poucos nós na rede muito conectados, e
muitos nós pouco conectados. Outra propriedade é conhecida como a Teoria do Mundo
Pequeno: o comprimento médio do caminho entre quaisquer dois vértices da rede tende
a ser pequeno, ainda que o número de vértices seja muito grande e que a densidade de
conexões entre os vértices da rede seja pequena. Redes sociais, metabólicas, gênicas,
tróficas e a rede mundial de computadores são exemplos de redes complexas.
3.4 Sistemas, Software e Dados
A pesquisa utilizou os dados do Sistema Nacional de Agravos de Notificação (SINAN)
do Ministério da Saúde, disponibilizados pela Secretaria Municipal de Saúde DSTAIDS. Foram considerados todos os casos notificados com 13 anos de idade e superior,
com ano de diagnóstico no período de 1982 a 2005. Visando reduzir o erro introduzido
nas tendências temporais pelo atraso na notificação, os anos de 2006 e 2007 não foram
considerados.
Também foram utilizados os dados de autorizações de internações
hospitalares (AIH) do Sistema de Informações Hospitalares (SIH), disponibilizados pelo
Ministério da Saúde para validar os dados e comparar o total de notificações registradas
no SINAN e de internações para tratamento de aids, do SIH.
Para o cálculo das taxas de incidência, os denominadores foram estimados a partir de
interpolações geométricas das populações dos Censos Demográficos de 1980 (IBGE,
1983), 1991 (IBGE, 1993), bem como da Contagem da População de 1996 (IBGE,
1997). Para o acompanhamento da evolução temporal da epidemia, foram estimadas
taxas médias de incidência para os períodos de 1983-85, 1986-88, 1989-92, agrupandose dessa forma, até o ano de 2005. Posteriormente, após análise das fases de evolução
da epidemia, os períodos foram modificados para 1983-1985, 1986-1988 e assim
sucessivamente. Os períodos foram adequados ao tópico estudado, conforme
apresentado no capítulo específico.
24
Foram notificados e registrados no SINAN da Secretaria do Estado de Saúde do Rio de
Janeiro, 52.431 casos confirmados de aids residentes no estado do Rio de Janeiro,
diagnosticados desde o início da epidemia, em 1982, até dezembro de 2005. A maior
parte dos casos, considerando-se o estado, é de residentes nas regiões Metropolitana 1
(que inclui o município do Rio de Janeiro) e Metropolitana 2, que corresponde a 87% do
total. Entretanto, esta proporção vem se reduzindo ao longo do período, passando de
91.4% na primeira década da epidemia para 76% em 2005, em contrapartida ao
aumento da participação das outras regiões do estado. Do total de estado, foram
notificados 28.918 casos confirmados de aids, acima de 13 anos de idade, no município
do Rio de Janeiro no mesmo período, compondo a base de dados da pesquisa.
Observou-se que a taxa de incidência no município, calculada para 100.000 habitantes,
vem decrescendo desde 1998, quando chegou a 45.4, atingindo o valor de 26.2 em 2003
e 17.3 em 2005. Por outro lado, outras regiões apresentaram aumento em suas taxas,
como a região da Baía da Ilha Grande que, desde 2003, apresenta as maiores taxas do
estado (32.5 casos por 100.000 habitantes em 2003) e a região Fluminense, com taxas
crescentes de 2003 a 2005.
Com relação à distribuição espacial, os bairros com maior percentual, considerando-se o
total de notificações foram Copacabana, Centro, Tijuca, Bangu e Botafogo, nesta
ordem. Entretanto, considerando-se a população média do bairro, as maiores taxas de
contaminação ocorreram, em ordem decrescente, nos bairros de Cidade Nova, Centro,
Santo Cristo, Ramos, Catete e Copacabana.
Em relação ao sexo, os homens ainda são maioria, apesar de os valores se aproximarem
à igualdade nos últimos anos. A razão homem/mulher, desde 2005 é inferior a dois
casos masculinos para cada caso feminino no município (Figura 5.14).
Em relação à mortalidade no município, verifica-se que, para 44% do total de casos
notificados, existe a informação da ocorrência do óbito. A proporção de óbitos é
crescente atingindo 80% para os casos diagnosticados antes de 2000, com decréscimo
progressivo a partir de então.
25
3.5 Metodologia
Na metodologia proposta por FAYYAD et. al. (1996), a descoberta de conhecimento
ocorre em nove etapas.
Na metodologia proposta neste capítulo, todas as etapas
propostas por FAYYAD et. al (1996) são desenvolvidas.
Entretanto,
seu
desenvolvimento é precedido de uma etapa na qual o foco é a definição de prioridades
coadunada com a estratégia da empresa ou do negócio. Consoante com esse objetivo,
essas prioridades são definidas após a análise de riscos e oportunidades, pontos fortes e
pontos fracos, conforme proposto por PORTER (1989).
Nos últimos anos, diversas pesquisas sobre o processo KDD foram desenvolvidas,
conforme apresentadas na revisão bibliográfica. Embora diversas abordagens analisem o
problema com base em diferentes ângulos e com diferentes métodos e metodologias, o
objetivo consensual é identificar padrões novos e úteis em grandes volumes de dados.
Entretanto, não há na literatura pesquisada proposta de um método para definição de
prioridades e objetivos nessa busca por novos padrões. Pelo motivo exposto, o capítulo
apresenta uma metodologia que auxilia a definição de prioridades no processo KDD.
Usualmente, o processo KDD é realizado pelo especialista em inteligência em negócios,
gestão do conhecimento ou áreas similares, ainda que com nomes distintos, que muitas
vezes atua de forma autônoma. Essa proposta auxilia o especialista a coadunar os
interesses do processo KDD com a estratégia da empresa. Dessa forma, a metodologia
proposta não pretende substituir a proposta de FAYYAD et. al. (1996), mas a
complementá-la.
A metodologia é composta por três níveis: conceitual, estrutural e de implantação. No
nível conceitual, as prioridades e os objetivos do processo KDD são definidos. Na fase
estrutural, a infra-estrutura de dados, software e sistemas é definida e, finalmente, a
implantação ocorre na terceira fase.
Na proposta de FAYYAD et. al. (1996), relacionadas a seguir, as duas primeiras etapas
seriam contempladas pelo nível conceitual proposto. As demais tarefas são de
implantação.
26
1.
Desenvolvimento do conhecimento sobre o problema e os objetivos do usuário;
2.
Definição dos dados que serão utilizados no processo de
descoberta de
conhecimento;
3.
Limpeza dos dados e pré-processamento;
4.
Redução e transformação dos dados;
5.
Definição da tarefa de mineração de dados;
6.
Escolha do algoritmo de mineração de dados;
7.
Mineração de dados: regras de associação, regressão, agrupamento de dados, etc.
8.
Avaliação dos resultados;
9.
Consolidação do conhecimento descoberto, incorporação desse conhecimento
nos respectivos processos ou sistemas ou, simplesmente, documentar e transmitir esse
conhecimento aos usuários do sistema.
3.5.1 Nível Conceitual
Dependendo do objetivo definido, as tarefas de mineração de dados serão diferentes. A
definição inadequada do objetivo do processo de descoberta do conhecimento pode
resultar na escolha de método inadequado e de inferências e previsões inúteis. Para
definir as prioridades e os objetivos, definiram-se cinco questões que, uma vez
respondidas pelo especialista, auxiliam a definição de prioridades e objetivos do KDD.
Questão 1: Magnitude.
Questão 2: Fatores de risco, oportunidades, pontos fortes e fracos do processo KDD a
ser realizado.
Questão 3: Conhecimento do assunto.
Questão 4: Custo-efetividade.
Questão 5: Recursos.
O preenchimento das respostas às questões pode ser gradual e, em muitos casos, a
informação pode simplesmente, não existir ou existir parcialmente. Nesse caso, a
utilidade da metodologia é destacar as principais lacunas de informação, cujo
conhecimento é essencial para a tomada de decisão do processo KDD.
27
Na presente pesquisa, as questões foram respondidas de acordo com o tema estudado.
Os exemplos podem ser adaptados para outros temas. Assim sendo, para mensurar a
magnitude do assunto a ser pesquisada pelo processo KDD, os seguintes tópicos foram
utilizados como apoio:
Tamanho e natureza da carga de doença/epidemia e suas tendências
epidemiológicas.
Estratégia atual de controle da doença/epidemia.
Principais problemas e desafios para o controle da doença/epidemia.
Tipo de pesquisa necessário para enfrentar esses problemas e desafios.
Pesquisas em andamento sobre o assunto e oportunidades de pesquisa existentes.
Com origem nesses tópicos, as prioridades assim como as lacunas de informação foram
identificadas. As lacunas são descritas no tópico Ação e foram utilizadas posteriormente
para a definição dos objetivos.
3.5.1.1 Definição de Prioridades e Objetivos
As cinco questões propiciam a definição de prioridades do processo KDD.
3.5.1.1.1 Magnitude
Identificar a magnitude da doença.
Ação: A magnitude pode ser medida pelo número de óbitos ou pelo
DALY, do inglês disability ajusted life year, que é uma medida do total
de anos de vida saudável perdidos em conseqüência de mortalidade,
morbidade ou deficiência prematura. Considerando-se que o banco de
dados utilizado não possui registro do acompanhamento dos pacientes e
de seu estado de saúde durante a epidemia, o número de óbitos foi
utilizado para medir a magnitude. Considerou-se ainda estudo do Global
Forum for Health Research de 1990 (e ratificado em 1996, 1999 e 2000),
que indicou a epidemia pelo HIV como a segunda maior prioridade de
28
pesquisa em doenças e agravos. A primeira prioridade são as doenças
tropicais como malária, esquistossomose e lepra.
Tendência epidemiológica e fatores que podem produzir impacto sobre a carga
da doença/epidemia
Ação: Definir modelo de evolução da epidemia no tempo. Identificar
quais fatores/variáveis relacionam-se com a proliferação da epidemia.
Modelar a evolução da epidemia.
Estratégia de controle e forma de medir o desempenho: por meio de redução das
taxas de morbidade e mortalidade ou redução da transmissão da doença.
Ação: Modelar a evolução de óbitos, após definição de variáveis
relevantes.
Causas da persistência da carga da doença.
Ação: Identificar possíveis causas como pobreza, sexo, dificuldade de
acesso aos serviços de saúde, por intermédio da modelagem espaçotemporal com base em variáveis sociais e de renda.
3.5.1.1.2 Riscos e Oportunidades, Pontos Fortes e Pontos Fracos
A análise de riscos e oportunidade, pontos fortes e pontos fracos (strentghs, weakness,
opportunities and threats – SWOT), proposta por PORTER (1989), foi realizada com o
objetivo de destacar as principais contribuições da pesquisa, identificando-se a maior
possibilidade de sucesso.
Riscos/Limitações da pesquisa e da doença.
Ação: Identificar as limitações da pesquisa. A principal limitação são os
dados. A grande quantidade de dados espúrios pode inviabilizar a
pesquisa. Por outro lado, há a possibilidade/oportunidade de extrair-se
conhecimento útil desses dados. Após pré-análise dos dados, limitou-se o
29
escopo da pesquisa ao município do Rio de Janeiro e à entidade
geográfica bairro, com o objetivo de reduzir esse risco.
Oportunidades para a pesquisa.
Ação: Identificarem-se os aspectos da doença que podem beneficiar-se
com essa pesquisa. O maior benefício da pesquisa é identificar regiões e
atores mais vulneráveis, assim como as prováveis causas dessa
vulnerabilidade. Conseqüentemente, ações preventivas nessas regiões
(locais e público alvo) poderiam evitar novas notificações.
Pontos fortes.
Os pontos fortes são aqueles relacionados à pesquisa. Assim sendo, pontos
fortes como campanhas educacionais sobre o assunto não fazem parte do escopo.
Métodos estocásticos adequados aos dados disponíveis.
Mineração de dados geográficos.
Pesquisa inédita.
Pontos fracos.
Os pontos fracos, assim como os pontos fortes, são aqueles relacionados ao
estudo.
Grande volume de dados espúrios.
Indisponibilidade de dados de relacionamento de pacientes infectados e
respectivo círculo social.
3.5.1.1.3 Conhecimento do assunto
Identificar o estado da arte de pesquisa em curso e lacunas preenchidas pela
pesquisa. As pesquisas em curso utilizam abordagem estatística. Não foi
identificado na literatura pesquisada estudo de mineração de dados geográficos
ou similar sobre a epidemia pelo vírus HIV no município do Rio de Janeiro.
Além disso, não foi encontrada pesquisa que realize a mineração de dados
geográficos com dados sobre epidemia por qualquer vírus ou outro tipo de
doença.
30
Definir o tipo de dado espaço-temporal a ser pesquisado: ambiental,
socioeconômico, discreto ou contínuo.
Definir a entidade espacial do banco de dados geográfico: setor
censitário ou bairro.
Definir o período a ser considerado: 1982 a 2007 e, após análise dos
dados, 1982 a 2005.
Definir a unidade de tempo a ser considerada na análise de séries
temporais: mês.
Definir o resultado esperado do processo conforme os objetivos definidos e
relacionar com tarefas de mineração de dados (descoberta de padrões, geração
de hipóteses, predição, entre outras).
Identificar a influência do espaço geográfico na proliferação da
epidemia.
Identificar as regiões mais vulneráveis e as possíveis causas dessa
vulnerabilidade ao vírus.
Modelar a evolução da epidemia com fechamento óbito.
Modelar a evolução da epidemia no espaço e no tempo.
Identificar padrões úteis e novos.
Identificar os usuários interessados no processo de descoberta do conhecimento.
3.5.1.1.4 Custos e recursos
Neste tópico uma estimativa de custos e recursos necessários é elaborada. Essa
relação pode indicar a inviabilidade do processo KDD. A definição do
cronograma ocorre nessa fase. Em seguida, na fase estrutural, o ambiente de
desenvolvimento da pesquisa é efetivamente definido com origem nesse
levantamento.
Neste nível, os objetivos são definidos.
31
3.5.2 Nível Estrutural
Neste nível as entidades dos modelos formais são mapeadas para estruturas de dados e
algoritmos necessários para os objetivos definidos.
Realizar a pré-análise de dados e a limpeza de dados.
Definir a infra-estrutura de dados: a Figura 3.1 apresenta a infra-estrutura de
dados utilizada. Esta é composta basicamente por: (1) coleção de mapas; (2)
índice de influência espacial; (3) tarefa de mineração de dados; (4) medida de
desempenho da tarefa de mineração de dados geográficos.
Atributos
nãoespaciais
Mapas de
atributos
Geo
DB
Índice de
influência
espacial
Tarefas de
mineração
Medida de
desempenho
Visualização
geográfica dos
padrões descobertos
Figura 3.1 Infra-estrutura de dados.
Além da limpeza e da pré-análise de dados, as seguintes tarefas foram executadas:
Realizar análise estatística dos dados.
32
Definir o método de definição de variáveis relevantes: por intermédio do método
do critério da relevância, conforme proposto por SEIXAS et. al. (1995).
Definir banco de dados geográfico para armazenar dados:
Após testes com Mapinfo e ArcView, citando apenas alguns, optou-se por
utilizar o software Spring. Além da capacidade de processamento e de
atendimento aos requisitos de software definidos, o Spring (CÂMARA, 1996) é
software livre, desenvolvido pelo INPE.
Desenvolver o algoritmo para implantar medida de influência espacial.
Definir a estrutura de dados do banco para armazenar as informações de direção
e distância entre polígonos.
Definir a forma de interação do banco de dados geográfico e software Statistica
e Pajek: A interface não é automática. Os dados são exportados no formato
adequado a ser utilizado pelo software Statistica ou Pajek.
Definir software para tarefas de mineração de dados. Realizaram-se diversos
testes com Statistica, SOM-PAK, entre outros softwares apropriados às tarefas
de mineração de dados. Optou-se por realizar as tarefas de mineração de dados
por intermédio da definição de RNAs selecionando-se o software Statistica.
Utilizou-se o software Matlab para desenvolvimento de programas para
formatação de dados, cálculo da tendência espacial e implantação de uma RNA
do tipo SOM.
Para análise de redes complexas, optou-se por utilizar o software livre Pajek.
Definir medidas de desempenho da mineração de dados.
Definir forma de apresentação e armazenamento dos resultados.
33
3.5.3 Nível de Implantação
O terceiro nível de implantação completa o processo, realizando-se nessa fase as tarefas
de mineração de dados conforme planejado.
3.5.4 Nível Ontológico
Uma sugestão para pesquisa futura é a definição de um nível ontológico, no qual nossas
percepções sejam materializadas em conceitos que descrevam a realidade e definam os
tipos de entidades necessárias para descrever o objeto em estudo. Nesse nível, as
ontologias necessárias para tarefas de mineração de dados geográficos seriam definidas.
Nesse caso, esta seria a primeira fase.
3.6 Método para Definição de Variáveis Relevantes
A identificação das variáveis mais relevantes a serem utilizadas em tarefas de mineração
de dados como agrupamento de dados e classificação é importante para o desempenho
destas tarefas.
A compactação dos dados, utilizando-se somente as variáveis
relevantes, reduz o ruído e a informação desnecessária que, prejudicam a identificação
de padrões e tarefas de mineração de dados em geral.
Diferentes métodos têm sido desenvolvidos para identificar a dimensão dos dados como
análise discriminante, componentes principais, entre outras. Diversos testes foram
realizados com este objetivo utilizando-se o software Weka, entre outros.
Optou-se por utilizar o critério de relevância proposto por SEIXAS et. al. (1995). O
critério consiste basicamente em medir a relevância de cada variável para discriminar o
sistema em estudo. A relevância do componente j é definida por:
2
N
Rx
i 1
xi
N
j
34
xi '
Onde:
xi é o valor do neurônio de saída, após o treinamento da RNA, para cada padrão
apresentado à RNA.
xi ’ é o valor do neurônio de saída, quando o atributo j , apresentado à RNA, é
substituído pelo seu valor médio, calculado para todos os padrões usados no
treinamento da RNA.
N é total de padrões existentes.
No objeto estudado, a saída é a taxa de contaminação de aids no setor censitário e no
bairro (os dois forma considerados em execuções distintas). O segundo termo ( xi ’) é o
mesmo vetor de saída quando o componente j é substituído pela sua média, calculada
considerando-se todo o conjunto utilizado no treinamento da RNA. O resultado é um
mapa de medida de relevância de variáveis, que mede o quanto a resposta da RNA
mudou
quando
um
atributo
foi
substituído
pelo
respectivo
valor
médio.
Conseqüentemente, as variáveis mais importantes apresentam valores de relevância
maiores. Entretanto, esse método pode não ser eficaz para pequenos conjuntos de dados.
Para utilizar o critério, entretanto, foi necessário limpar os dados. Os passos realizados
estão sucintamente descritos:
Normalizar variáveis estatisticamente, ou seja, por desvio padrão.
Identificar coeficiente de correlação de atributos econômico-sociais com
a taxa de aids em cada período.
Identificar as variáveis com correlação significante, ou seja, com módulo
superior a divisão de dois pela raiz do total de padrões (dados) existentes.
Descorrelacionar as variáveis em relação à variável com maior
correlação.
Repetir o cálculo do coeficiente de correlação das variáveis com a taxa
de aids.
Identificar as variáveis mais relevantes por intermédio dos maiores
valores de coeficiente de correlação.
35
3.7 Resumo
A metodologia proposta oferece uma forma prática para compilar informações
relevantes para o processo de priorização do processo KDD. Uma das contribuições da
metodologia é indicar as lacunas de conhecimento existente. O processo de definição
de prioridades é interativo e dinâmico, como o próprio processo KDD e pode ser revisto
durante o processo.
A metodologia não produz prioridades e objetivos, mas possibilita
organizar e apresentar as evidências para definir as prioridades e os objetivos do
processo de descoberta de conhecimento em bases de dados.
36
CAPÍTULO 4
PROPOSTA DE ÍNDICE DE INFLUÊNCIA ESPACIAL
4.1 Introdução
Quando as relações espaciais são medidas, espera-se que as regiões próximas sejam
mais parecidas entre si que as regiões mais distantes (ANSELIN, 2005).
Tal
propriedade é traduzida pela lei conhecida como a Primeira Lei da Geografia de Tobler
(1979):
“Todos os objetos são correlacionados, entretanto, objetos mais próximos são
mais correlacionados que objetos mais distantes”.
A mineração de dados espaciais considera igualmente importante esse conceito.
Algoritmos de mineração de dados espaciais devem considerar a vizinhança dos objetos,
a fim de extrair conhecimento útil.
A mineração de dados espaciais, assim como a análise de dados espaciais, considera a
análise de dados associados a áreas. Essas áreas podem ser irregulares como áreas de
setores censitários ou regulares, como em imagens de sensores. O principal objetivo é
encontrar padrões espaciais até então desconhecidos e potencialmente úteis.
O capítulo está apresentado nos seguintes tópicos: 2. Objetivo, 3. Sistemas, Software e
Dados, 4. Conceitos, 5. Índice de influência espacial e 6. Resumo.
4.2 Objetivo
O presente capítulo apresenta uma proposta de medida de dependência espacial,
denominada índice de influência espacial.
37
4.3 Sistemas, Software e Dados
Utilizou-se o software Spring para definição do banco de dados geográficos.
Os
programas e macros para cálculo de tendência espacial e do índice de influência
espacial foram desenvolvidos no Matlab e Spring, conforme apresentado no Anexo I.
Os dados são originais do Sistema de Informação de Agravos de Notificação (SINAN) e
o Sistema de Informações de Internações Hospitalares (SIH) do Ministério da Saúde e
os censos de demográficos de 1991 e 2000 do IBGE. Os dados foram disponibilizados
pela Secretaria Municipal de Saúde, com todos os casos de notificações de AIDS no
município do Rio de Janeiro, de 1982 a 2005.
4.4 Conceitos
4.4.1 Matriz de Proximidade
No presente trabalho, utilizou-se a matriz de proximidade, amplamente utilizada na
estatística espacial, para medir a relação espacial entre áreas. Na matriz de proximidade
espacial W, cada elemento, wij, representa uma medida de proximidade entre as áreas Ai
e Aj. Os critérios para o cálculo dos valores wij podem basear-se na distância entre os
centróides de duas áreas ou no compartilhamento de fronteiras entre Ai e Aj, ou numa
combinação destes. O critério de fronteira considera wij igual a 1, caso, Aj compartilhe
fronteira com Ai, ou 0 caso contrário. Assim sendo, dado um conjunto de n áreas { Ai,
A2,..., An } , wij =1, se Ai compartilha um lado comum com Aj. Caso contrário, wij = 0,
conforme apresentado na Figura 4.1. (DRUCK et al., 2004).
w14 = 1 P1 faz fronteira com P4
w24 = 0 P2 não faz fronteira com P4
Figura 4.1. Medida de proximidade baseada no compartilhamento do lado do polígono.
38
Existem diversos critérios de proximidade, como a distância inferior a um limite
definido ou a proporção mínima do lado comum em relação ao perímetro total do
polígono. Na presente pesquisa utilizaram-se medidas de proximidade de diferentes
ordens, por faixas de distância, representadas por W1,... Wn, onde W1 indica a
proximidade espacial de primeira ordem (dentro de uma faixa de distância
determinada), W2 indica a proximidade espacial de segunda ordem e assim
sucessivamente.
Uma vez definido o critério de proximidade espacial pode-se determinar a dependência
espacial do conjunto de dados. Uma forma simples de medir a variação da tendência
espacial dos dados é calcular a média dos valores dos vizinhos. Esse cálculo produz
uma primeira aproximação da variabilidade espacial. Apesar de apresentar padrões e
tendências espaciais, a média espacial móvel não mede a dependência espacial, ou seja,
não avalia a variação dos atributos quanto à disposição espacial das áreas ou como os
valores estão correlacionados no espaço. Para avaliar essa correlação, o conceito mais
utilizado é o de autocorrelação espacial, que mede quanto o valor observado de uma
região é dependente dos valores desse mesmo atributo nas localizações vizinhas.
Existem inúmeras técnicas utilizadas para medir a dependência espacial, cada qual com
seus pontos fortes e fracos. As duas medidas mais conhecidas são o índice global de
Moran (I) e o índice de Geary’s (C).
4.4.2 Índice Global de Autocorrelação Espacial
Considerando-se uma determinada matriz de proximidade W, o índice global de
Moran(I) é expresso pela Equação 4.1, onde n é o número de regiões; yi é o valor do
atributo considerado na região i; y é o valor médio do atributo nas regiões
consideradas; wij são os elementos da matriz de proximidade espacial.
39
n
n
n
I
wij yi
i 1 j 1
n
yi
y
y (yj
2
y)
wij
i 1
i j
Equação 4.1. Índice Global de Moran.
A equação de I pode ser simplificada [N(
=0e
2
= 1] e alterarmos W, de forma que
a soma dos elementos de cada linha da matriz de proximidade espacial seja igual a 1,
conforme equação 4.1a.
n
n
wij yi
I
y (yj
y)
i 1 j 1
n
( yi
y)2
i 1
Equação 4.1a. Índice Global de Moran.
O índice de Moran(I) é uma medida de autocorrelação espacial usada para detectar
afastamentos de uma distribuição espacial aleatória. Os desvios com relação à média de
cada atributo são multiplicados pelos desvios da vizinhança, obtidos pela matriz de
proximidade espacial que representa a dependência espacial das áreas envolvidas. O
índice testa se as áreas conectadas apresentam maior semelhança quanto ao indicador
estudado do que o esperado num padrão aleatório. A hipótese nula é a de completa
aleatoriedade espacial. Como um coeficiente de correlação, os valores usualmente
variam de -1 a +1, quantificando o grau de correlação espacial existente. Valores
positivos indicam uma correlação direta e valores negativos, uma correlação inversa.
Valores pequenos indicam regiões pouco correlacionadas e valores altos, indicam
regiões muito correlacionadas.
Os benefícios de modelar a autocorrelação espacial são inúmeros.
Uma maneira
simples de demonstrar esse beneficio é por meio da equação de regressão. Supondo-se
que as variáveis dependentes Yi sejam auto correlacionadas, isto é, Yi = f ( Yj ), para
todo i diferente de j, a equação de regressão deveria ser modificada para:
40
Y=aWy+bX+e
onde W é a matriz de proximidade.
Com a introdução do termo da matriz de proximidade W, o erro residual será menos
influenciado pela autocorrelação espacial, reduzindo, conseqüentemente a diferença
entre os valores reais e os valores previstos.
4.5 Proposta de Índice de Influência Espacial
Os indicadores globais de autocorrelação espacial, como Moran(I), fornecem um único
valor, como medida de associação espacial para todo o conjunto de dados,
caracterizando toda a região de estudo.
Entretanto, usualmente, a análise da
autocorrelação espacial delimitada por determinadas regiões possibilita melhor
entendimento do fenômeno. Por esse motivo, os indicadores locais de associação
espacial são utilizados, definindo um valor específico para cada objeto, permitindo uma
decomposição do índice global de associação espacial.
O índice proposto foi desenvolvido com base no índice de Moran(I).
Entretanto,
introduziu duas características de relacionamento espacial: direção e distância. O índice
mede a modificação regular de um atributo não espacial à medida que se afasta de uma
área e em determinação direção.
Para cumprir esse objetivo, considera a relação de
vizinhança espacial, expressa por faixas de distância e direção, e a análise dos valores
dos atributos não espaciais de uma vizinhança para identificar uma influência espacial.
Dessa forma, a influência espacial é valorada por meio de uma métrica que leva em
consideração as relações de vizinhança no espaço de atributos e no espaço físico.
As características de direção e distância podem ainda ser combinadas por operadores
lógicos para expressar um relacionamento de vizinhança mais complexo e,
conseqüentemente, obter resultados mais específicos nas tarefas de mineração de dados
espaciais.
41
A relação espacial de distância é intuitiva. Considerou-se um critério previamente
definido de distância mínima e/ou máxima.
classificada em uma faixa de distância.
A distância entre os polígonos foi
Assim sendo, a classificação em uma
determinada faixa, considera a distância entre os centróides. As faixas de distância são
mil metros, seguida por seis, dez, vinte e trinta mil metros.
Por outro lado, a relação espacial de direção não é tão simples. Para definir a relação
espacial de direção de um objeto O2 em relação a um objeto O1, considerou-se o um
ponto representativo do objeto O1. Considerou-se o centróide do polígono, como a
origem de um sistema virtual de coordenadas, cujos quadrantes e planos definem as
direções. Para definir a direção de O2, mais da metade dos pontos de O2 deve estar na
respectiva área do plano. Não existe uma única direção entre dois objetos e por isso,
considerou-se a mais exata. Entre a direção sul ou sudeste, optou-se pela sudeste, por
exemplo. A identificação da direção e o cálculo da distância de cada objeto (polígono)
em relação a todos os demais da região pesquisada foram armazenados no banco de
dados, no início da pesquisa. Esses valores são estáticos e raramente são modificados,
como em casos de criação de um novo bairro.
O1
O2
Figura 4.2 Eixo de coordenadas com origem no centróide de O1 usado no cálculo da
direção de O2 em relação a O1.
4.5.1 Cálculo do Índice de Influência Espacial
O índice de influência espacial proposto, identificado por IFd, é uma medida de
associação espacial calculada por objeto. O cálculo do IFd pode ser realizado em
relação a qualquer atributo não espacial, desde que o atributo seja numérico. No cálculo
42
do IFd, considera-se vizinho de um dado objeto O, todo polígono que dista até trinta mil
metros do centróide de O na direção padrão específica. As direções são padronizadas
em zero, quarenta e cinco, noventa, cento e trinta e cinco, cento e oitenta, duzentos e
vinte e cinto, duzentos e setenta e trezentos e quinze graus, sendo os respectivos índices
identificados por IF0, IF45, IF90 até IF315.
Uma variação do índice descrito acima é o índice de influência espacial local,
identificado por IF; que considera em seu cálculo, todos os objetos que distam até dez
mil metros de um dado objeto O, em todas as direções válidas. O índice de influência
espacial local mede a associação espacial entre uma observação e sua vizinhança em
todas as direções. Na Figura 4.4, os polígonos interceptados pela linha imaginária
fechada, são considerados no cálculo do IF de O1.
n
yi
IF
y
Wij y j
y
j 1
n
(yj
y)2
j 1
Equação 4.2 Equação do Índice de Influência Espacial Local
Onde:
yi é o valor do atributo considerado no polígono i;
yj é o valor do atributo considerado no polígono j;
y é o valor médio do atributo;
wij são os polígonos vizinhos ao polígono yi, sendo wij igual a 1, para todo polígono yj
cuja distância ao centróide de Oi seja inferior a dez mil metros, em todas as direções
válidas.
Na Figura 4.3, cada tonalidade da cor cinza, representa o conjunto dos polígonos
considerados no cálculo do IFd, nas respectivas direções, em relação ao objeto O144
(cor verde). O IFd foi calculado considerando-se o atributo taxa de contaminação de
aids do bairro, no ano de 1997. A reta da Figura 4.3 indica os polígonos na direção
noventa graus a partir de um eixo de coordenadas imaginário com coordenadas x e y
(0,0) no centróide de O144, e com distância máxima igual a trinta mil metros, que foram
43
considerados no cálculo do IF90 do objeto O144 (representado pela cor verde). O valor
do IF90 indicou que os polígonos vizinhos ao objeto O144 na direção 90º,
provavelmente influenciaram a sua taxa de contaminação. Confirmou-se, pelo mapa
temático de notificações de aids (Figura 4.4), que essa região apresentou taxas similares
de notificação de aids, em 1997.
O144
Figura 4.3 Índice de influência espacial IF90 de O144, a tonalidade de cinza indica os
polígonos considerados por direção.
Figura 4.4 Mapa temático de taxa de notificações de AIDS por bairro, 1997, município
do Rio de Janeiro.
44
4.5.2 Índice de Influência Espacial Global
O índice de influência espacial global proposto fornece um valor, como medida de
associação espacial, por direção padrão: considera os objetos que interceptam uma
linha imaginária em uma direção padrão e são identificados por IFG0, IFG45, IFG90
até IFG315. Seu uso é mais restrito, tendo como utilidade identificar as direções
relevantes, de um fenômeno estudado, por quadrante. O IFG é calculado pela equação
4.2, com a diferença do critério de vizinhança considerado. Neste caso, os valores de
wij são os elementos da matriz de proximidade espacial, sendo w
ij
igual a 1 para os
objetos oj que interceptam uma linha imaginária na direção padrão específica.
A
direção é definida a partir do eixo de coordenadas com coordenadas (x,y) igual a (0,0)
no centroíde do polígono mais central da região.
Figura 4.5 Linhas imaginárias de direções-padrão a partir do polígono central.
O polígono central no município do Rio de Janeiro é o bairro da Taquara.
4.5.3 Análise de Tendência Espacial
Uma forma de identificar modificações regulares nos atributos não-espaciais é por
intermédio da análise de regressão, onde a variável independente (x) mede a distância
entre o objeto o2 e o1. A variável dependente (y) mede a diferença entre os valores de
um atributo não-espacial para os objetos o2 e o1. Se o valor absoluto do coeficiente de
45
correlação é significativo, há indicação de uma tendência espacial para o atributo
específico a partir do objeto o1.
Utilizou-se a análise de tendência espacial na fase de pré-análise de dados. Considerouse a regressão linear para mapear a relação espacial entre áreas, com base na premissa
que a influência de determinado fenômeno em sua vizinhança é usualmente linear ou
pode ser transformado em um modelo linear, por exemplo, regressão exponencial.
Além disso, a 1ª Lei de Tobler afirma que a similaridade de objetos diminui quando a
distância geográfica entre estes aumenta, caracterizando uma regressão linear.
O cálculo da regressão linear por faixas de distância em direções predefinidas permitiu
identificar correlações entre um atributo e o espaço geográfico, por intermédio da
análise da regressão que satisfaz um coeficiente de correlação mínimo.
O algoritmo de implantação para análise da tendência espacial está apresentando no
Anexo G.
4.5.4 Implantação do Índice de Influência Espacial
Considerando-se que, a direção e distância entre os objetos espaciais, usualmente são
informações estáticas, definiu-se uma estrutura de árvore, para armazenar as
informações de relação espacial conforme apresentada na Tabela 4.1.
Tabela 4.1 Estrutura de árvore com informações de relação espacial por objeto.
Chave_Polígono
Vizinho
Distância
Direção/ângulo
O1
O2
1000.0
0º
...
...
...
...
O1
O3
22500.5
315º
O cálculo do índice de influência espacial baseia-se na definição de vizinhança, definida
através de direção e distância.
46
Considerando-se max-dist e dist números reais e d a direção, definiu-se o conceito de
Vizinhança para um banco de dados geográfico com distância max-dist e direção d
como sendo: V izinhança = { ( o1, o2, dist, d) | o1, o2
DB, o1 dist o2 <= dist-max e o1 d
o2}.
O IF é calculado sobre o conjunto de todos os objetos conectados ao objeto O através da
vizinhança V, que satisfaz ao predicado P. O predicado P é o critério de seleção:
distância e direção. Após a seleção do conjunto de objetos que satisfazem ao predicado
P, calcula-se o valor do índice. O IF mede a associação da vizinhança de O, em relação
ao atributo considerado.
A Tabela 4.2 apresenta um exemplo de seleção de vizinhança
para cálculo do IF do polígono O144. Para o cálculo do IF, considerou-se o predicado
distância de até dez mil metros e todas as direções-padrão.
Tabela 4.2. Seleção de polígonos com a relação espacial de direção e distância.
Chave
Polígono
Vizinho
Faixa
Distância
Distância
Direção/ângulo
O144
O1
10.000
7.123,71
0º
O144
O23
10.000
3.954,16
45º
...
O144
O148
...
10.000
3.104,13
315º
4.5.5 Exemplo de Aplicação do IF
Para demonstrar uma aplicação do IF, objetivou-se realizar a previsão da taxa de
contaminação de um bairro, tendo como informação de entrada a taxa de bairros
vizinhos.
Esse tipo de predição pode ser útil para completar dados faltantes ou
inválidos, como os causados por erro de digitação nos bancos de dados. Nesse caso,
através de rede neural artificial (RNA), as taxas de contaminação de bairros que
usualmente apresentam erro, são definidas.
progressivamente o erro de predição.
47
Com o tempo, a rede diminuiu
Utilizou-se o software Statistica 7.0 para definir duas RNAs do tipo perceptron de
múltiplas camadas, com algoritmo Backpropagation.
Comparou-se o resultado das
duas redes neurais. A primeira RNA, além das taxas de contaminação dos vizinhos,
possui na camada de entrada, a informação do IF local de cada um dos quatro bairros
vizinhos. A segunda RNA não possui a informação do IF, sendo a camada de entrada
formada pelos valores das taxas de contaminação dos vizinhos. Quatro vizinhos por
bairro, ordenados por ordem decrescente de taxa de contaminação foram utilizados na
camada de entrada. Limitou-se a faixa de distância a dez mil metros, em qualquer
direção. A configuracao da primeira RNA foi definida por oito neurônios na camada
de entrada, quinze neurônios na camada intermediária e um neurônio na camada de
saída. A segunda rede com quatro neurônios na camada de entrada, sete neurônios na
camada intermediária e um neurônio na camada de saída.
A camada de saída é
composta pela taxa de contaminação a ser prevista. As Tabelas 4.3a e 4.3b, apresentam
os resultados das RNA com e sem IF, respectivamente.
Conforme esperado, o
desempenho da primeira RNA foi superior. O IF mede a dependência espacial entre os
bairros e o impacto no valor da variável a ser prevista, nesse caso, a taxa de
contaminação.
A rede consegue extrair essa informação durante o treinamento,
obtendo, dessa forma, um melhor desempenho. As Figuras 4.6 e 4.7 apresentam o
resultado dos valores preditos e observados.
Tabela 4.3a Resultados da RNA de predição da taxa de contaminação por bairro com IF
na camada de entrada.
Tx_ano.1
Tx_ano.2
Tx_ano.3
Tx_ano.4
Tx_ano.5
Data Mean
9.391317
9.391317
9.391317
9.391317
9.391317
Data S.D.
6.808094
6.808094
6.808094
6.808094
6.808094
Error Mean
0.018790
0.001765
0.005894
-0.012539
0.004036
Error S.D.
0.185951
0.106722
0.082350
0.081316
0.061593
Abs E. Mean
0.133079
0.065810
0.054958
0.060838
0.039800
S.D. Ratio
0.027313
0.015676
0.012096
0.011944
0.009047
Correlation
0.999633
0.999878
0.999928
0.999929
0.999959
48
Tabela 4.3b Resultados da RNA de predição da taxa de contaminação por bairro sem IF
na camada de entrada.
Tx_ano.6
Tx_ano.7 Tx_ano.8 Tx_ano.9 Tx_ano.10
9.391317 9.391317 9.391317
9.391317 9.391317
6.808094 6.808094 6.808094
6.808094 6.808094
0.357959 0.428495 -0.524329 -0.054062 -0.295187
5.837753 5.810031 5.828004
5.807406 5.767635
5.059816 5.037736 5.182887
5.139639 5.043155
0.857472 0.853400 0.856040
0.853015 0.847173
0.515874 0.521542 0.525920
0.527604 0.531349
Data Mean
Data S.D.
Error Mean
Error S.D.
Abs E. Mean
S.D. Ratio
Correlation
Tx_ano, Observed vs. Tx_ano, Predicted (5 )
28
26
24
22
20
Tx_ano, Predicted
18
16
14
12
10
8
6
4
2
0
-2
-2
0
2
4
6
8
10
12
14
16
18
20
22
24
26
28
Model
5
Tx_ano, Observed
Figura 4.6 Valores observados e preditos pela RNA com IF na camada de entrada.
Tx_ano, Observed vs. Tx_ano, Predicted (10 )
15
14
13
12
11
Tx_ano, Predicted
10
9
8
7
6
5
4
3
2
1
0
-1
-2
0
2
4
6
8
10
12
14
16
18
20
22
24
26
28
Model
10
Tx_ano, Observed
Figura 4.7 Valores observados e preditos pela RNA sem o IF na camada de entrada.
49
4.6 Resumo
A mineração de dados espaciais prescinde da definição de um critério de proximidade.
Esse conceito é fundamental para a valoração de dependência espacial. Dependência
espacial é o impacto que a variação na localização espacial causa na variação dos
atributos, ou seja, é a medida de como os atributos são dependentes do espaço
geográfico.
Inúmeros trabalhos existem na Análise Estatística de Dados Espaciais,
todavia, todos utilizam índices de valoração de dependência espacial que exigem a
aplicação de métodos estatísticos de validação e adequação dos dados aos modelos
estatísticos.
Nesse capítulo apresentou-se a proposta de um Índice de influência espacial, que cria
um conceito de vizinhança por intermédio das características de relacionamento espacial
de distância e direção entre objetos.
A utilização do índice de influência espacial
proposto em tarefas de mineração de dados será apresentada nos capítulos seguintes.
No exemplo apresentado, a inclusão do IF nas tarefas de mineração de dados espaciais
resultou em melhor desempenho, mensurado através da redução dos erros de teste e
verificação em uma rede neural artificial utilizada para predição de um valor. Essa
melhoria é explicada pela inclusão de características da vizinhança, implicitamente
expressas pelo Índice.
Na análise espacial, a relação topológica baseia-se em fronteiras e limites de objetos
espaciais.
A relação topológica entre os objetos espaciais não foi considerada na
presente pesquisa, que utiliza somente polígonos perfeitamente delimitados e disjuntos
(como bairros). Assim sendo, não foram consideradas relações como A contém B, A está
dentro de B, A intercepta B, entre outras. A inclusão da relação topológica seria
especialmente útil em tarefas de mineração espacial que utilizem polígonos que
contenham e interceptem ruas, escolas, rios e hospitais, sendo uma das sugestões de
continuidade deste trabalho.
50
CAPÍTULO 5
APLICAÇÃO DO ÍNDICE EM TAREFAS DE MINERAÇÃO DE DADOS
5.1 Introdução
As redes neurais artificiais (RNA) são caracterizadas pela arquitetura, pelas
características dos neurônios que as compõem e pela regra de treinamento usada para
absorção do conhecimento. Cada neurônio j possui um vetor de dados de entrada, xk =
[€1, €2, €3,..., €n], uma ativação interna J, uma função ativação f (J) e os pesos
sinápticos, wj = [wj1, ....wjd] T, que conectam os elementos de xk ao neurônio j (Figura
5.1). As RNA são formadas pela combinação dessas unidades básicas com os modelos
de ativação e apresentam como vantagens as características de adaptabilidade,
generalização e tolerância a ruídos, entre outras (HAYKIN, 1999). Essas características
são extremamente importantes quando aplicadas à análise de dados espaciais, dada a
natureza complexa desses dados.
Figura 5.1 Modelo de neurônio j, com entrada xk e saída f (J)
Uma das principais funções do Mapa Auto-Organizável é atuar como um mecanismo
não-supervisionado de mapeamento de dados multivariados numa grade de dimensão
menor, resguardando as propriedades dos dados originais. Na bibliografia pesquisada
não há trabalhos que tratem de todas as tarefas de mineração de dados espaciais usando
RNA desse tipo, desde a descoberta de dados atípicos até a análise da distribuição
espacial. Apesar disso, observou-se crescente interesse por uso da rede SOM na
geociência, como em estudos de (GAHEGAN, 2000).
O capítulo está dividido nos seguintes tópicos: 2. Objetivo; 3. Sistemas, Software e
51
Dados; 4. Conceitos; 5. Aplicação do IF no Mapa Auto-Organizável; e 6. Resumo.
5.2 Objetivo
Utilizou-se a rede SOM para realizar o agrupamento de dados em virtude da boa
adaptação desse tipo de rede aos problemas que tratam da análise de dados espaciais.
Essas áreas podem ser áreas regulares, como imagens sensoriais, ou irregulares, como
setores censitários.
5.3 Sistemas, Software e Dados
Para implementação da rede SOM, testou-se o pacote SOM-PAK (2000), que é
implementado na linguagem C para definição e implantação do Mapa AutoOrganizável. Comparou-se também com o software Statistica e, também com o SOM
ToolBox do Matlab. Optou-se por utilizar o Matlab. O Statistica também foi utilizado
para validar os resultados. Foram testadas várias arquiteturas de SOM, que se
distinguiram pelas dimensões do mapa. Todas as configurações foram definidas com
mapa bidimensionais hexagonais. A função utilizada para o cálculo da vizinhança foi a
função gaussiana.
Os sistemas utilizados foram o sistema de informação de notificação de agravos
(SINAN), do sistema de informações de internações hospitalares (SIH), ambos do
Ministério da Saúde. Os dados foram disponibilizados pela Secretaria Municipal de
Saúde, com todos os casos de notificações de aids, de 1982 a 2005, no município do Rio
de Janeiro.
O dicionário de dados está apresentado no Anexo O. Com relação à
análise espacial, foram utilizadas duas abordagens: a primeira, de acordo com a divisão
tradicional do município em bairros. A segunda, de acordo com o resultado do
agrupamento dos bairros de residência dos pacientes notificados.
Considerou-se
sempre o tamanho da população no cálculo de taxas e índices e comparou-se, sempre
que possível, o resultado com a concentração de pobreza do bairro, medida pela
proporção de chefes de família com renda mensal inferior a dois salários mínimos.
52
5.4 Conceitos
5.4.1 Classificação de Redes Neurais Artificiais
Segundo KOHONEN (2001), as RNA podem ser divididas em três categorias: redes de
transferência de sinal, redes de transferência de estado e redes competitivas. Nas redes
de transferência de sinal a saída da rede depende, única e exclusivamente, do valor de
entrada. Essas redes são usadas para transformação de sinais. São exemplos desse tipo
de rede aquelas denominadas redes alimentadas adiante, redes perceptron de múltiplas
camadas – Multi-Layer Perceptron-MLP e as redes de função de base radial – Radial
Basis Function-RBF. (HAYKIN, 1999). Essas redes são usadas como identificadores de
padrões, controle, entre outras funções.
As redes de transferência de estado têm como base os efeitos de relaxação. A
retroalimentação e a não-linearidade são tais que garantem que o estado de atividade
rapidamente convirja para um de seus valores estáveis. Os valores de entrada acionam o
estado inicial de atividade, e a rede então inicia o processamento até chegar ao estado
final. São exemplos desse tipo de rede as redes de Hopfield e a máquina de Boltzmann
(HAYKIN, 1999), sendo utilizadas principalmente em problemas de otimização, como
função de memória associativa.
As redes de aprendizagem competitiva estão baseadas no processo competitivo de
aprendizagem entre suas unidades, sendo o agrupamento de dados uma das principais
aplicações dessas redes. As redes SOM, sigla do inglês, Self Organizing Map
(KOHONEN, 2001), e ART, de Adaptative Ressonance Theory, são exemplos de redes
adaptativas. A aprendizagem competitiva é um processo no qual os neurônios tornam-se
gradualmente sensíveis a diferentes categorias de entrada e a conjuntos de amostras em
uma vizinhança, ou seja, em um domínio específico do espaço de entrada.
5.4.2 Mapas Auto-Organizáveis
O mapa auto-organizável (SOM) é uma RNA com duas camadas (KOHONEN, 2001): a
camada de entrada I e a de saída U. A entrada da rede corresponde a um vetor no espaço
53
d-dimensional em Rd, representado por xk = [ε1, ..., εd] T , k = 1, ..., n, sendo n o número
de vetores de entrada. Cada neurônio j da camada de saída possui um vetor de código w,
também no espaço Rd, associado ao vetor de entrada xk, wj = [wj1, ...,wjd]T . Os
neurônios da camada de saída estão interconectados por uma relação de vizinhança que
descreve a estrutura do mapa. Existem diferentes topologias para a estruturação de um
mapa auto-organizável, sendo a mais comum a de duas dimensões, pela facilidade de
visualização.
O algoritmo de treinamento da rede SOM é composto por três fases. Na primeira fase,
competitiva, os neurônios de saída competem entre si, segundo algum critério para
definir um neurônio vencedor ou BMU, do termo em inglês best match unit. Na segunda
fase, é definida a vizinhança do neurônio vencedor. Finalmente, na fase adaptativa, os
vetores do neurônio e da vizinhança são ajustados.
O algoritmo de aprendizagem pode ser em lote ou seqüencial, considerando-se a forma
de atualização dos vetores de código. No processo em lote, os vetores de código são
atualizados ao final de cada época. Em cada época, o conjunto de dados é dividido
conforme as regiões de Voronoi dos vetores de código do mapa, segundo o critério
definido para medir a proximidade entre o vetor de código e os dados. Por outro lado,
no algoritmo de aprendizagem seqüencial, as apresentações dos padrões devem ocorrer
de forma aleatória para garantir a apresentação de todos os padrões.
A definição do parâmetro de aprendizagem é empírica, baseada no conhecimento do
assunto. Da mesma forma, a definição do tamanho do mapa também é realizada de
forma empírica, com base no conhecimento do especialista (KOHONEN, 2001).
Nos testes realizados nesta pesquisa, comprovou-se que o tamanho da amostra de
treinamento influencia significativamente o processo de decisão sobre o tamanho do
mapa auto-organizável. Para grandes volumes de dados (setores censitários), mapas
razoavelmente grandes foram necessários. Nesse caso, a definição de mapas pequenos
comprometeu a integridade de formação topológica da rede SOM. Por outro lado, a
normalização dos dados não afetou o resultado. Apesar disso, utilizaram-se os dados
normalizados.
54
5.4.3 Avaliação de qualidade do Mapa Auto-Organizável
Com o objetivo de avaliar a qualidade do mapa gerado, optou-se por utilizar o erro de
quantização vetorial (Eq) (KOHONEN, 2001). Esse erro é a média do erro
correspondente à diferença entre o vetor de características xk e o vetor de código WBMU,
ou seja, o vetor de código vencedor no processo competitivo para o padrão xk.
5.4.4 Visualização do Mapa Auto-Organizável
Para visualizar o resultado do processo de aprendizagem, usualmente, os vetores de
código são definidos como coordenadas no espaço n-dimensional, desde que n seja
inferior a três dimensões.
O resultado do processo de aprendizagem da rede SOM é o mapa de vetores de códigos
gerado, representado pelo vetor wij. O mapa resultante é ordenado topologicamente, ou
seja, a localização espacial de um neurônio no mapa auto-organizável resultante
corresponde ao domínio dos padrões de entrada. O mapa também reflete a densidade
dos pontos de entrada, embora a distribuição das unidades do mapa resultante não seja
exatamente a mesma da distribuição dos dados amostrais, conforme demonstrado nas
Figuras 5.2a e 5.2b. Na região interna à eclipse, localizam-se o maior número de pontos
representativos dos casos de aids.
55
Figura 5.2a Imagem fatiada usando estimador de densidade Kernel para o atributo total
de ocorrências de aids por setor censitário, visualização software Spring, 2005,
município do Rio de Janeiro.
Figura 5.2b. Estrutura do mapa auto-organizável de notificações de aids por setor
censitário, após cem épocas de treinamento da rede SOM bidimensional 20 x
40, desenvolvido no Matlab, 2005, município do Rio de Janeiro.
Outra forma de visualização do resultado da rede SOM utiliza a projeção da matriz de
distância entre os vetores de código, denominada matriz de distância unificada ou UMatriz por ULTSCH (1993) e (1999), que permite observar visualmente as relações
topológicas entre os neurônios (KOHONEN, 2001). O critério de distância usado no
56
treinamento, como a distância euclidiana, é também considerado para calcular a
distância entre os vetores de código e os neurônios adjacentes. O resultado gerado
quando essa matriz é aplicada sobre o mapa é uma imagem em que o nível de correlação
de cada pixel corresponde a uma distância.
A partir de um mapa bidimensional, calculam-se as distâncias dx, dy e dz para cada
neurônio conforme demonstra a Figura 5.3. O valor du da U-matriz é calculado em
função dos valores dos elementos circunvizinhos ao respectivo neurônio, podendo ser o
valor da média, a mediana, o valor máximo, entre outros. Valores altos correspondem a
neurônios vizinhos dissimilares e valores baixos correspondem a neurônios vizinhos
similares. A visualização, por intermédio da U-Matriz, para grandes volumes de dados é
inadequada. Existem outras formas, como o plano de componentes.
Entretanto, não
faz parte do escopo desta pesquisa aprofundar este assunto.
Figura 5.3. Cálculo dos valores dx, dy e dz da U-matriz, visualização software
Statistica.
Considerando-se que, para grandes volumes de dados, a U-Matriz não é apropriada,
pode ser necessário utilizar algoritmos de partição de grafos, com o objetivo de
interpretar o resultado do mapa auto-organizável. Outra solução pode ser a utilização
de um algoritmo, como o k-means, citando somente um exemplo, para auxiliar a
interpretação do resultado da rede SOM.
5.4.5 Definição do número de clusters
A validação do agrupamento de dados possui diversos objetivos. Um deles é determinar
a tendência de agrupamento de um conjunto de dados para identificar se uma estrutura
57
não-aleatória de fato existe nos dados. A maioria dos algoritmos de agrupamento
encontra grupos mesmo em dados aleatórios. Outro objetivo é comparar os diversos
algoritmos de agrupamento ou determinar o valor mais apropriado de número de
agrupamentos.
Na bibliografia pesquisada não foi encontrado estudo para a determinação do tamanho
ideal do mapa auto-organizável. Experimentou-se definir o número de neurônios de
saída igual ao número desejado de agrupamentos, com resultado satisfatório, somente
para pequenos volumes de dados. Os testes mostraram, ainda, que os resultados obtidos
pelo SOM são particularmente sensíveis a variações nas dimensões da grade de saída m
x n.
Com o objetivo de definir o número ideal de agrupamentos, utilizou-se o índice
Calinski-Harabasz (1974). Utilizou-se também o índice Davies-Bouldin (1979) para
validar os resultados obtidos com o primeiro índice. Na Figura 5.4a, o índice CalinskiHarabasz foi calculado para os dados originais. A Figura 5.4b é similar e apresenta o
resultado calculado para os vetores de saída do mapa auto-organizável, demonstrando
que o mapeamento de dados multivariados numa grade de dimensão menor resguardou
as propriedades dos dados originais.
Figura 5.4a Índice Calinski-Harabasz Figura
calculado para os dados originais.
5.4b
Índice
Calinski-Harabasz
calculado para os vetores de código resultantes
da rede SOM.
58
Utilizou-se o índice Calinski-Harabasz para definição do número ideal de agrupamentos
em cada teste realizado.
5.5 Aplicação do IF em Tarefas de Mineração de Dados
Inicialmente, a informação de localização espacial de cada bairro [coordenadas
geográficas (ou planas) (x,y)] foi incluída no vetor de características xk., em conjunto
com outros atributos. Em outro experimento, o valor do IF de cada bairro do município,
calculado para um atributo específico, foi incluído no vetor de características xk,,
também em conjunto com outros atributos a serem considerados no agrupamento de
dados. Diversos agrupamentos e análises foram realizados. Neste caso, o experimento
foi executado não somente usando dados de bairros e de setores censitários, porque o
volume de dados do segundo é maior. Com objetivo de testar a influência do IF no
agrupamento usando a rede SOM, comparou-se o valor do erro de quantização vetorial
nas duas configurações.
Entretanto, nos testes realizados, não houve mudança
significativa com a inclusão do IF.
5.6 Resultados dos Agrupamentos de Dados
5.6.1 Taxa de Crescimento da Contaminação
Figura 5.5 Resultado do agrupamento de dados de bairros por taxa de crescimento da
epidemia, visualização software Statistica, 1982 a 2005, município do Rio de
Janeiro.
59
Por meio do agrupamento de dados, segundo a taxa de crescimento de contaminação,
definiram-se três grandes grupos. O agrupamento um (cluster 1) é formado pelos
bairros de Centro, Saúde, Cidade Nova e Copacabana. A Figura 5.6 apresenta as taxas
de contaminação dos principais bairros. Verificou-se um padrão de crescimento
constante em cada bairro, apesar da variação entre os bairros.
Figura 5.6 Taxa de contaminação por bairro, 1982 a 1992, município do Rio de Janeiro.
Em seguida, com o objetivo de identificar a influência dos bairros nas respectivas
vizinhanças, realizou-se o agrupamento de bairros com o valor do IF no vetor de
características. O agrupamento de bairros (cluster 1) apresentou rápido crescimento
desse índice, indicando uma brusca expansão da contaminação 1985 a 1988, conforme
Figura 5.7.
35
30
25
20
15
10
5
0
-5
-10
IF83
IF85
IF87
IF89
IF91
IF93
IF95
IF97
IF99
Cluster 1
Cluster 2
Cluster 3
Figura 5.7 Resultado do agrupamento de bairros com atributo IF, visualização software
Statistica, 1982 a 2005, município do Rio de Janeiro.
60
O agrupamento de bairros permitiu identificar grupos bem distintos em relação a esse
atributo. Os bairros do Centro e da Saúde apresentaram uma expansão brusca seguida de
ma expansão mais branda e permanente na influência da vizinhança (cluster 1). O
cluster 2, formado por Santo Cristo, Cidade Nova, Flamengo, Glória, Catete e
Copacabana apresentou crescimento similar, entretanto, com valores inferiores de IF,
ao longo do período.
Figura 5.8 Valor do IF por bairro, 1982 a 1999, município do Rio de Janeiro.
5.6.2 Indices Econômico-sociais, Taxa de Contaminação e IF
Em seguida, realizou-se o agrupamento de bairros considerando-se as variáveis taxa de
contaminação da epidemia, IF e índices econômico-sociais. A Tabela 5.1 apresenta os
atributos econômico-sociais considerados: (1) percentual de domicílios alugados; (2)
percentual da população com segundo grau; (3) percentual da população com terceiro
grau; (4) percentual de famílias cujo chefe de família possui renda de até dois salários
mínimos; (5) percentual de famílias cujo chefe de família é mulher.
Estes atributos
foram escolhidos conforme estudo realizado sobre a relevância das variáveis com base
em proposta de SEIXAS et. al. (1995).
61
Tabela 5.1 Atributos econômico-sociais de um dos agrupamentos.
Nome
CENTRO
CIDADE NOVA
GLORIA
COPACABANA
Valor Máx Todos Bairros
Bairro Valor Máx
PDOMALUG
3.14
1.77
2.43
1.21
4.20
Saúde
PEST2G
0.78
-0.39
0.08
-0.84
7.79
Cidade Universitária
PEST3G
0.17
-0.12
1.01
1.43
5.80
Cidade Universitária
PREN02
-0.55
0.78
-1.25
-1.51
2.36
Acari
PCHEFMUL
1.45
0.95
2.11
1.91
5.86
Cidade Universitária
O resultado do agrupamento (principais clusters) está apresentado na Figura 5.9.
A
linha preta separa o resultado do agrupamento por IF. A linha dupla é o resultado do
agrupamento de bairros por atributo econômico-social, que considerou no agrupamento
um, os bairros de Santo Cristo, Cidade Nova, Centro e Saúde, no agrupamento dois, os
bairros do Flamengo, Copacabana, Catete e Glória. A linha tracejada apresenta o
resultado do agrupamento por taxa de contaminação, unindo no mesmo agrupamento os
bairros de Santo Cristo, Cidade Nova, Centro e Saúde. O fundo cinza é o resultado do
agrupamento, considerando-se as três variáveis em conjunto, e está representado na
Figura 5.10 pela cor preta. Nesse caso, o principal agrupamento incluiu os bairros
Cidade Nova, Centro, Saúde, Glória e Copacabana.
SANTO CRISTO
CENTRO
CIDADE NOVA
SAUDE
FLAMENGO
CATETE
GLORIA
COPACABANA
Figura 5.9 Agrupamentos de bairros (principais agrupamentos) com vetor de
características composto pelos atributos IF, taxa de contaminação e índices
econômico-sociais, 2005.
62
Figura 5.10 Agrupamento de bairros com vetor de características composto pelos
atributos IF, taxa de contaminação e índices econômico-sociais, visualização
software Spring, 2005.
5.6.3 Categoria de Exposição
As seguintes categorias foram consideradas: homo/bissexuais, heterossexuais, usuários
de drogas injetáveis, transfusão de sangue e ignorada – composta pelo agrupamento das
categorias simples correspondentes acrescidas das múltiplas, conforme o princípio de
hierarquização da Join United Nations Programme on HIV/aids (UNAIDS, 1999),
conforme hierarquia apresentada a seguir:
Hierarquia de modos presumíveis de transmissão.
1)
Perinatal
2)
Usuário de drogas injetáveis (UDI)
3)
Homo/bissexual masculino
4)
Pessoa que recebeu sangue (transfusão de sangue)/hemoderivados e hemofílicos.
5)
Pessoa que se infectou pela transmissão sexual
6)
Outras modalidades
7)
Ignorado
Em caso de múltiplos riscos, os casos serão atribuídos às categorias acima listadas,
seguindo a ordem hierárquica de modos presumíveis de transmissão. (UNAIDS, 1999)
63
A categoria de exposição classifica a forma de contaminação pelo vírus HIV. A Figura
5.11 apresenta a evolução da contaminação para as principais categorias de exposição.
Figura 5.11 Total de casos de aids por categoria de exposição, 1982 a 2005, município
do Rio de Janeiro.
A categoria homossexual apresentou o maior percentual de participação no total de
casos de aids até 1997, quando foi superada pela categoria heterossexual. Os bairros
foram agrupados, considerando-se o percentual por categoria de exposição do bairro e
variáveis relevantes. O resultado está resumido na Tabela 5.2 [os quadros apresentam
somente o(s) principal(ais) cluster(s) com as maiores participações por categoria de
exposição de cada período]:
Tabela 5.2 Resultado do agrupamento de dados por categoria [somente o agrupamento
com os maiores valores], períodos de 1982 até 1985 e 1982 até 1988, município do Rio
de Janeiro.
BAIRRO_85
COPACABANA
BANGU
FLAMENGO
TIJUCA
BOTAFOGO
GAVEA
LEBLON
SANTA TERESA
total
Homo até 85
0.24
0.06
0.12
0.02
0.04
0.06
0.04
0.06
0.64
BAIRRO_88
COPACABANA
BANGU
CENTRO
TIJUCA
BOTAFOGO
FLAMENGO
IPANEMA
VILA ISABEL
LEBLON
CATETE
SANTA TERESA
LARANJEIRAS
GAVEA
total
64
Homo até 88
0.15
0.09
0.06
0.05
0.05
0.05
0.02
0.02
0.02
0.02
0.01
0.02
0.02
0.57
Durante o
período de 1982 até 1988, a categoria de exposição homossexual foi
predominante em todos os bairros com ocorrências de aids. Cinco bairros da zona sul:
Copacabana, Flamengo, Botafogo, Ipanema e Gávea, em conjunto, foram responsáveis
por mais de cinqüenta por cento de todos os casos de contaminação em homossexuais
neste período. As Figuras 5.12a, 5.12b, 5.12c e 5.12d, apresentam as notificações de
aids das categorias homossexuais e heterossexuais de 1982 a 1988. As Figuras 5.12e e
5.12f apresentam o total de ocorrências, considerando-se o período de 1982 a 1999.
Observou-se o crescimento significativo de contaminação em homossexuais, em bairros
no sentido norte, leste e oeste até 1988. O crescimento na população de heterossexuais
também ocorreu neste mesmo sentido, de forma mais branda. A partir de 1988, o
crescimento ocorreu nos bairros da zona norte. Não foi identificada uma divisão de
bairros por categoria de exposição, conforme resultado do agrupamento de dados. As
notificações estão representadas por figuras geométricas em figuras distintas: círculo
(homossexual) e quadrado (heterossexual). Nestas figuras, os bairros com atributo
proporção de chefes de família com renda de até dois salários mínimos, estão
representados em cinza, com o objetivo de facilitar a comparação da proliferação da
epidemia e a renda das famílias. Observou-se que, a expansão da epidemia ocorreu nos
bairros com renda inferior. Os bairros com fundo cinza foram “preenchidos” pelas
figuras geométricas que representam as notificações de aids, ao longo do tempo.
Figura 5.12a Notificações de aids em homossexuais, 1982 a 1985, município do Rio de
Janeiro.
65
Figura 5.12b Notificações de aids em heterossexuais, 1982 a 1985, município do Rio de
Janeiro.
Figura 5.12c Notificações de aids em homossexuais, 1982 a 1988, município do Rio de
Janeiro.
66
Figura 5.12d Notificações de aids em heterossexuais, 1982 a 1988, município do Rio de
Janeiro.
Figura 5.12e Notificações de aids em homossexuais, 1982 a 1999, município do Rio de
Janeiro.
67
Figura 5.12f Notificações de aids em heterossexuais, 1982 a 1999, município do Rio de
Janeiro.
O agrupamento de bairros considerando-se todo o período, de 1982 a 2005 e o atributo
total de notificações de aids acumulado por categoria, além das variáveis relevantes,
separou em um cluster os bairros com maior percentual de ocorrências em todas as
categorias. Os bairros que compõem este agrupamento estão apresentados na Tabela
5.4.
Tabela 5.4 Resultado do agrupamento de bairros por categoria de exposição [somente o
agrupamento com os maiores valores], valor máximo por categoria, 1982 a 2005,
município do Rio de Janeiro.
Bairro
Homosexual
CENTRO
4.49
COPACABANA
9.95
TIJUCA
2.55
Valor Máx Todos Bairros
9.95
Bairro Valor Máx
Copacabana
Bissexual
4.13
9.19
3.61
9.19
Copacabana
Heterossexual
3.91
6.46
4.09
6.46
Copacabana
UDI Transfusão sangue
Ignorado
4.03
2.07
4.43
9.03
5.34
8.66
2.88
4.41
2.77
9.03
5.34
8.66
Copacabana
Copacabana Copacabana
A categoria de pessoas que realizaram transfusão de sangue apresentou redução superior
a cinqüenta por cento dos casos entre 1990 e 1992.
Após investigação sobre as
possíveis causas, constatou-se que, no ano de 1986 ocorreu a identificação de anticorpos HIV, fato que provavelmente explica esta redução.
68
5.6.4 Razão de Sexos
A variável razão de sexos (proporção de homem/mulher) apresentou o segundo maior
coeficiente de correlação com taxa de contaminação da epidemia. A queda da proporção
entre homens e mulheres contaminados indica o crescimento da contaminação de
mulheres (Figura 5.13 e Figura 5.14). O crescimento da contaminação em mulheres é
de 20% ao ano, representando o maior aumento relativo.
Figura 5.13 Percentual de homens e mulheres, 1982 a 2005, município do Rio de
Janeiro.
Figura 5.14 Razão de sexos, 1982 a 2005, município do Rio de Janeiro.
O agrupamento de bairros pela variável razão de sexos demonstrou que, no início da
epidemia, as maiores reduções na proporção razão de sexos ocorreram nos bairros da
69
zona sul e no Centro. Em 1999, as maiores reduções ocorreram nos bairros da zona
norte e da zona oeste, conforme apresentadas na Tabela 5.5.
O movimento de
crescimento da contaminação em mulheres acompanhou o crescimento da
contaminação na categoria de exposição homo e heterossexuais.
O mapa de renda
comprova que o crescimento das mulheres foi simultâneo ao empobrecimento da
população e ao movimento da epidemia para a zona norte. As Figuras 5.15a e 5.15b
apresentam o percentual de homens e mulheres por bairro, contaminados e vivos no
ano de 2005, nas quais o tom cinza-escuro representa os bairros com maiores taxas de
contaminação. Os homens são maioria nos bairros de Copacabana, Centro e Tijuca.
Esses bairros também apresentam as maiores taxas de contaminação em mulheres.
Entretanto, grande parte das mulheres reside em bairros da zona norte e oeste.
Tabela 5.5 Tabela de bairros com maiores reduções da razão de sexos, 1989 e 1999.
Maiores reduções
(1987-1989)
Copacabana
Anchieta
Rio Comprido
Lins de Vasconcelos
Ramos
Botafogo
Vaz Lobo
Razão de Sexos
-10,50
-8,17
-5,33
-5,00
-3,75
-3,50
-3,00
Maiores reduções
(1997-1999)
Jardim Guanabara
Engenho Novo
Bento Ribeiro
Jacaré
Todos os Santos
Lins de Vasconcelos
Tanque
Razão de Sexos
-25,50
-18,83
-11,40
-11,00
-11,00
-10,00
-8,00
Figura 5.15a Percentual de homens contaminados vivos por bairro, valores altos em tom
cinza-escuro, 2005, município do Rio de Janeiro.
70
Figura 5.15b Percentual de mulheres contaminadas vivas do bairro, valores altos em
tom cinza-escuro, 2005, município do Rio de Janeiro.
5.6.5 Nível de escolaridade
O nível de escolaridade apresentou o terceiro maior coeficiente de correlação com as
taxas de contaminação de bairros. A redução de escolaridade pode ser observada na
Figura 5.16. O empobrecimento da população de soropositivos ao longo do período
estudado, comprovado pela baixa renda das famílias nos bairros da zona da Leopoldina
e da zona norte (IBGE, Censo Demográfico, 1991 e 2000) foi associado à redução do
nível de escolaridade. A Figura 5.17 apresenta o percentual de chefes de família do
bairro com renda de até dois salários mínimos em 2005. O tom cinza-claro representa a
faixa de 2% a 19%, cinza-médio de 20% a 37% e cinza-escuro, de 38% a 56%.
A
Tabela 5.6 apresenta os bairros em ordem decrescente de percentual de pacientes com 8
a 11 anos de estudo. Com os dados disponíveis não foi possível identificar se o
empobrecimento é causa ou conseqüência do crescimento da contaminação em
mulheres.
71
100%
90%
80%
70%
60%
50%
40%
30%
20%
10%
0%
Ignorado
De 8 a 11 anos
De 3 a 7 anos
De 1 a 3 anos
Nenhuma
1982 1985
1988 1991
1994
1997
Figura 5.16 Anos de estudo de pacientes com notificações de aids, 1982 a 1999,
município do Rio de Janeiro.
Claro para
escuro:
2-19%
20-37%
38-56%
Figura 5.17 Percentual de chefes de família do bairro com renda de até dois salários
mínimos, 2005, município do Rio de Janeiro.
Tabela 5.6 Bairros com maior percentual de pacientes com escolaridade de 8 a 11 anos.
Bairro
%
Copacabana 18.70
Bairro
%
Leblon
3.02
Centro
2.93
Tijuca
6.74
Botafogo
4.92
Vila Isabel 2.49
Flamengo
4.31
Laranjeiras 2.23
Ipanema
4.04
Bangu
72
2.02
5.6.6 Resultados Obtidos com o Agrupamento de Dados
Usualmente, os mecanismos de difusão de epidemias reproduzem a estrutura social da
cidade, pressupondo-se, nesse caso, a interação entre semelhantes. Diferentemente,
identificou-se que a aids teve início com homens pertencentes a grupos com maior
renda e escolaridade, atingindo, em seguida, homens e mulheres de áreas periféricas da
cidade. A taxa de crescimento das mulheres é maior que a dos homens. Entretanto, os
homens ainda são maioria em valores absolutos. Não foi possível identificar uma
divisão de bairros por categoria de exposição, por intermédio de agrupamento de dados.
Por outro lado, o agrupamento dos bairros considerando-se o atributo IF, permitiu
identificar que a contaminação partiu da zona sul para o Centro, Leopoldina e seguiu em
direção à zona norte. A redução do nível de escolaridade e dos índices econômicosociais pode ser associada ao movimento em direção aos bairros das zonas norte e oeste
da cidade, considerando-se os índices econômico-sociais do IBGE. Apesar disso, os
bairros com maior volume de ocorrências, considerando-se todo o período, são Centro,
Copacabana e Tijuca.
O crescimento da contaminação em mulheres coincidiu com a redução do nível de
escolaridade e com o empobrecimento.
Entretanto, com os dados disponíveis não foi
possível identificar se o empobrecimento é causa ou conseqüência do crescimento da
contaminação em mulheres. Não há na bibliografia pesquisada, estudo similar com
dados do município do Rio de Janeiro. Estes padrões identificados foram utilizados nos
próximos capítulos da pesquisa.
5.7 Resumo
As principais características dos mapas auto-organizáveis são a ordenação topológica e
a representação da densidade dos dados de entrada no mapa. O agrupamento de dados
espaciais é uma das principais aplicações dos mapas auto-organizáveis.
O índice Calinski-Harabasz foi utilizado para definir o número ideal de agrupamentos.
A limitação do número de neurônios de saída ao número de agrupamentos é uma das
73
formas de se identificarem os agrupamentos existentes nos dados. Entretanto,
comprovou-se que esse método não é eficaz para grandes volumes de dados. Nesse
caso, pode ser necessário utilizar aumentar o total de neurônios da grade de saída e, em
seguida, utilizar um algoritmo de partição de grafos para interpretar o resultado.
Utilizou-se a informação de coordenadas geográficas dos bairros no vetor de
características, com objetivo de avaliar o impacto de informações sobre o espaço no
agrupamento. Experimentou-se, da mesma forma, a inclusão do índice de influência
espacial no vetor de características. Os resultados foram avaliados pelo índice de erro de
quantização vetorial, que mede a qualidade do mapa gerado. Entretanto, a inclusão do
IF, nos testes realizados não resultou em melhoria significativa, com redução do erro de
quantização vetorial. No presente capítulo, a IF foi utilizado como atributo de entrada
do vetor de características do agrupamento de bairros, com objetivo de expressar,
implicitamente, a dependência de cada bairro em relação à vizinhança no processo de
expansão da epidemia.
74
CAPÍTULO 6
ANÁLISE DA EPIDEMIA PELO VIRUS HIV
6.1 Introdução
Uma modelagem eficaz de qualquer epidemia deve considerar aspectos da geografia,
epidemiologia, estruturas sociais e a dinâmica dos atores envolvidos.
Estudos de
dinâmicas sociais como o de NOWELL e KLEINBERG (2003) e de KEMPE et. al.
(2005) indicam que em uma epidemia, a probabilidade de infecção de um nó da rede é
diretamente proporcional ao contato do nó com outros nós vizinhos infectados. Por
outro lado, os nós dessa rede não são estáticos e movimentam-se no espaço, o que torna
essa modelagem complexa.
O capítulo está dividido nos seguintes tópicos: 2. Objetivo; 3. Sistemas, Software e
Dados; 4. Conceitos; 5. Identificação das Fases da Epidemia; 6. Predição da Evolução
da Doença com Óbito; 7. Modelagem Espaço-Temporal; e 8. Resumo.
6.2 Objetivo
Como em todo sistema complexo, são inúmeros os desafios de identificar novos padrões
da epidemia pelo vírus HIV. No presente capítulo objetivou-se analisar a evolução da
epidemia no tempo. Os objetivos definidos foram: 1) identificar as fases da evolução da
epidemia, 2) realizar a predição da evolução da epidemia com óbito e 3) realizar a
modelagem espaço-temporal. Os objetivos definidos contribuem para o planejamento
de estratégias de ação preventivas ou assistenciais.
6.3 Sistemas, Software e Dados
Utilizou-se o software Statistica para definição das RNA utilizadas para realizar a
predição da evolução de epidemia por intermédio de séries temporais. Os casos são os
descritos no capítulo três.
75
6.4 Conceitos
6.4.1 Espaço
Para realizar a modelagem espaço temporal é necessário definir o conceito do termo
espacial.
Conforme mencionado na introdução, usualmente, em estudos sobre
epidemias, o conceito espacial está diretamente relacionado aos movimentos da
estrutura social envolvida e não só à localização geográfica. Entretanto, o registro sobre
a movimentação das pessoas infectadas (locais que freqüenta), não está disponível no
banco de dados utilizado.
Por esse motivo, o espaço nesse estudo, refere-se à
localização geográfica. Optou-se por utilizar o bairro de residência do paciente. A
Figura 6.1 apresenta os valores percentuais de ocorrências do bairro, em relação ao total
de casos e em relação à população do bairro, no período de 1982 a 2005.
10.00
0.30
9.00
0.25
8.00
7.00
0.20
6.00
5.00
0.15
4.00
0.10
3.00
2.00
0.05
1.00
0.00
0.00
% do total infec
% da pop bairro infec
Figura 6.1 Valores percentuais em relação ao total de casos e em relação à população do
bairro, 1982 a 2005, [ principais bairros ], município do Rio de Janeiro.
76
6.4.2 Séries Temporais
Séries temporais apresentam a evolução de uma ou mais variáveis em um período de
tempo. Para uma variável contínua no tempo, amostras são consideradas em intervalos
de tempo constantes, tornando-se dessa forma, uma série de valores discretos no tempo.
O objetivo da modelagem temporal é prever o valor da variável no instante s (t + k),
onde k > 0.
6.5 Primeiro Objetivo: Identificação das Fases da Epidemia
A segmentação da análise da epidemia objetivou facilitar a identificação de padrões
importantes para a proliferação da doença.
Utilizou-se o IF para medir as mudanças
bruscas da evolução da epidemia. A Figura 6.2 apresenta os bairros onde ocorreram as
dez maiores variações de IF, de 1982 a 1999. A partir de 2000, os valores de IF
sofreram pouca variação e, por isso, não foram considerados.
Figura 6.2 Bairros com dez maiores variações do IF, 1982 a 1999, município do Rio de
Janeiro.
6.5.1 Metodologia
Considerou-se a taxa de contaminação e o respectivo índice de influência espacial (IF)
para cada um dos cento e cinqüenta e três bairros a partir de 1983 até 2005. Durante o
77
ano de 1982, um único caso foi registrado no bairro de Bangú.
agrupamento de dados, utilizou-se o software Statistica 7.0.
Para executar o
Os resultados do
agrupamento de dados foram representados em um dendrograma, uma árvore que
apresenta a ordem de conexão. O corte do dendrograma em diferentes níveis resulta em
divisões da rede em um número menor ou maior de agrupamentos. Para facilitar a
análise inicial, utilizou-se um gráfico de linha com os valores da taxa de contaminação e
IF, com os bairros ordenados em função da posição no dendrograma. Desta forma, o
dendrograma resultante do agrupamento de dados hierárquico aglomerativo pode ser
comparado diretamente com os valores da taxa e do IF, para diferentes divisões da rede.
O dendrograma e o gráfico de linha das Figuras 6.3 e 6.4 facilitaram a análise. No ano
de 1983 o bairro de Sampaio apresentou taxa alta e IF baixo. Isso é explicado porque
nenhum bairro vizinho a Sampaio apresentou caso de AIDS naquele ano. Em 1984, o
bairro de Cidade Nova apresentou a maior taxa de contaminação e maior IF. O valor
alto de IF é justificado porque os vizinhos de Cidade Nova, Centro, Rio Comprido e
Tijuca também já haviam notificado casos de aids.
Figura 6.3 Dendrograma e gráfico de bairros, taxa da população contaminada pelo vírus
HIV e IF, por bairro, 1983, município do Rio de Janeiro.
78
Figura 6.4 Dendrograma e gráfico de bairros, taxa da população contaminada pelo vírus
HIV e IF, 1984, município do Rio de Janeiro.
A análise de dendrograma e do gráfico de linha com os valores da taxa de contaminação
da população do bairro e o valor do IF, em conjunto, facilitou a análise da evolução da
epidemia no espaço (bairro). Entretanto, este tipo de visualização é útil para pequenos
conjuntos de dados. Para identificar as fases da epidemia, considerou-se o IF uma
medida de conectividade da rede.
6.5.2 Proposta de Utilização do IF para Segmentação das Fases da Epidemia
Uma maneira de identificar pontos críticos na evolução de uma epidemia é através de
mudanças bruscas em medidas de conectividade da rede envolvida. Essa é a base da
teoria do Mundo-Pequeno (MILGRAN, 1969), que sugere que mudanças na ordem de
magnitude de medidas de conectividade da rede sejam consideradas para identificar os
pontos críticos da evolução temporal de uma epidemia.
Estudos sobre modelos
dinâmicos de redes sociais como o de NOOY et. al. (2005), afirmam que a
probabilidade de infecção de um nó da rede é função (sempre linear) do contato do nó
com os vizinhos infectados. Com base nestas teorias, utilizou-se o IF para identificar os
pontos críticos de proliferação da epidemia no tempo. Uma mudança brusca no índice
global de influência espacial indica uma mudança brusca na conectividade da rede.
Assim sendo, com base na variação deste índice, segmentou-se a epidemia em quatro
grandes grupos: uma fase inicial até 1988, caracterizada por mudanças bruscas do
79
índice, seguida de uma fase de proliferação da epidemia, de 1989 a 1992. A fase
seguinte, de 1993 a 1999, é caracterizada por uma estabilização do IF em todos os
bairros, exceto no bairro de Saúde. Finalmente, a fase de estabilização em todos os
bairros ocorre no período de 2000 a 2005, sem alteração brusca dos valores do IF, ou
seja, sem expansão geográfica significativa.
6.5.3 Identificação da Direção de Proliferação da Epidemia
Calculou-se o índice de influência espacial por direção-padrão a partir do foco da
epidemia em cada fase. A Tabela 6.1 apresenta os valores de IF90 e IF225 do bairro
Copacabana, ou seja, considerando-se o centróide de Copacabana como o eixo de
coordenadas, para definição de cada direção-padrão. Os valores de IF90 indicam a forte
influência dos bairros ao norte de Copacabana, com relação ao atributo taxa de
contaminação de aids do bairro, conforme apresentado nas Figuras 6.5a e 6.5b, com os
valores das taxas dos anos de 1988 e 1999, respectivamente. Ao contrário, a influência
dos bairros a noroeste de Copacabana (225º) não é expressiva, com valores 0.90 e 0.15
nos anos de 1988 e 1999.
Tabela 6.1 Índice de Influência Espacial por direção de Copacabana, 1988 e 1999.
IF por direção
1988
1999
IF90
6.31
6.90
IF225
0.90
0.15
80
Figura 6.5a Taxa de contaminação da aids por bairro, 1988, município do Rio de Janeiro
e retas na direção 90º e 225º a partir do centróide de Copacabana.
Figura 6.5b Taxa de contaminação da AIDS por bairro, 1999, município do Rio de
Janeiro e retas na direção 90º e 225º a partir do centróide de Copacabana.
6.5.4 Resultados obtidos
Através do cálculo do IFd por direção-padrão do bairro de Copacabana, centro da
epidemia na primeira fase, identificou-se o maior valor de IFd na direção 90º. A partir
da extremidade da reta imaginária que inicia em Copacabana nessa direção, calculou-se
mais uma vez o IFd , identificando-se a direção de 180º e assim sucessivamente
conforme apresentado na Figura 6.6.
A interpretação não é automática. Entretanto, o
cálculo do IFd relevante por fase da epidemia, permitiu identificar o movimento do
fenômeno estudado. As direções que prevaleceram foram no sentido norte, oeste e
norte. Apesar do cálculo do IFd ocorrer após o contágio e difusão da epidemia, ele
contribuiu para o conhecimento sobre o assunto estudado.
81
Legenda
1ª fase: Hotspot Copacabana e Centro
Figura 6.6 Prevalência de IFd por fase, município do Rio de Janeiro.
6.6 Segundo Objetivo: Predição da Evolução da Doença com Óbito
6.6.1 Análise de Séries Temporais
A análise da série temporal foi realizada através da decomposição em outras séries mais
simples. Usualmente, as séries mais simples são funções determinísticas do tempo
(CALOBA, 2002). A diferença (erro) entre a recomposição dessas séries simples e a
série real é uma série residual que, normalmente, inclui duas outras séries: uma série
cujo valor, em cada instante t, depende de forma complexa e não linear, dos valores da
série anteriores a t, e uma série de ruído randômico.
O objetivo da decomposição é identificar uma série residual que seja estacionária no
tempo. Uma série é dita estacionária no tempo se todos seus momentos estatísticos são
invariantes no tempo.
Esta condição é necessária para que os valores anteriores ao
tempo t possam ser usados para caracterizar estatisticamente a série em qualquer tempo.
No presente estudo, como é usual, garantiu-se que somente os dois primeiros
momentos, a média µ e a variância
2
, fossem invariantes no tempo. Neste caso, a
série é considerada fracamente estacionária no tempo.
82
Uma série pode sofrer transformações e decomposições, como a adição, a subtração ou
de outra série, que a torne estacionária no tempo. A decomposição aditiva é a mais
comum e nesse estudo, limitou-se ao seu uso.
A série de notificações de aids com fechamento óbito foi analisada em três domínios:
representação gráfica, correlograma e espectograma.
6.6.2 Análise no Domínio do Tempo
O coeficiente de correlação de Pearson r(x,y) ou simplesmente correlação, é uma
medida de dependência linear entre as variáveis x e y. A correlação varia no intervalo
[-1 , 1] (CALOBA, 2002). Considerando-se duas variáveis x e y independentes e
randômicas, o valor esperado de r será igual a zero. Conseqüentemente, o cálculo da
estatística de r a partir de N pares (x,y), i=1,.. N; resultará em uma distribuição normal
com média nula e desvio padrão igual a
1
N.
Desta forma, com um nível de
confiança de 95%, os valores de r de duas variáveis randômicas, sem correlação, estarão
entre
2
r
2
N e praticamente nenhum valor excederá
3 .
Assim sendo,
considerou-se o nível de confiança usualmente adotado de 95%, e a correlação entre
duas variáveis existente quando r
N.
2
6.6.2.1 Autocorrelação de uma Série Temporal
A autocorrelação de uma série temporal é a correlação da série entre o valor atual da
série s(t) e o valor atrasado de k unidades de tempo, s(t-k). Considerando-se N valores
de uma série estacionária no tempo, i = 1,...,N, e ( N – k ) pares (s(t), s(t+k)), t = 1,...,
N – k (CALOBA, 2002).
r k
1
2
s
1
N k
N k
t 1
s t
83
S
s t k
s
Onde µ é a média e
2
s
é a variância de s(t). O gráfico formado pelos eixos com valores
de s(k) e k é denominado autocorrelograma de s(t) (CHATFIELD 1989).
6.6.2.2 Correlação Cruzada entre Séries Temporais
A correlação cruzada entre duas séries temporais s1(t) e s2(t) estacionárias no tempo mede a
correlação entre a variável s2 no momento atual s2(t) e a variável s1 com atraso de k unidades
de tempo s1(t-k). Desta forma, a autocorrelação:
rs1s2 k
1
s1
onde
s1
,
s2
,
s1
,
s2
s2
1
N k
N k
t 1
s1 t
S1
s2 t k
s2
são as médias e desvios padrões de s1(t) e s2(t) respectivamente. O
gráfico é denominado correlograma entre as séries s1 e s2 (CALOBA, 2002).
Correlações somente são consideradas válidas após a extração da tendência da série.
6.6.3 Análise no Domínio da Frequência
Uma série s(t), t=1,2,...,N pode ser representada por uma soma de senóides.
N
1
2
s t
a0
Ri cos
i 1
Onde Ri2
2
it
N
i
aN
cos t
2
ai2 bi2 é a energia com que a senoide de freqüência f i
a série. O gráfico de Ri2 f i versus f i
i N contribui para
i N é o espectograma da série. Frequências
com contribuições significativamente acima da média indicam formas repetitivas no
tempo, ou sazonalidades.
Espectrogramas somente são calculados após a extração da
tendência da série. A energia contida na tendência altera aspectos importantes do seu
conteúdo.
84
No presente estudo, utilizou-se a Transformada Rápida de Fourier ou FFT, do termo em
inglês Fast Fourier Transform, implementado através do software Statistica 7.0. A
transformada rápida de Fourier (FFT) é um eficiente algoritmo para calcular a
transformada de Fourier discreta (DFT) e sua inversa. Existem muitos algoritmos FFT.
A DFT decompõe uma sequência de valores em componentes de diferentes freqüências.
Apesar de útil, o cálculo da DFT é pouco pratico. O algoritmo FFT é uma maneira de
calcular o mesmo resultado mais rapidamente. O cálculo da de uma DFT de N pontos,
utiliza O (N2) operações aritméticas, enquanto uma FFT pode calcular o mesmo
resultado em apenas O (N log N) operações. As FFT são de grande importância para
uma ampla variedade de aplicações, a partir de processamento digital de sinais e
resolver equações diferenciais parciais a algoritmos para uma rápida multiplicação de
grandes inteiros. A idéia geral de uma FFT foi popularizada por uma publicação de
COOLEY e TUKEY (1965). O desenvolvimento do FFT é descrito por COOLEY et. al.
(1967).
Muitos trabalhos posteriores foram publicados em IEEE Transactions on
Acoustics, Speech and Signal Processing. O desenvolvimento da FFT é apresentado,
entre outros autores, por BLOOMFIELD (1976) e por PRIESLEY (1981).
6.6.4 Decomposição Clássica de Séries Temporais
A decomposição clássica de séries temporais é usualmente realizada extraindo-se a
tendência, a sazonalidade e as componentes senoidais. Além disso, os valores são
normalizados para a faixa [-1,1] antes desta decomposição.
Comportamentos
irregulares, com mudanças bruscas na série foram desconsiderados antes da
decomposição. Um exemplo de mudança brusca ocorreu com a redução de pessoas
contaminadas pelo vírus HIV entre 1990 e 1992.
6.6.5 Resultados obtidos
6.6.5.1 Predição da Série de Óbitos: Primeiro Modelo
A análise de séries temporais foi utilizada com os dados da evolução da doença com
fechamento óbito, no período de 1985 a 2005, para o qual a predição foi realizada. Em
2002, período 204 na Figura 6.7, a série sofreu uma mudança significativa em sua
85
tendência. A Figura 6.7a apresenta a série com valores normalizados e a Figura 6.7b, a
série após a retirada da tendência e da sazonalidade.
Variável total de óbitos normalizada
z(x,M=50.45,S=26.29);
4
3
3
2
2
1
1
0
0
-1
-1
-2
-2
SIT2
4
-3
-20
0
20
40
60
80
100
120
140
160
180
200
220
240
-3
260
SIT2SZ
Figura 6.7a Série de óbitos normalizada, 1985 a 2005, município do Rio de Janeiro.
4
4
3
3
2
2
1
1
0
0
-1
-1
-2
-2
-3
-20
0
20
40
60
80
100
120
140
160
180
200
220
240
-3
260
Figura 6.7b Série de óbitos normalizada, sem tendência e sem sazonalidade, 1985 a
2005, município do Rio de Janeiro.
O espectograma obtido por FTT da série de óbitos da Figura 6.7b, está apresentado na
Figura 6.8 e indica freqüências dominantes, que foram extraídas pelo programa de
cálculo da FFT. O resultado está apresentado na Figura 6.9. A série após a retirada dos
ciclos senoidais está apresentada na Figura 6.10.
86
Periodogram Values
5
5
4
4
3
3
2
2
1
1
0
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0
0.50
0.45
Frequency
Periodogram Values
Figura 6.8 Espectograma da série de óbitos, obtido por intermédio da FFT.
2.0
2.0
1.5
1.5
1.0
1.0
0.5
0.5
0.0
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
0.45
0.0
0.50
Frequency
Figura 6.9 Espectograma da série de óbitos após a retirada das freqüências dominantes.
87
sit2_sciclo2
P lot of variable: sit2_sciclo2
2.5
2.5
2.0
2.0
1.5
1.5
1.0
1.0
0.5
0.5
0.0
0.0
-0.5
-0.5
-1.0
-1.0
-1.5
-20
0
20
40
60
80
100
120
140
160
180
200
220
240
-1.5
260
Figura 6.10 Série residual sem ciclos senoidais.
Em seguida, calculou-se a autocorrelação (Figura 6.11), que é a ferramenta natural para
a análise de um processo estocástico no tempo (CHATFIELD, 1989). A autocorrelação
parcial (Figura 6.13) permite identificar os períodos de tempo (atraso em meses) que
podem ser utilizados como variáveis de entrada do modelo de previsão em uma rede
neural.
Autocorrelation Function
Lag
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
(Standard errors are white-noise estimates)
Corr. S.E.
+.415 .0626
+.150 .0625
+.049 .0624
-.111 .0622
-.209 .0621
-.123 .0620
-.155 .0619
-.089 .0617
-.183 .0616
-.148 .0615
-.071 .0614
+.010 .0612
+.058 .0611
+.120 .0610
+.032 .0608
+.026 .0607
+.005 .0606
+.004 .0605
+.044 .0603
-.017 .0602
+.031 .0601
-.038 .0599
-.084 .0598
-.108 .0597
-.066 .0596
-.139 .0594
-.035 .0593
+.035 .0592
+.061 .0590
+.080 .0589
+.138 .0588
+.026 .0586
-.011 .0585
-.135 .0584
-.101 .0582
-.116 .0581
-.040 .0580
-.047 .0578
-.019 .0577
+.002 .0576
+.095 .0574
+.087 .0573
+.191 .0571
+.203 .0570
+.154 .0569
+.089 .0567
+.036 .0566
-.066 .0565
-.086 .0563
-.126 .0562
0
-1.0
-0.5
0.0
0.5
Q
43.88
49.62
50.25
53.43
64.79
68.76
75.02
77.08
85.92
91.69
93.02
93.04
93.95
97.81
98.09
98.27
98.28
98.28
98.82
98.90
99.17
99.57
101.6
104.8
106.1
111.5
111.8
112.2
113.3
115.1
120.6
120.8
120.9
126.2
129.2
133.2
133.7
134.4
134.5
134.5
137.2
139.5
150.7
163.4
170.7
173.2
173.6
174.9
177.3
182.3
0
p
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
.0000
1.0
Figura 6.11 Função de autocorrelação da série residual.
88
Conf. Limit
Partial Autocorrelation Function
(Standard errors assume AR order of k-1)
Lag
Corr. S.E.
1
+.415 .0630
2
-.027 .0630
3
-.004 .0630
4
-.153 .0630
5
-.132 .0630
6
+.032 .0630
7
-.112 .0630
8
+.016 .0630
9
-.222 .0630
10
-.033 .0630
11
-.015 .0630
12
+.027 .0630
13
+.018 .0630
14
-.002 .0630
15
-.085 .0630
16
-.012 .0630
17
-.006 .0630
18
+.004 .0630
19
+.045 .0630
20
-.107 .0630
21
+.098 .0630
22
-.118 .0630
23
+.010 .0630
24
-.097 .0630
25
-.001 .0630
26
-.140 .0630
27
+.036 .0630
28
+.046 .0630
29
-.013 .0630
30
+.042 .0630
31
+.017 .0630
32
-.072 .0630
33
-.074 .0630
34
-.134 .0630
35
-.027 .0630
36
-.060 .0630
37
+.035 .0630
38
-.062 .0630
39
-.044 .0630
40
+.014 .0630
41
+.063 .0630
42
-.014 .0630
43
+.119 .0630
44
+.028 .0630
45
+.053 .0630
46
+.027 .0630
47
+.037 .0630
48
-.022 .0630
49
-.050 .0630
50
-.036 .0630
0
-1.0
-0.5
0.0
Conf. Limit
0.5
1.0
Figura 6.12 Função de autocorrelação parcial da série residual.
Os resultados da função de autocorrelação e da função de autocorrelação parcial da
série, apresentados nas Figuras 6.11 e 6.12, caracterizam a dependência dessa variável
no tempo. Considerando-se o conjunto de atrasos com correlação significativa, foram
utilizados inicialmente como entradas da RNA, os valores da série com atrasos de cinco,
nove e vinte e seis atrasos. Após os testes, somente as entradas com cinco e nove
atrasos foram consideradas na camada de entrada da RNA.
Experimentalmente,
chegou-se a uma RNA com seis neurônios na camada intermediária para previsão do
valor da série residual. A Figura 6.13 apresenta os resultados obtidos para a saída real e
a prevista desta RNA. As séries são coloridas para permitir a análise. O erro relativo
absoluto médio, para os doze primeiros meses, do conjunto de teste foi de 1.8%.
89
2.5
2.0
2.0
1.5
1.5
1.0
1.0
0.5
0.5
0.0
0.0
-0.5
-0.5
-1.0
-1.0
-1.5
0
20
40
60
80
100
sit2_sciclo2 (L)
120
140
160
180
200
sit2_sciclo2_predito:
sit2_sciclo2:
2.5
-1.5
220
sit2_sciclo2_predito (R)
Figura 6.13 Período de teste, série real e previsão.
6.6.5.2 Predição da Série de Óbitos: Segundo Modelo
No segundo modelo, as variáveis com correlação significativa com a série de óbitos
foram consideradas como entrada da RNA, com os respectivos atrasos identificados na
análise das séries no domínio do tempo.
Calculou-se a correlação cruzada entre a série de óbitos e a série de notificações de aids.
Da mesma forma, o cálculo foi realizado considerando-se as séries formadas por
sintomas e doenças indicativas de casos de aids, conforme critério adotado pelo
Ministério da Saúde para pessoas com treze anos ou mais. Os critérios considerados
foram critério CDC adaptado e o critério Brasil/Caracas adotados pelo Ministério da
Sáude (2004). Inesperadamente, não foi identificada correlação significativa com as
séries de sintomas.
Por outro lado, o resultado da análise considerando-se os
indicadores econômico-sociais, indicou uma forte correlação entre a série de óbitos e a
série de pacientes com escolaridade de um a três anos de estudo. A Figura 6.14
apresenta as séries após a retirada de tendência e sazonalidade. Verificou-se também
uma significativa correlação com a série de pacientes do sexo masculino. Entretanto,
após a retirada da tendência e sazonalidade, essa correlação decresceu. Observou-se
também uma significativa correlação com todas as faixas etárias, com variação do
atraso por faixa etária.
Finalmente, observou-se uma significativa correlação com a
90
série formada pelo atributo contagem de linfócitos CD+4 inferior a 350 células/mm3. A
4
4
3
3
2
2
1
1
0
0
-1
-1
-2
-2
-3
-20
0
20
40
60
80
100
120
ESC2SZ (L)
140
160
180
200
220
240
SIT2SZ:
ESC2SZ:
Figura 6.15 apresentada as séries após a retirada de tendência e sazonalidade.
-3
260
SIT2SZ (R)
Figura 6.14 Série de óbitos e série de pacientes com escolaridade de um a três anos,
após a retirada de tendência e da sazonalidade, 1985 a 2005, município do Rio
de Janeiro.
Figura 6.15 Séries de óbitos e CD+4 inferior a 350 células/mm3, após a retirada de
tendência e sazonalizadade, 1985 a 2005, município do Rio de Janeiro.
A correlação cruzada é a ferramenta natural para a análise da relação entre duas séries
no domínio do tempo.
Para a análise baseada na função de densidade espectral,
denominada análise no domínio da freqüência (CHATFIELD, 1989), calculou-se a
correlação cruzada entre as variáveis, identificando-se as freqüências características dos
91
eventos que influenciam na variabilidade da evolução da epidemia com óbito. Analisouse a coerência entre os picos das séries, verificando-se a correlação linear existente entre
espectro de duas variáveis, no processo denominado Bivariado (CHATFIELD, 1989).
CrossCorrelation Function
First : SIT2SZ
Lagged: ESC2SZ
Lag
-25
-24
-23
-22
-21
-20
-19
-18
-17
-16
-15
-14
-13
-12
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Corr. S.E.
.3583
.3645 .0664
.0662
.3704
.3756 .0661
.0659
.3988
.4369 .0658
.0657
.4497
.0655
.4440
.4714 .0654
.0652
.4804
.4766 .0651
.0650
.5133
.5302 .0648
.0647
.5313
.5354 .0645
.0644
.5442
.0643
.5473
.5768 .0642
.0640
.6055
.6130 .0639
.0638
.6051
.6296 .0636
.0635
.6678
.6888 .0634
.0632
.7513
.0631
.8300
.7454 .0630
.0631
.6940
.6523 .0632
.0634
.6205
.5909 .0635
.0636
.5616
.5187 .0638
.0639
.5042
.0640
.4501
.4330 .0642
.0643
.4478
.4351 .0644
.0645
.4061
.3830 .0647
.0648
.3641
.3518 .0650
.0651
.3261
.0652
.3244
.3076 .0654
.0655
.2835
.2695 .0657
.0658
.2230
.2027 .0659
.0661
.1861
.1714 .0662
.0664
0
-1.0
Conf . Limit
-0.5
0.0
0.5
1.0
Figura 6.16a Correlação cruzada entre a série de óbitos e série de pacientes com
escolaridade de um a três anos, 1985 a 2005, município do Rio de Janeiro.
CrossCorrelation Function
First : SIT2SZ
Lagged: I35-39SZ
Lag
-30
-29
-28
-27
-26
-25
-24
-23
-22
-21
-20
-19
-18
-17
-16
-15
-14
-13
-12
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
Corr..0671
S.E.
.1144
.1214
.0670
.1424
.0668
.1390
.0667
.1184
.0665
.1367
.1392 .0664
.0662
.1650
.0661
.2035
.0659
.2258
.0658
.2319
.0657
.2389
.2264 .0655
.0654
.2615
.0652
.2754
.0651
.3061
.0650
.3423
.0648
.3749
.3476 .0647
.0645
.3819
.0644
.3826
.0643
.3938
.0642
.4289
.0640
.4356
.0639
.4377
.0638
.4366
.0636
.4707
.0635
.5292
.0634
.5707
.0632
.6385
.0631
.7512
.0630
.6594
.0631
.5963
.0632
.5969
.0634
.5564
.0635
.5420
.0636
.5701
.0638
.5440
.0639
.5507
.0640
.5083
.0642
.5006
.0643
.5133
.0644
.5196
.0645
.5135
.0647
.5010
.0648
.4700
.0650
.4500
.0651
.4622
.0652
.4611
.0654
.4509
.0655
.4391
.0657
.4326
.4021 .0658
.0659
.3927
.0661
.3721
.0662
.3719
.0664
.3147
.0665
.2916
.2813 .0667
.0668
.2848
.2619 .0670
.0671
0
-1.0
Conf. Limit
-0.5
0.0
0.5
1.0
Figura 6.16b Correlação cruzada entre a série de óbitos e série de pacientes na faixa
etária de 35 a 39 anos, após a retirada de tendência e da sazonalidade, 1985 a
2005, município do Rio de Janeiro.
92
CrossCorrelation Function
First : SIT2SZ
Lagged: I30-34SZ
Lag
-25
-24
-23
-22
-21
-20
-19
-18
-17
-16
-15
-14
-13
-12
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Corr..0664
S.E.
.1384
.1553
.0662
.1691
.0661
.1884
.2338 .0659
.0658
.2409
.0657
.2823
.0655
.3128
.0654
.3032
.0652
.3065
.0651
.3394
.0650
.3403
.0648
.3686
.0647
.3846
.0645
.4208
.0644
.4369
.0643
.4641
.0642
.4764
.5010 .0640
.0639
.5166
.0638
.5696
.0636
.5894
.0635
.6047
.0634
.6088
.0632
.6499
.0631
.7301
.0630
.6827
.0631
.6520
.0632
.6433
.0634
.6203
.0635
.5760
.0636
.5817
.0638
.5669
.0639
.5793
.0640
.5580
.0642
.5493
.0643
.5487
.0644
.5649
.0645
.5764
.0647
.5726
.0648
.5472
.0650
.5373
.0651
.5239
.0652
.5299
.0654
.4987
.0655
.4674
.4682 .0657
.0658
.4668
.0659
.4479
.0661
.4578
.4345 .0662
.0664
0
-1.0
Conf. Limit
-0.5
0.0
0.5
1.0
Figura 6.16c Correlação cruzada entre a série de óbitos e série de pacientes na faixa
etária de 30 a 34 anos, após a retirada de tendência e da sazonalidade, 1985 a
2005.
CrossCorrelation Function
First : SIT2SZ
Lagged: AIDSSZ
Lag
-25
-24
-23
-22
-21
-20
-19
-18
-17
-16
-15
-14
-13
-12
-11
-10
-9
-8
-7
-6
-5
-4
-3
-2
-1
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Corr. S.E.
.2431 .0664
.2387 .0662
.2420 .0661
.2450 .0659
.2475 .0658
.2497 .0657
.2634 .0655
.2655 .0654
.2706 .0652
.2744 .0651
.2851 .0650
.2936 .0648
.2927 .0647
.3027 .0645
.3024 .0644
.2975 .0643
.3016 .0642
.3142 .0640
.3128 .0639
.3243 .0638
.3201 .0636
.3366 .0635
.3523 .0634
.3580 .0632
.3982 .0631
.4659 .0630
.4018 .0631
.3781 .0632
.3584 .0634
.3325 .0635
.3088 .0636
.3110 .0638
.2869 .0639
.2809 .0640
.2579 .0642
.2357 .0643
.2404 .0644
.2501 .0645
.2387 .0647
.2275 .0648
.2094 .0650
.1903 .0651
.1809 .0652
.1641 .0654
.1498 .0655
.1230 .0657
.1214 .0658
.0980 .0659
.0877 .0661
.0753 .0662
.0661 .0664
0
-1.0
Conf. Limit
-0.5
0.0
0.5
1.0
Figura 6.16d Correlação cruzada entre a série de óbitos e série de notificações de aids,
após a retirada de tendência e da sazonalidade, 1985 a 2005.
93
Para a análise no domínio da freqüência, realizou-se a análise do espectro cruzado entre
as séries, no processo denominado bivariado. A série CD+4 inferior a 350 células/mm3
apresentou densidade espectral alta para os períodos de seis, sete, vinte e dois e vinte e
cinco meses, conforme Tabela 6.2. A coerência mede o quadrado da correlação linear
entre os dois componentes do processo bivariado na freqüência considerada e é análogo
ao quadrado do coeficiente de correlação. Através dos valores altos de coerência entre
as séries comprovou-se a correlação linear entre as variáveis para atrasos de seis
períodos, assim como para atrasos de vinte e dois e vinte e cinco meses.
Tabela 6.2 Espectro cruzado entre as séries de óbitos e de escolaridade de um a três
anos.
Frequência
0.163
0.044
0.040
0.131
0.095
Período
6.146
22.909
25.200
7.636
10.500
Densidade
Espectral Amplitude Coerência
1.607
0.611
0.959
2.217
2.234
0.952
2.974
2.976
0.946
1.601
0.611
0.940
0.838
0.908
0.930
Os maiores valores de densidade espectral ocorreram para atrasos de vinte e cinco e
vinte e dois períodos. A maior coerência ocorreu para atrasos de seis períodos. Essas
informações foram consideradas nos testes para definição do modelo de predição.
Os
valores das variáveis com os respectivos atrasos foram considerados como entrada da
RNA.
Tabela 6.3 Espectro cruzado entre as séries de óbitos e de escolaridade 1 - 3 anos.
Frequência
0.142857
0.067460
0.043651
0.039683
0.023810
Período
7.0000
14.8235
22.9091
25.2000
42.0000
Densidade
Espectral Amplitude Coerência
0.99601
0.99992 0.905224
1.74806
1.78372 0.890544
3.50925
3.57700 0.882909
3.95224
4.13331 0.791450
2.50136
2.57758 0.759659
94
Além do atributo CD+4 Considerou-se um atraso de seis períodos para a série de
pacientes com escolaridade de um a três anos. Considerou-se ainda, como entrada da
rede, o total de casos de aids notificados com atraso de um período, com objetivo de
informar à rede o total de ocorrências do período. Após experimentos, a topologia da
RNA foi especificada com a camada de entrada formada por valores do atributo CD+4
com atrasos de seis, vinte e dois e vinte e cinco períodos e o atributo de escolaridade
entre um e três anos com atraso de sete e vinte e dois períodos, e finalmente da série de
notificações de aids com atraso de um período.
Posteriormente, verificou-se que
mantendo-se somente as entradas de CD+4, o desempenho era praticamente o mesmo.
O total de duzentos e cinqüenta e dois pares de entrada e saída, referente aos valores das
séries por mês / ano, referente ao período de 1985 a 2005, foram utilizados. Deste total,
cinqüenta por cento para treinamento, trinta para verificação e vinte para teste da RNA
de múltiplas camadas com algoritmo backpropagation. Apesar de pequena quantidade
de dados para treinamento, o resultado foi satisfatório. Essa arquitetura de RNA
apresentou o melhor desempenho com a configuração de nove neurônios na camada
intermediária e funções de ativação linear para a camada de entrada e saída e função de
ativação tangente hiperbólica para camada intermediária. As predições de óbitos foram
realizadas para seis períodos. A Tabela 6.4 apresenta os resultados obtidos conforme o
número de épocas. O melhor desempenho ocorreu com quinhentas épocas com erros
iguais a 0.0082 e 0.0083 para treinamento e verificação respectivamente. A Figura 6.17
apresenta a relação entre os valores observados e previstos.
Tabela 6.4 Erros de treinamento e verificação da RNA MLP de 3 camadas.
Épocas
100
500
700
Erro de treinamento
0.1021
0.0082
0.0084
95
Erro de verificação
0.1933
0.0083
0.0085
Figura 6.17 Valores observados e previstos, visualização Statistica.
6.7 Terceiro Objetivo: Modelagem Espaço-Temporal
Os atributos utilizados foram selecionados conforme método de relevância de variáveis
proposto por SEIXAS et. al. (1995) e, também, considerando-se o resultado do
agrupamento de bairros realizado no capítulo cinco. A avaliação do modelo, mais uma
vez, foi realizada com vinte anos de epidemia. Dois modelos que combinam diferentes
fatores foram avaliados.
incidência.
Um dos modelos explica parcialmente a variação da
Nenhuma variável relacionada à epidemia foi utilizada. A camada de
entrada da rede foi composta somente por índices econômico-sociais com o objetivo de
realizar a predição da taxa de contaminação do bairro. Nesse teste, o resultado obtido
não foi aceitável. Em seguida, após a inclusão do índice de influencia espacial na
camada de entrada do RNA, o modelo produziu estimativas mais acuradas.
Mais uma vez, para a análise da série no domínio do tempo, calculou-se a correlação
cruzada, que é a ferramenta natural para a análise de correlação entre séries no tempo
(CHATFIELD, 1989). Em seguida, calculou-se o espectro cruzado entre as variáveis,
identificando-se as freqüências características dos eventos que influenciam na
variabilidade da evolução da epidemia. Analisou-se a coerência entre os picos das
séries, verificando-se a correlação linear existente entre espectro de duas variáveis, no
processo denominado Bivariado (CHATFIELD, 1989).
96
Objetivou-se identificar as influências de variáveis relacionadas ao espaço e ao
ambiente na evolução da doença.
As séries de ocorrências da epidemia foram
analisadas juntamente com variáveis consideradas determinantes de saúde, como: (i)
condições e estilos de vida (índice de desenvolvimento social do bairro e proporção de
domicílios alugados, entre outras), grau de instrução (proporção de chefes de família
com terceiro grau e por faixa de anos de estudo, entre outras) e; (ii) situação ambiental,
traduzido pelos índices sanitários do bairro da residência da pessoa infectada. Neste
último conjunto, nenhuma variável mostrou-se relevante. As variáveis consideradas no
modelo foram: proporção de domicílios alugados, proporção de responsáveis pelo
domicílio com rede de até dois salários, proporção de responsáveis pelo domicílio com
terceiro grau, conforme definição de variáveis relevantes apresentado no capítulo 3.
A camada de entrada da RNA de três camadas, recebeu o identificador do bairro, os
valores da taxa de contaminação por mês/ano, de cada um dos cento e cinqüenta e três
bairros, e o valor do índice de influência espacial referente à taxa de contaminação do
bairro no mês/ano, além das variáveis relevantes. O ciclo da série temporal considerado
foi de doze meses. O neurônio da camada de saída é a taxa prevista de contaminação do
bairro para um mês no futuro. Os cinco melhores resultados desta configuração estão
apresentados na Tabela 6.5. O erro absoluto médio foi de 3.8%. Não foi possível
realizar com sucesso a modelagem com a RNA que não recebeu a informação do
atributo índice de influência espacial do bairro na camada de entrada obteve um
resultado muito inferior, invalidando a modelagem.
Tabela 6.5 Resultado parcial da RNA para predição da taxa de contaminação do bairro.
bai.1
Data Mean
Data S.D.
Error Mean
Error S.D.
Abs E. Mean
S.D. Ratio
Correlation
32.59748
34.58198
-0.19715
3.95542
1.26705
0.11438
0.99353
Tx_ano.1
bai.2
Tx_ano.2
bai.3
Tx_ano.3
bai.4
Tx_ano.4
bai.5
Tx_ano.5
6.274476 32.59748 6.274476 32.59748 6.274476 32.59748 6.274476 32.59748 6.274476
5.771567 34.58198 5.771567 34.58198 5.771567 34.58198 5.771567 34.58198 5.771567
-0.010961 -0.06244 0.017757 -0.10471 -0.006256 -0.10745 0.038832 -0.06133 0.025515
1.070499 3.74167 0.988237 3.73755 0.932536 4.01468 1.008170 3.00481 0.948174
0.413338 0.91970 0.345035 0.69735 0.298192 1.04206 0.398266 0.94709 0.285458
0.185478 0.10820 0.171225 0.10808 0.161574 0.11609 0.174679 0.08689 0.164284
0.982684 0.99413 0.985254 0.99415 0.986864 0.99324 0.984681 0.99622 0.986429
97
6.8 Resumo
Em razão das profundas modificações nos estágios evolutivos da infecção pelo HIV, o
exame das tendências da epidemia deve combinar dados provenientes dos casos do
passado, com aqueles derivados da investigação e identificação de novos padrões da
doença. Através da análise integrada das notificações da doença com diferentes períodos
e condições de manifestação, objetivou-se identificar as influências de variáveis
relacionadas ao espaço e ao tempo na evolução da doença. Não foi identificada
correlação significativa com as variáveis relacionas ao meio ambiente como condições
sanitárias, número de banheiros, rede de esgoto, entre as variáveis apresentadas no
Anexo Indicadores Econômico-Sociais.
Por outro lado, a identificação da forte
correlação dos óbitos com algumas variáveis, conforme apresentado no capítulo,
demanda ações de controle e pesquisa. A identificação de pacientes com contagem de
CD+4 acima de 350mm, fortemente correlacionada ao óbito pode efetivamente reduzir
o total de casos com óbito.
A predição da taxa de contaminação por bairro obteve resultado razoável com a
inclusão do índice de influencia espacial na camada de entrada da RNA definida.
98
CAPÍTULO 7
ANALISE DA EPIDEMIA COM A ABORDAGEM DE REDES COMPLEXAS
7.1 Introdução
Os movimentos de indivíduos em locais distintos, assim como o contato entre grupos de
pessoas diferentes são essenciais na modelagem de uma epidemia. Os deslocamentos
diários das pessoas de um local para outro, como entre residência e local de trabalho,
formam uma rede dinâmica de interações espaciais entre pessoas.
O estudo dessas
interações espaciais é complexo por diversos motivos. Inicialmente, há a dificuldade
em obter esse tipo de informação. A segunda dificuldade é a quantidade de variáveis
envolvidas, além do grande volume de dados, o que torna a modelagem desse sistema
uma tarefa bastante complexa.
No presente capítulo, analisou-se a epidemia pelo vírus HIV como um problema de
redes complexas. Os padrões identificados por intermédio das tarefas de mineração de
dados geográficos, na segunda parte da tese, foram analisados com esta abordagem.
As análises consideraram pessoas (pacientes), locais(bairros e unidades hospitalares) e
as relações entre eles. Entretanto, os pacientes que residem em um bairro não são
estáticos e movimentam-se constantemente. Além disso, a infecção pelo vírus HIV
depende de inúmeros fatores, que, inclusive, não estão diretamente relacionadas a essa
movimentação, mas a hábitos e práticas sexuais, entre outras variáveis. Apesar disso, o
presente estudo, propõe-se a analisar a rede como uma entidade estática, baseando-se
nas conexões formadas pela geografia. As tarefas de mineração de dados, assim como a
análise do índice de influência espacial comprovaram a importância da vizinhança na
proliferação da epidemia. Por esse motivo, buscou-se integrar as informações e padrões
identificados às redes complexas, numa tentativa de explicar, por intermédio da
estrutura da rede, o fenômeno estudado.
Os seguintes tópicos são apresentados: 2. Objetivo 3. Sistemas, Software e Dados, 4.
Conceitos, 5. Análise da Difusão da Epidemia, 6. Resultados Obtidos e 7. Resumo.
99
7.2 Objetivo
O capítulo apresenta a influência da estrutura da rede formada na difusão da epidemia e
o momento da formação da massa critica na evolução da epidemia. Na análise de redes
sociais, estuda-se a estrutura da rede, responsável pela transmissão de comportamentos,
atitudes, doenças. Objetivou-se identificar padrões de contágio de difusão da epidemia e
integrar os padrões identificados na primeira parte da tese com a abordagem de redes
sociais.
7.3 Sistemas, Software e Dados
Utilizaram-se o software Pajek e também o Netdraw. Os conceitos apresentados foram
extraídos, principalmente, de NOOY et. al. (2005). Os exemplos são os desenvolvidos
no presente estudo. A base de dados de notificações de aids, de 1982 a 2005, do
Sistema Nacional de Notificação (SINAN), mais uma vez foi utilizada. Em alguns
casos, porém, o período foi segmentado.
7.4 Conceitos
O principal objetivo de uma rede social é identificar e interpretar padrões de conexões
sociais entre os atores da rede. A teoria de redes sociais é originária da teoria dos
grafos. Um grafo representa a estrutura da rede, através dos vértices e de um conjunto
de linhas, que são as conexões entre os vértices.
Os conceitos apresentados são necessários ao entendimento do estudo realizado e da
proposta apresentada. Entretanto, esse tópico não se propõe a apresentar todos os
conceitos relacionados a redes sociais.
7.4.1 Cálculo, Medidas de Estrutura da Rede e Visualização
Na análise de redes sociais, algumas medidas referem-se à rede total, enquanto outras
resumem a posição estrutural de uma sub-rede ou de um único vértice. O cálculo produz
100
um número único no caso de uma característica da rede e uma série de números no caso
de sub-redes e vértices.
A exploração da estrutura de uma rede por medidas é mais precisa do que a inspeção
visual. Entretanto, os índices sobre a estrutura da rede usualmente são abstratos e de
difícil interpretação. Conseqüentemente, ambos, a inspeção visual e o cálculo dos
índices estruturais foram utilizados na análise da estrutura da rede no presente capitulo.
A rede pode ser desenhada de muitas maneiras e cada desenho enfatiza características
estruturais diferentes. Por esse motivo, alguns princípios básicos de desenho de redes
foram observados. O principio mais importante estabelece que a distância entre vértices
deve expressar a força ou o número de seus vínculos. Em um mapa, a distância entre
cidades iguala sua distância geográfica.
Da mesma forma, os vértices conectados
devem ser desenhados mais próximos do que aqueles que não estão relacionados e o
comprimento da linha deve ser proporcional ao valor da linha.
7.4.2 Redução da Rede
Na análise de redes sociais, freqüentemente uma parte significativa da rede é extraída
para análise. As visualizações são mais simples para redes de pequeno (dezenas) ou
médio porte (centenas) do que para redes grandes de milhares de vértices. Alguns
procedimentos analíticos exigem que redes complexas com laços ou linhas múltiplas
sejam primeiramente reduzidas a grafos simples.
A redução da rede é uma
simplificação e utiliza uma partição da rede. No estudo da epidemia pelo vírus HIV,
apesar de existirem diferentes tipos de relações, focou-se em uma única relação, de cada
vez, para executar a redução da rede. Um exemplo de relação: bairros da zona sul da
cidade.
Uma partição da rede é uma classificação ou clustering dos vértices da rede.
Cada vértice é assinalado para exatamente uma classe ou cluster. As partições dividem
os vértices de uma rede num número de subconjuntos mutuamente exclusivos. As
partições dividem uma rede de três formas: extraindo-se uma parte (visão local),
reduzindo-se cada classe de vértices num novo vértice (visão global) ou, selecionandose uma parte e reduzindo-se as classes vizinhas para focar na estrutura interna e posição
global desta classe (visão contextual).
101
7.4.2.1 Visão Global
A maneira mais fácil de reduzir uma rede é escolher uma classe de vértices. Um dos
principais objetivos da análise da terceira parte da tese foi identificar o movimento entre
bairros, assim como a interação entre bairros de residência e unidades hospitalares
utilizadas pelos pacientes. Utilizou-se uma partição para gerar uma sub-rede com a
visão global por região da cidade (zona sul, norte, oeste, entre outras). A visão
contextual obtida após a remoção das conexões entre bairro e unidade hospitalar
inferiores a 1% do total do período considerado, facilitou a identificação das principais
relações entre regiões da cidade e unidades hospitalares. A Figura 7.1a apresenta a
visão global. A Figura 7.1b apresenta a visão contextual.
Figura 7.1a Rede reduzida de bairros e unidades, visão global, 1982 a 1999, município
do Rio de Janeiro.
Esta global representa cada região da cidade por um vértice. A zona norte é a principal
usuária de quatro das cinco principais unidades. A exceção é a unidade identificada por
11312, onde os principais usuários residem na zona sul. A visão contextual permitiu
observar ainda que, considerando-se somente a região do Centro, os principais usuários
da unidade 11312 são os pacientes que residem no bairro do Cajú e no bairro de Santa
102
Teresa. A redução da rede não permitiu identificar um padrão entre bairros e unidades
hospitalares, haja vista que o principal usuário de todas as unidades desloca-se da região
norte. Nesse caso, outro tipo de análise é mais eficaz para a descoberta de padrões.
Figura 7.1b Rede reduzida de bairros e unidades, visão contextual, 1982 a 1999,
município do Rio de Janeiro.
7.4.3 Vetores e Partições
As propriedades dos vértices da rede, que não dependem da estrutura da rede,
constituem os atributos dos vértices.
Vetores armazenam os atributos contínuos
(valores contínuos) dos vértices da rede, atribuindo um valor numérico para cada vértice
103
da rede.
Partições armazenam os valores discretos. Ambos foram amplamente
utilizados na descoberta de padrões desse trabalho.
Considerou-se a categoria de exposição de homossexuais de cada bairro ao longo do
tempo. De acordo com o resultado do agrupamento de dados geográficos realizado com
estes dados no capítulo cinco, classificaram-se os bairros como baixo, médio ou alto, de
acordo com o percentual da população do bairro contaminada. Em seguida, os valores
destes atributos, por período do tempo considerado, foram comparados. A Figura 7.2a
mostra que a classificação mudou drasticamente entre 1982 e 1992. Do total de cento e
trinta e três bairros classificados como baixo no ano de 1988, trinta e quatro tiveram sua
classificação modificada para médio e vinte e dois para alto, em 1999. O índice Rajski
identificado por [C1 –> C2] mede se C2 pode ser previsto por C1. O valor 0.23 indica
a forte mudança ocorrida, ou seja, o índice de 1992 não pode ser previsto pelo de 1988.
Usualmente, o índice Cramer’s V superior a 0.6 indica uma forte correlação entre os
atributos. Entretanto, o cálculo não é totalmente confiável quando a freqüência de uma
célula é igual a zero, conforme aviso na listagem gerada pelo software Pajek.
Crosstabs
|
0
1
2
3|
Total
--------------------------------------------------0|
3
0
0
0|
3
1|
0
77
34
22|
133
2|
0
0
0
8|
8
3|
0
0
0
7|
7
--------------------------------------------------Total|
3
77
34
37|
151
Warning: 13 cells (81.25%) have expected frequencies less than 5!
Chi-Square: 202.0902
Cramer's V: 0.6679
Rajski(C1 -> C2): 0.2302
Figura 7.2a Análise estatística Crame’s V e Rajski entre taxas de contaminação de
homossexuais por bairro, software Pajek, 1992 e 1999, município do Rio de
Janeiro.
104
7.4.4 Medidas de Centralidade
O conceito de centralidade e centralização está baseado na idéia simples de que a
doença (ou informação) pode alcançar mais facilmente, as pessoas que são centrais em
uma rede de contágio (ou comunicação). Invertendo-se o argumento, as pessoas são
centrais se a infecção em uma rede de contágio, ou a informação em uma rede de
comunicação, as alcança facilmente.
Quanto maior o número de fontes accessíveis a
uma pessoa, mais fácil será obter informação.
Neste sentido, os vínculos sociais
constituem um capital social que pode ser utilizado para mobilizar os recursos sociais.
No estudo sobre a epidemia pelo vírus HIV, a unidade hospitalar mais central e
acessível, provavelmente obterá mais recursos financeiros e mais informações sobre a
epidemia. Nesse caso, essa informação pode ser usada na destinação de recursos ou na
implantação de novas estratégias de combate a epidemia.
O indicador mais simples de centralidade é o número de vizinhos do vértice, que é seu
grau numa rede simples não direcionada. Quanto mais alto o grau de um vértice, maior
o total de fontes de contágio, mais rapidamente a epidemia chegará ao vértice, sendo
conseqüentemente, mais central. Em uma rede de comunicação, de forma similar,
quanto mais alto o grau de um vértice, mais rapidamente a informação chegará a ele. Na
Figura 7.2b, a unidade 7323 se comunica com não menos do que quatorze bairros
enquanto a unidade 7943 possui somente um vínculo de comunicação. Neste caso, a
unidade 7323 é mais central do que a 7943. Informação sobre a epidemia chegará mais
rápido na unidade 7323.
105
Figura 7.2b Rede formada por unidades hospitalares utilizadas e bairros de residência
dos pacientes contaminados pelo vírus HIV, 1985, município do Rio de
Janeiro, visualização com NetDraw.
7.4.5 Coesão da Rede, Densidade e Conectividade
O conceito de coesão de uma rede social está ligado aos conceitos de densidade e
conectividade. A coesão de uma rede social pode ser medida pelo total de conexões
existentes na rede. A densidade é definida como o total de conexões de uma rede
simples (sem conexões múltiplas), expressa como uma proporção do número máximo
de conexões possível. Uma rede denominada completa é aquela que possui densidade
máxima.
A medida de densidade depende do tamanho da rede. Por esse motivo, usualmente, a
conectividade de uma rede é mensurada pelo grau médio da rede, que é a média dos
graus dos seus vértices. O grau de um vértice é o número de conexões que possui com
outros vértices. Intuitivamente, quanto maior o grau médio da rede, maior a coesão.
Essa medida independe do tamanho da rede e por isso, pode ser utilizada para comparar
redes sociais. Em uma rede direcionada o grau de entrada e de saída é o total de
conexões que chegam ou que partem do vértice. Na rede não direcionada, não há essa
diferença. Em uma rede não direcionada, o grau de um vértice é igual ao total de
vizinhos.
106
Definiu-se uma rede de bairros, considerando-se a distribuição geográfica. Não foram
considerados os acessos através de ruas e avenidas, mas somente a proximidade
espacial. A rede de bairros está apresentada no Anexo K. O valor mais freqüente de
conexões por bairro é de 4 vizinhos e a distribuição de freqüência varia de 0 a 18
vizinhos, conforme Figura 7.3.
O bairro com maior número de conexões é
Jacarepaguá.
1. All
Degree partition of N4 (153)
-----------------------------------------------------------------------------Dimension: 153
The lowest value: 0
The highest value: 18
Frequency distribution of cluster numbers:
Cluster
Freq
Freq%
CumFreq
CumFreq% Representative
--------------------------------------------------------------0
2
1.3072
2
1.3072 71-ENGENHEIRO LEAL
1
3
2
10
1.9608
5
3.2680 109-RIBEIRA
6.5359
15
3
9.8039 15-URCA
21
13.7255
36
23.5294 17-LEME
4
34
22.2222
70
45.7516 2-GAMBOA
5
27
17.6471
97
63.3987 10-GLORIA
6
26
16.9935
123
80.3922 3-SANTO CRISTO
7
16
10.4575
139
90.8497 1-CENTRO
8
5
3.2680
144
94.1176 14-BOTAFOGO
9
5
3.2680
149
97.3856 31-ALTO DA BOA VISTA
10
2
1.3072
151
98.6928 33-VILA ISABEL
12
1
0.6536
152
18
1
0.6536
153
99.3464 66-IRAJA
100.0000 81-JACAREPAGUA
--------------------------------------------------------------Sum
153
100.0000
Figura 7.3 Distribuição de freqüência de bairros por número de conexões, município do
Rio de Janeiro.
Grande parte dos bairros (63%) possui até cinco vínculos e o crescimento do número de
vínculos não resulta no aumento da taxa de contaminação. A análise do total de
vínculos de forma isolada, não permitiu identificar um padrão de contágio e proliferação
da epidemia.
107
7.4.6 A força das Conexões Fracas
Segundo NOOY et. al. (2005), em redes sociais, pessoas com fortes vínculos tendem a
desenvolver grupos fechados. Um exemplo são os laços familiares: vários ou todos os
membros de uma família mantêm fortes vínculos entre si. Como conseqüência, os
vínculos familiares não são úteis para, por exemplo, encontrar novas oportunidades de
emprego porque todos se relacionam com as mesmas pessoas entre si. De forma
contrária, contatos menos intensos e irregulares tais como colegas antigos ou
conhecidos são melhores fontes de informação em relação a novas oportunidades de
trabalho. Estes vínculos fracos podem agir, mais facilmente, como pontes para redes
distantes de informação. Esse é o conceito da força dos vínculos fracos.
Freqüentemente, vínculos fracos são mais importantes para dispersar informação ou
doenças, que vínculos fortes. Esse conceito foi utilizado na análise de componentes e
no agrupamento dos vértices da rede.
7.4.7 K-Cores
O conceito de k-cores está relacionado ao conceito de agrupamento, onde os
agrupamentos são determinados pelo número mínimo de vizinhos de um vértice. Ao
definir uma partição k-core, todos os vértices que possuem, no mínimo, k vizinhos, são
agrupados. A Figura 7.4 apresenta o valor de k-core de cada vértice.
7.4.8 Centralidade de uma rede
7.4.8.1 Rede em Estrela
A rede em estrela é a estrutura mais eficiente dado um número fixo de conexões. Uma
estrela é uma rede em que um vértice está conectado com todos os outros vértices, mais
estes vértices não estão conectados entre si. Isto conduz à idéia de que uma rede é mais
centralizada se os vértices mudam mais em relação a sua centralidade. Maior variação
na pontuação de centralidade dos vértices gera uma rede mais centralizada.
108
Figura 7.4 Valor de k-core por bairro, município do Rio de Janeiro.
Centralização é a variação no grau dos vértices dividida pela máxima variação em grau
possível dado o número de vértices da rede. Numa rede simples de um tamanho dado, a
rede em estrela tem variação máxima de grau. A divisão pela variação máxima garante
que o grau de centralização varie de zero (sem variação) a 1 (máxima variação), no caso
de uma rede em estrela.
A variação é a soma (absoluta) das diferenças entre a pontuação de centralidade dos
vértices e a máxima pontuação de centralidade entre eles. Na Figura 7.5, a rede em
estrela é formada pelas conexões formadas por pacientes que residem no município do
Rio de Janeiro e que realizaram o diagnóstico em outros municípios do estado. O
município do Rio de Janeiro (vértice central) possui grau vinte e quatro, que é o grau
máximo em uma rede simples não direcionada deste tamanho, porque este vértice está
conectado a todos os outros vinte e quatro vértices. Os outros vértices têm grau mínimo,
igual a 1. Então a variação de grau é quinhentos e setenta e seis, calculado da seguinte
forma: vinte e quatro vértices contribuem com 24 x (25 – 1) conexões e vértice central
contribui com 1 x (24 – 24). Numa rede simples não direcionada desse tamanho, esse é
109
a maior variação de grau. Assim sendo, como 576 é a variação máxima, e dividindo 576
por ele mesmo, obtemos um grau de centralização igual a 1.00.
Numa rede com linhas múltiplas ou laços múltiplos, o grau de um vértice não é igual ao
número de seus vizinhos. Nesse caso, a rede em estrela não tem necessariamente
variação máxima e a pontuação de centralização é superior a 1.00. Por esse motivo, não
é possível comparar a variação numa rede com linhas múltiplas ou laços múltiplos com
a variação numa rede em estrela simples do mesmo tamanho.
Figura 7.5 Rede estrela de pacientes que residem no município do Rio de Janeiro e que
realizaram diagnóstico de infecção pelo vírus HIV em outro município, 1982 a
2005.
7.4.9 Distância e Caminho
Numa rede simples não direcionada, o grau de centralidade é apenas o número de
vizinhos de um vértice. Em alguns casos, essa é a única informação disponível sobre a
posição dos vértices na rede. Entretanto, em uma rede, o contágio (ou a informação)
chegará mais facilmente a uma pessoa quando não é necessário percorrer um longo
caminho. Esse é o conceito de distância em redes, ou seja, o número de passos ou
intermediários necessários para um vértice alcançar outro vértice na rede. Quanto
110
menor a distância entre vértices, maior o risco de contagiar pessoas. Em uma rede de
comunicação, quanto menor o número de passos, mais fácil obter informação.
Caminho é uma seqüência de linhas onde nenhum vértice, entre o primeiro e o último
vértice, aparece mais que uma vez. Um nó da rede é alcançável por outro se existe um
caminho do último para o primeiro. Dois nós são mutuamente alcançáveis se estão
conectados por um caminho numa rede não direcionada. Entretanto, dois caminhos (um
em cada direção) são necessários em uma rede direcionada.
Na rede não direcionada, a distância entre dois vértices é simplesmente o número de
linhas ou passos no caminho mais curto que conecta os vértices. O caminho mais curto é
também chamado geodésico. Na rede direcionada, o geodésico de um vértice ao outro é
diferente do geodésico na direção oposta e as distâncias podem ser diferentes.
Entender os padrões que, de alguma forma, expliquem a proliferação da epidemia é um
dos principais objetivos de qualquer estudo nessa área. Com isso em mente, calculou-se
a distância entre notificações, considerando-se o par formado por uma notificação e a
que a antecede. A Tabela 7.1 apresenta distribuição de freqüência de distância entre
uma notificação e a anterior. A distância média entre uma notificação e a anterior foi
igual a 3.45 vértices, aproximadamente e a moda é igual a 4 vértices.
A Figura 7.6
apresenta a ordem cronológica de contaminação da rede formada pelos bairros com
notificações de contaminação pelo vírus HIV, de 1982 a 1985. O número do vértice
indica a ordem de contaminação.
111
Tabela 7.1 Distribuição de freqüência de distância (total de vértices) entre uma
notificação de aids e a anterior, 1982 a 1985, município do Rio de Janeiro.
Distância
Total
%
0
9
7.62
1
11
9.32
2
20
16.94
3
19
16.10
4
26
22.03
5
12
10.16
6
12
10.16
7
8
6.77
8
1
0.84
total
118
100
Figura 7.6 Cronologia de notificações de aids, 1982 a 1985, município do Rio de
Janeiro.
112
7.4.9.1 Proximidade da Centralidade
Com o conceito de distância, define-se um índice de centralidade, que é chamado
proximidade da centralidade. A proximidade da centralidade de um vértice é baseada na
distância total entre um vértice e todos os outros vértices, onde as distâncias maiores
geram as pontuações menores de centralidade. Quanto mais próximo está um vértice de
todos os outros vértices, mais facilmente a informação chegará a ele, e maior será sua
centralidade.
Tal qual o grau de centralização, a proximidade da centralização pode ser conceituada
como a quantidade de variação nas pontuações de proximidades das centralidades dos
vértices. Da mesma forma, compara-se a variação dos valores de centralidade com a
máxima variação possível, ou seja, com a variação de proximidade da centralidade de
uma rede estrela do mesmo tamanho.
A proximidade da centralidade de um vértice é o total de vértices vizinhos dividido pela
soma de todas as distâncias entre o vértice e os outros. Proximidade da centralização é
a variação na proximidade da centralidade dos vértices dividida pela máxima variação
possível nas pontuações de proximidades de centralidade numa rede do mesmo
tamanho.
Analisou-se, entre outras, a correlação entre a medida de proximidade da centralidade
do bairro e o percentual da população infectada do bairro. A Figura 7.7, representa a
medida de centralidade do bairro pelo tamanho do seu vértice, que aparentemente não
se correlaciona com a taxa de contaminação. Entretanto, essa conclusão é inadequada.
O início da epidemia ocorreu em Copacabana e Centro, e, portanto, não coincidiu com a
região geográfica central do município. Entretanto, ao considerar-se a rede lógica,
formada pelos bairros contaminados ano a ano, a centralidade e a proximidade da
centralidade passaram a apresentar alta correlação com a proliferação da epidemia,
conforme esperado.
113
Figura 7.7 Centralidade do bairro, 2005, município do Rio de Janeiro.
7.4.10 Intermediação
Os conceitos de grau e centralidade estão baseados na acessibilidade do vértice na rede,
ou seja, na forma que a epidemia atinge o vértice. Uma segunda abordagem de
centralidade e centralização baseia-se na idéia de que um vértice é mais central se o
mesmo é mais importante na cadeia de contágio, ou seja, se o vértice é intermediário,
localizando-se entre os demais vértices.
De forma mais simples, esse conceito
relaciona-se com a interrupção da epidemia, caso o vértice não existisse ou
deliberadamente não transmitisse a informação adiante.
Nesse estudo, esse conceito foi denominado intermediação. Nesse caso, a centralidade
do vértice mede o quanto o mesmo é elo da cadeia de contatos da rede, facilitando a
difusão da epidemia. Considerando-se o geodésico como a principal via de contágio
entre os atores de uma rede, o ator que estiver localizado no geodésico de vários pares
de vértices, é, conseqüentemente, importante para o fluxo de disseminação da epidemia
(ou informação) na rede. Esse ator é mais central. A análise do poder de intermediação
de um vértice é importante para ações preventivas de bloqueio ou interrupção da
114
epidemia, especialmente nos casos em que a detecção ocorre no período inicial de
expansão.
Cada par de vértices contribui para a centralidade de intermediação de um vértice. Em
geral, a centralidade de intermediação de um vértice é a proporção de todos os
geodésios de todos os pares da rede, que incluem esse vértice.
A centralização de
intermediação é a variação do valor de intermediação dos vértices dividido pela máxima
variação de intermediação possível em uma rede do mesmo tamanho.
Na rede em estrela, o centro possui o valor máximo, pois todos os geodésios o incluem.
De forma contrária, os demais vértices possuem valor de centralidade de intermediação
mínimo, porque não estão localizados entre os outros vértices da rede.
7.4.11 Pontes
Um conceito importante no estudo da difusão da epidemia é o conceito de ponte. Em
uma rede complexa, existem afunilamentos que são vitais para o fluxo de contágio, que
podem impedir ou dificultar a disseminação do vírus, mediante ações de prevenção.
Na Figura 7.10, a conexão entre A e B é claramente um funil porque é o único canal de
intercambio entre B e os demais. Formalmente este vínculo é uma ponte na rede, porque
sua remoção cria um novo componente, isolado dos outros componentes.
Da mesma
forma, a exclusão de um vértice da rede, também exclui da rede o vértice e todas as
linhas que incidem nesse vértice. O conceito de vértice-corte, do termo em inglês cutvertex, é um vértice que quando excluído, aumenta o número de componentes na rede.
Os vértices que incidem numa ponte podem ou não ser vértices-corte. Na Figura 7.10,
A e B formam uma ponte, entretanto o remoção de B e sua ponte com A não aumenta o
número de componentes.
Utilizou-se o conceito de ponte e vértices-corte na pesquisa, com o objetivo de definir
seções da rede complexa formadas pelos bairros que são praticamente invulneráveis à
remoção (interrupção do contato) ou manipulação de um único vértice, chamadas bicomponentes. Um bi-componente é simplesmente um componente – uma sub-rede com
115
conexão máxima – de tamanho mínimo três sem um vértice-corte. Num bi-componente,
nenhum bairro pode controlar completamente o fluxo do vírus entre outros dois bairros
porque existe sempre um caminho alternativo. Num bi-componente, cada bairro
conecta-se pelo menos com dois outros (numa rede não direcionada).
Em redes
complexas, um bi-componente é mais coesivo do que um componente forte ou fraco
porque existem pelo menos dois caminhos diferentes entre cada par de vértices, ou seja,
dois caminhos que não compartilham um vértice entre o ponto inicial e o final.
Resumindo o conceito, um bi-componente é um componente de tamanho mínimo três
que não contém um vértice-corte.
A Figura 7.8 apresenta a identificação do bi-
componente ao qual o vértice pertence. Há somente três vértices com a característica de
vértice-corte na rede formada por bairros: Cidade Universitária, conectado ao Galeão e
Pedra de Guaratiba.
Isso significa que não há gargalos para a proliferação do vírus,
analisando-se geograficamente.
Figura 7.8 Bi-componentes e vértices-corte, 2005, município do Rio de Janeiro.
116
7.4.12 Rede-ego e Conceito de Restrição
A análise da estrutura da rede é uma abordagem sócio-centralizada. Outra abordagem é
a abordagem ego-centralizada ou rede-ego, em que o foco é na posição de um vértice da
rede e suas oportunidades de agenciar ou intermediar com outros vértices.
Nessa
abordagem utiliza-se a figura de uma tríade, que consiste em um vértice focal (ego), um
vértice alternativo, um terceiro vértice e os vínculos entre eles. A tríade é a menor rede
que contém mais do que dois vértices, destacando as complexidades dos vínculos dentro
de um grupo.
Uma tríade completa reduz o individualismo dos seus membros. Considerando-se o
exemplo de uma rede formada por três pessoas, quando estão completamente
conectadas, elas compartilham normas e informação, criam confiança por retorno, e os
conflitos entre dois membros podem ser resolvidos pela terceira pessoa. Em outras
palavras, as conexões completas entre três pessoas fazem que se comportem como um
grupo no lugar de um conjunto de indivíduos. O conceito pode ser aplicado a outras
redes.
B
C
A
Figura 7.9 Tríade incompleta
Numa tríade não direcionada que está conectada, porém incompleta, como o exemplo da
Figura 7.9, os vértices são consideradas menos ligados pelas normas do grupo. O vértice
A (pessoa A) está numa posição de vantagem em relação às demais porque ela pode
intermediar com as outras duas, fazendo-as competir, o que não seria possível se o
vértice (B) e a terceira pessoa (C) fizessem um acordo entre si. Isto é conhecido como
tertius gaudens (o terceiro que se beneficia) ou a estratégia tertius, que induz e explora
a competição ou rivalidade entre os outros dois, que não se relacionam diretamente. O
buraco estrutural permite que o ego aplique sua estratégia.
117
Uma variante mais maliciosa é conhecida como estratégia divide-e-governa, na qual
uma pessoa cria e explora conflitos entre os outros dois para controlar ambos. Um
exemplo ocorre quando o ego faz intrigas trazendo hostilidade entre os outros dois. Isto
não seria possível se eles pudessem verificar diretamente a informação e descobrir a
estratégia subversiva do ego. Novamente, o buraco estrutural permite que o ego aplique
sua estratégia.
Nas duas estratégias, a vantagem ou o poder de um indivíduo estão baseados no seu
controle sobre a contaminação por um vírus, disseminação da informação, bens ou
serviços que saem da estrutura de sua rede. A intermediação está relacionada com a
ausência de vínculos (i.e. a presença de buracos) entre vizinhos. As oportunidades que
um buraco estrutural oferece numa tríade incompleta têm um lado oposto: elas implicam
restrições numa tríade completa. Uma tríade completa não é apenas uma tríade sem
oportunidades por não ter buracos estruturais. A situação é ainda pior do ponto de vista
da intermediação, porque não é possível se retirar de nenhum desses vínculos pouco
compensadores sem criar um buraco estrutural ao seu redor. Na rede, o ego A é mais ou
menos obrigado a manter os vínculos. Caso contrário, cria-se um buraco estrutural ao
seu redor do ego, do qual o vértice alternativo pode tirar vantagem.
A
0.25
C
B
0.25
5
0.33
E
D
Figura 7.10 Exemplo de rede.
118
7.4.12.1 Rede-ego
A rede-ego é formada por um ego, os vizinhos do ego, e os vínculos entre eles. A redeego de um vértice (Figura 7.10) contém todas as tríades que incluem esse vértice. Para
cada tríade na rede de bairros, analisou-se a posição do vértice (na posição de ego) e o
risco de contaminar os outros bairros, que podem estar ou não conectados diretamente
entre si. Da mesma forma, analisou-se a restrição que é exercida pelos vínculos, como a
que B exerce sobre A na Figura 7.10. Considerando-se que nenhum outro vizinho de A,
está conectado diretamente com B, não existe restrição em A causada por seu vínculo
com B. Uma restrição baixa indica a existência de buracos estruturais, que podem ser
explorados. Essa propriedade foi utilizada na análise de unidades hospitalares.
De forma contrária, a restrição nos vínculos de A com C, D e E é muito alta porque
estes vínculos estão envolvidos em três tríades completas. Quando A se retira de
qualquer destes vínculos, eles podem começar a intermediar sem ele. Quanto maior a
restrição, menor o número de oportunidades para intermediar e maior o perigo de
retirar-se de um vínculo. Esta restrição é conhecida como restrição diádica associada
com um vínculo do ponto de vista do ego. A restrição de um vínculo no ego pode ser
diferente da restrição experimentada pelo vértice alternativo no mesmo vínculo. O
vínculo entre A e C, por exemplo, é mais restrito para C do que para A, porque todas as
tríades da rede-ego de C são completas.
Finalmente, deve ser considerada a importância de um vínculo para um vértice. Se um
vínculo é muito barato em relação a investimento não é um problema ser obrigado a
mantê-lo. Se o vínculo é apenas um entre muitos (baixa exclusividade), o ego não
depende muito deste vínculo. Por outro lado, se o vínculo entre o alternativo e a terceira
parte não é importante para eles, pode funcionar como um vínculo ausente, que,
conseqüentemente pode ser explorado. No presente estudo, esse conceito foi utilizado
para analisar a importância de uma unidade hospitalar em relação aos bairros. Também
foi considerado na análise da rede formada por um bairro em relação aos seus vizinhos.
O bairro é o único elo de um segundo bairro com todos os demais bairros, assume papel
importante na proliferação da epidemia.
A análise de buracos estruturais da rede
também é utilizada na segmentação da rede em componentes ou agrupamentos.
119
Conforme mencionado no início do capítulo, os pacientes que residem em um bairro
não são estáticos e movimentam-se constantemente. Entretanto, o presente estudo,
propõe-se a analisar a rede como uma entidade estática, baseando-se nas conexões
formadas pela geografia. Por esse motivo, buscou-se integrar as informações e padrões
identificados ao estudo de redes complexas, numa tentativa de explicar e entender a
importância da estrutura da rede no fenômeno estudado.
A força proporcional de um vínculo em relação a todos os vínculos de um vértice é um
indicador simples da importância ou exclusividade do vínculo. É computada como o
valor das linhas que representam um vínculo, dividido pela soma dos valores de todas
as linhas incidentes no vértice. Se os valores da linha representam custos (risco de
contaminação, tempo ou energia), a força proporcional de um vínculo é a porção do
gasto total de um ator que é investida nos vínculos com um vértice alternativo. Na
Figura 7.10, o vínculo entre A e B é um entre os quatro vínculos de A (0.25). A força
proporcional de um vínculo deve ser representada por uma rede direcionada. A rede
original pode conter linhas múltiplas, linhas direcionadas e não direcionadas, e valores
de linhas, mas a rede com vínculos de força proporcional é sempre simples, direcionada
e contém somente arcos bi-direcionados.
Na Figura 7.10, a restrição de A sobre E é igual à raiz da soma de: 0.25 (investimento
de A em E), mais 0.25 x 0.33 (vínculo de A para C e de C para E), mais 0.25 x 0.33
(idem para D). Os valores são as forças proporcionais e o valor da restrição de A com E
(assim como C e D) é igual a 0.17 e o com B é igual a 0.0625. A restrição de A em B é
aproximadamente 1/3 de que possui com os demais membros da rede. Há um buraco
estrutural entre A e B. A restrição agregada de um vértice é obtida pela soma de todas
as restrições diádicas de um vértice. Assim sendo, a restrição agregada de A é igual a
0.585. A Figura 7.11 apresenta os valores de restrição agregada dos vértices.
Segundo NOOY et. al. (2005) pesquisas indicam que, organizações e pessoas com
valores de restrição agregada menores apresentam melhor desempenho.
Esse
desempenho é medido por intermédio da comparação do valor da restrição de um ator
da rede com um ou mais indicadores de desempenho, como os econômicos,
exemplo.
120
por
Finalmente, a densidade egocêntrica de um vértice é a densidade de suas conexões, ou
seja, é a proporção de suas conexões em relação ao total de conexões. A Figura 7.12
apresenta os valores de densidade egocêntrica dos bairros. O coeficiente de correlação
entre a densidade egocêntrica e a taxa de contaminação dos bairros é de 0.25.
A restrição diádica no vértice u exercida por um vínculo entre os vértices u e v é a
extensão em que u tem mais e mais fortes vínculos com vizinhos que estão fortemente
conectados com o vértice v.
Figura 7.11 Valores de restrição agregada de bairros, município do Rio de Janeiro.
Em geral, quanto maior o número de conexões diretas com um bairro, maior a restrição
agregada do vértice.
121
Figura 7.12 Valores de densidade egocêntrica de bairros, município do Rio de Janeiro.
Os conceitos apresentados foram utilizados no presente capítulo. Os resultados obtidos
fazem referência a estes conceitos.
7.5 Objetivo
7.5.1 Primeiro Objetivo: Difusão da Epidemia
Conforme mencionado na introdução do capítulo, os vínculos pessoais são relevantes
para a difusão de uma epidemia. Entretanto, dificilmente, esses dados estão disponíveis.
Por esse motivo, objetivou-se estudar a difusão da epidemia baseando-se na estrutura da
rede de bairros.
7.5.1.1 Contágio
Modelos de difusão em rede são baseados no processo de contaminação e, por isso, são
denominados contágio social. O processo de contágio segue um padrão. Normalmente,
poucas pessoas são contaminadas no início do processo, com crescimento vertiginoso
até estabilização da taxa de contaminação da doença. Esse padrão é conhecido como
reação em cadeia, no qual uma pessoa infectada contamina seus contatos e assim,
122
sucessivamente. A curva de contaminação pelo vírus HIV é um exemplo de curva de
difusão, onde o eixo do x representa o momento da contaminação e o eixo y a
prevalência da contaminação, conforme apresentado na Figura 7.13. A prevalência é a
freqüência acumulada, ou seja, é a soma percentual de pessoas contaminadas.
A curva de difusão tem o formato da curva S, característica da curva de reação em
cadeia. Se considerarmos uma rede randômica e um vértice escolhido aleatoriamente
como a origem de uma contaminação, que contamina o vizinho e assim sucessivamente,
o gráfico da difusão formado será o da curva S, similar ao gráfico da evolução da aids
(Figura 7.13).
Quando o contágio é um importante fator na difusão de uma epidemia
(como a aids), a estrutura da rede é importante variável na identificação de padrões.
120.00
100.00
80.00
60.00
40.00
20.00
1995
1994
1993
1992
1991
1990
1989
1988
1987
1986
1985
1984
1983
1982
0.00
freq acum (%)
Figura 7.13 Curva de contágio (bairros com notificações), 1982 a 1996, município do
Rio de Janeiro.
7.5.1.2 Exposição e Limiar
As pessoas não são igualmente susceptíveis ao contágio. Um vizinho infectado não é
suficiente transmitir o vírus, principalmente no caso da aids, com características
distintas das demais epidemias. Na realidade, algumas pessoas são mais receptivas às
medidas de precaução do que outras. Existem duas formas de definir o risco das
pessoas, em relação ao sistema e em relação à suas redes pessoais: categorias de adoção
e categorias limiares. Estas tipologias são muito populares em marketing de produto.
As categorias de adoção classificam as pessoas pelo seu tempo de adoção com relação a
123
todos os outros adotantes. Uma classificação padrão faz distinção entre: 1) os adotantes
iniciais (16% iniciais), 2) a maioria inicial (os próximos 34%), 3) a maioria tardia (os
34% seguintes) e os adotantes tardios ou retardatários (os últimos 16% a adotar). Desta
forma, a classificação das pessoas obedece o critério de tempo de adoção. Da mesma
forma que essa classificação é útil para objetivos de marketing, considerou-se que pode
ser útil também para identificar as características sociais e demográficas dos pacientes
iniciais em caso de uma epidemia.
Na análise de vinte e cinco bairros que correspondem aos dezesseis por cento que
sofreram contágio nos primeiros anos, observou-se que as variáveis econômicas e
sociais apresentaram grande variabilidade. O mesmo ocorreu para os indicadores da
estrutura da rede. O índice de centralidade variou de 0.001 a 0.08, entre esses bairros. O
percentual de chefes de família com quinze anos ou mais de estudo variou de 1.6% a
60%. Por esse motivo, optou-se por utilizar a segunda abordagem para a análise.
A segunda abordagem do contágio, denominada categorias limiares, leva em
consideração a rede dos atores. O modelo de rede de difusão está baseado no contágio:
um ator contamina seus contatos. Assim sendo, a possibilidade de um ator se
contaminar aumenta quando ele está ligado a um número grande de atores que já se
contaminaram, ou seja, quando o ator está exposto a um número grande de
soropositivos, no caso da aids. A quantidade de exposição varia com o tempo e com os
atores, o que explica, pelo menos parcialmente, que alguns bairros sejam atingidos pela
epidemia mais cedo, mesmo não estando próximos às fontes num processo de difusão.
A exposição de um ator expressa-se como uma proporção e pode ser entendida como
uma possibilidade de contágio. A exposição de um vértice da rede num momento
particular é a proporção de seus vizinhos que adotaram antes desse momento.
124
1982
1983
1984 1985
1993
1996
Figura 7.14 Rede de bairros por ordem de contaminação e valor de exposição, 1984,
município do Rio de Janeiro.
A Figura 7.14 mostra a rede de bairros com a exposição dos vértices em 1984, indicada
pelo
tamanho dos vértices e os respectivos valores entre parênteses. Os vértices
invisíveis têm exposição zero, nenhum dos seus vizinhos apresentou caso de aids antes
ou durante 1984. Onze dos quinze bairros que apresentaram casos em 1984 tinham
vizinhos entre os bairros com contaminação em 1983. O bairro da Gávea (código 23)
era o mais exposto com cinqüenta por cento de seus vizinhos com casos de
contaminação (exposição de 0.50) no final de 1984. Porém, nem todos expostos em
1984 apresentaram casos em 1985. Conforme esperado, o modelo de contágio simples,
que pressupõe que a contaminação de um vértice da rede depende da quantidade de
exposição, não explica integralmente a epidemia da aids.
A análise estatística da difusão de dados nem sempre encontra uma relação sistemática
entre exposição e adoção. Conseqüentemente, nem sempre encontra uma relação
sistemática entre exposição e contágio. Isto significa que o contágio apresenta diferentes
níveis de exposição. Esse conhecimento é intuitivo e, conforme mencionado
125
anteriormente, a contaminação pelo vírus HIV depende de inúmeras variáveis, e muito
específicas. Alguns bairros do município, e sua população, apresentaram maior
vulnerabilidade.
No modelo de rede de difusão, a probabilidade de contágio de um bairro (que representa
sua população) é percebida como seu limiar à exposição. O limiar de um indivíduo é o
grau de exposição que ele precisa para ser contaminado. Então, as diferenças entre os
limiares individuais podem explicar as diferenças no tempo de contaminação e porque
alguns não se contaminaram, ainda que expostos. O limiar de um ator é sua exposição
no momento da contaminação.
Na Figura 7.14, no ano de 1982, o bairro de Bangu (código 99) expôs seis vizinhos
(com códigos 97, 98, 100, 101, 102, 104), considerando-se somente aqueles com os
quais ele faz fronteira. Desses seis, nenhum apresentou caso de aids em 1984. Por
outro lado, nove bairros apresentaram casos em 1983. Considerando-se, da mesma
forma, somente os vizinhos com os quais fazem fronteira, eles expuseram quarenta e
oito bairros.
Desse total, somente seis bairros apresentaram casos em 1984, que
representa o percentual de 12.5%. Cada um dos quarenta e dois bairros restantes
apresentou casos de contaminação após 1984, quando sua exposição era maior do que
no final daquele ano.
Esse é o conceito de limiar. No estudo de marketing, sua
exposição não tinha alcançado o limiar necessário para adotar determinado produto
novo. Nesse estudo, utilizou-se o conceito de limiar para transmitir a idéia de limite de
imunidade, de prevalência da resistência à contaminação.
Os limiares individuais são computados numa rede de difusão depois do fato: são
predições com percepção tardia e, por esse motivo não são muito informativos. É
importante reconhecê-los ou validá-los, o que significa que eles devem ser associados
com outros indicadores como tempo de contaminação.
Assim sendo, os limiares
indicam capacidades de resistência. O limiar mais baixo indica uma resistência menor,
e tempo menor de contaminação.
De fato, uma relação positiva entre tempo de contágio e o limiar individual é
questionável na presente pesquisa, o que pode ser explicado pelo pequeno número de
vértices. Os primeiros bairros afetados pela epidemia não foram expostos a outros
126
bairros contaminados anteriormente. Conseqüentemente, seus limiares são iguais a
zero, por definição. Assim sendo, na rede de bairros, é muito provável que os últimos
estejam conectados a muitos bairros contaminados, conduzindo a valores de exposição e
limiares altos no momento da primeira contaminação. Como a medida do tempo de
contágio
está
restrita
a
um
pequeno
número
de
momentos,
produziu-se,
automaticamente, uma relação entre limiares e tempos de contágio do bairro, conforme
demonstrado na Tabela 7.2 e na Figura 7.15.
Tabela 7.2. Tabela comparativa de limiar médio e freqüência acumulada de bairros com
o primeira notificação de aids no ano, 1982 a 1992, município do Rio de Janeiro.
Ano
1982
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
Limiar médio %Freq acum bai
0.00
0.01
0.00
0.07
0.06
0.16
0.25
0.34
0.35
0.53
0.64
0.75
0.79
0.88
0.80
0.95
0.85
0.98
1.00
0.99
1.00
0.99
1.00
1.00
Figura 7.15 Limiar médio e freqüência acumulada de bairros com o primeira notificação
de aids no ano, 1982 a 1993, município do Rio de Janeiro.
127
Apesar disso, o estudo de limiares e da estrutura da rede, mostrou-se útil para a análise
nos primeiros anos da epidemia.
Consoante com objetivo proposto no início do
capítulo, os resultados da mineração de dados geográficos foram analisados sob o ponto
de vista da estrutura da rede. Assim sendo, comparou-se o conjunto de medidas da rede,
com as taxas de contaminação e outros atributos.
A influência da estrutura da rede no contágio foi mensurada por intermédio das
seguintes variáveis: (i) relevância da distância entre um bairro e todos os outros (ii)
comparação com a proposta do índice de influência espacial, (ii) influência do bairro
conforme seu grau de intermediação (iii) influência da proporção de conexões entre os
bairros vizinhos, medida por intermédio da densidade egocêntrica.
Assim sendo, as notificações de aids foram acumuladas por períodos com o objetivo de
estudar a estrutura formada ao longo do tempo, e medir as variáveis de centralidade,
entre outras. Além disso, com objetivo de mensurar a centralidade lógica, ou seja, a
centralidade medida considerando-se a rede lógica formada pela epidemia, ao invés de
considerar a geografia dos bairros, desenvolveu-se uma rede somente com os bairros
que apresentaram notificações de aids.
Estas redes estão apresentadas nas Figuras 7.18a e 7.18b, e partindo-se dessa estrutura
calcularam-se (i) a distância entre os bairros, medida por intermédio da variável
proximidade da centralidade (ii) o grau de intermediação e (iii) a densidade egocêntrica.
Observou-se que, a centralidade e o limiar do bairro, são correlacionados
negativamente, com coeficiente de variação igual a (-0.18) no período de 1982 a 1987.
O coeficiente variou pouco nos demais períodos. Conseqüentemente, concluiu-se que
quanto maior a centralidade de um bairro, ou seja, quanto menor o somatório das
distâncias do bairro a todos os outros bairros, menor o valor do seu limiar. Essa idéia é
intuitiva, sendo a base da teoria do contágio.
Os bairros mais centrais foram
contaminados mais cedo.
Por outro lado, a correlação entre o limiar e a taxa de contaminação do bairro, no ano
da primeira ocorrência é positiva, com coeficiente de correlação igual a 0.48. Para um
limite de confiança de 95%, e com os dados disponíveis e utilizados, o valor mínimo de
128
correlação, para ser considerado relevante é de 0.27. Esta forte correlação indica que o
bairro que resiste à epidemia, apesar de seus vizinhos contaminados, ao ser atingido,
apresenta um percentual maior de soropositivos no ano da primeira ocorrência, quando
comparados com os bairros com limiar inferior. A Tabela 7.3 apresenta a centralidade
dos bairros com maiores valores de limiar e a taxa da população contaminada, no ano da
primeira ocorrência. O valor médio da taxa no primeiro ano de contaminação é de 0.46.
As medidas de centralidade dos bairros, que foram contaminados no período de 1982 a
1985, estão apresentadas no Anexo F.
Tabela 7.3 Bairros com os maiores valores de limiar e respectiva taxa de contaminação
no ano da primeira ocorrência de aids.
Cronologia
48
71
81
86
92
97
103
114
121
122
123
124
131
134
135
136
137
138
139
142
146
148
150
151
152
Bairro
24
21
13
34
116
98
69
152
45
147
122
85
103
15
105
144
27
109
140
48
82
138
143
123
129
Nome
VIDIGAL
LAGOA
COSME_VELHO
ANDARAI
FREGUESIA
PADRE_MIGUEL
QUINTINO
SAUDE
VIGARIO_GERAL
MARIA_DA_GRAÇA
GALEAO
CURICICA
SENADOR_VASCONCELOS
URCA
COSMOS
PEDRA_DE_GUARATIBA
MANGUEIRA
RIBEIRA
COSTA_BARROS
ROCHA
ANIL
ACARI
BARRA_DE_GUARATIBA
CIDADE_UNIVERSITARIA
JOA
Ano 1a ocorr
1985
1986
1987
1987
1987
1987
1987
1987
1988
1988
1988
1988
1988
1989
1989
1989
1989
1989
1989
1989
1990
1990
1991
1992
1993
Limiar
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
1.000
Taxa
0.969
1.039
2.437
1.067
0.815
0.157
0.319
3.980
0.289
4.153
0.000
0.779
0.332
5.349
0.809
1.080
0.819
3.544
0.400
2.086
1.554
1.122
2.452
4.068
0.000
As Figuras 7.16 e 7.17 apresentam a rede formada pelos bairros com notificações de
aids, no período de 1982 a 1985 e de 1982 a 1987, respectivamente. As conexões
129
indicam a vizinhança geográfica dos bairros. Entretanto, somente os bairros
com
notificações de aids foram conectados.
Figura 7.16 Rede de bairros com ocorrência da epidemia, 1982 a 1985, município do
Rio de Janeiro.
Figura 7.17 Rede de bairros com ocorrência da epidemia, 1982 a 1987, município do
Rio de Janeiro.
130
A Figura 7.18 indica a relação entre a centralidade dos bairros e a epidemia. Os
vértices vermelhos são os mais centrais e o tamanho do vértice é a taxa de contaminação
pelo vírus HIV. Os bairros com vértice vermelho, ou seja, mais centrais, apresentaram
as maiores taxas no período seguinte.
Figura 7.18 Rede de bairros, 1982 a 1987, município do Rio de Janeiro.
O mapa com os valores de intermediação, ou seja, fazem parte do caminho entre dois
outros vértices, também expressam a importância do atributo na proliferação da rede,
conforme apresentado nas Figuras 7.19 e 7.20.
Figura 7.19 Medida de intermediação da rede de bairros contaminados representada
pelo tamanho do vértice, 1982 a 1985, município do Rio de Janeiro.
131
Figura 7.20 Medida de intermediação da rede de bairros contaminados representada
pelo tamanho do vértice, 1982 a 1987, município do Rio de Janeiro.
Os vértices com maiores valores de intermediação na zona norte da cidade,
apresentaram taxas elevadas no período seguinte analisado, conforme demonstrado na
Figura 7.21. O tamanho do vértice representa a medida de centralidade e a cor do
vértice a taxa de contaminação do bairro em 1992. A cor cinza representa valores
médios. Em 1987, os bairros da zona norte apresentaram taxas no primeiro quartil.
Figura 7.21 Medida de intermediação da rede de bairros contaminados (tamanho do
vértice) e a taxa de contaminação do período seguinte 1992 (cor), 1982 a 1987,
município do Rio de Janeiro.
132
7.5.1.3 Relação entre a Densidade e o Tempo de Difusão
A Figura 7.22 apresenta os valores de limiares por bairro, de 1982 a 1996, ano que o
último bairro foi atingido pela epidemia. Os menores valores são apresentados por
amarelo e os maiores valores por azul.
Figura 7.22 Valor de limiar por vértice da rede de bairros, município do Rio de Janeiro.
Confirmou-se que quando a densidade cresce o limiar diminui na maioria das
ocorrências. O valor de limiar médio dos bairros da zona sul, assim como do centro da
cidade são inferiores ao da zona oeste e de parte da zona norte. Os valores de limiar são
correlacionados positivamente à área do bairro, o que conduz a hipótese que a densidade
geográfica está diretamente relacionada ao tempo de difusão da epidemia.
Os atributos de bairros considerados relevantes e utilizados nas tarefas de mineração de
dados também foram analisados segundo a abordagem de redes complexas. O
coeficiente de correlação entre esses atributos e as medidas da estrutura da rede de
bairros, não indicaram correlação significativa. Há uma pequena correlação negativa
com índices econômico-sociais. A correlação com o atributo categoria de exposição é
negativo em todas as classes (homo, bissexual, etc), na faixa de (-0.28 a -0.38).
Identificou-se uma correlação significativa negativa entre categoria homossexual e
133
limiar no período de 1982 a 1985. Por outro lado, a proporção razão de sexos é
positivamente correlacionada, explicado pela baixa contaminação de mulheres no
período analisada, de 1982 a 1993, primeira década da epidemia.
7.5.2 Segundo Objetivo: Definição da Massa Crítica
Alguns processos de difusão têm sucesso porque quase todos no grupo alvo são
contaminados. No município do Rio de Janeiro, cinqüenta e hum por cento dos bairros
foram contaminados até 1986, ou seja, num período de cinco anos. A disseminação de
uma doença contagiosa tem um limite crítico: uma vez ultrapassado, multiplica-se
rapidamente. A identificação desse limite crítico e importante para a prevenção ou
somente para histórico, no caso de eventos similares no futuro.
Esse limite é denominado massa crítica de um processo de difusão e é definido como o
número mínimo de atores que impedem a erradicação da contaminação. A massa crítica
de um processo de difusão particular é difícil de ser identificada.
Usualmente,
considera-se uma regra prática empírica sobre processos de difusão. A regra afirma que
em um fenômeno particular quando a contaminação atinge vinte por cento de todas as
pessoas (no caso estudado, são os bairros da rede), a aceleração da taxa de
contaminação diminui, embora a taxa de contaminação ainda aumente em números
absolutos. Isto é conhecido como o primeiro ponto de inflexão de segunda ordem da
curva S.
Na rede de bairros, por exemplo, o número de vértices contaminados cresceu de um
bairro para nove de 1982 para 1983. Em 1986 a aceleração caiu para dois porque o
número de novos bairros cresceu somente de vinte seis para vinte e oito; o número de
novos bairros ainda aumentou, entretanto menos agudamente. Verificou-se que o ano
de 1985 apresentou a maior aceleração da taxa de contaminação e que, dezessete por
cento de todos os bairros foram contaminados.
Devido a esta relação empírica entre o primeiro ponto de inflexão de segunda ordem da
curva de difusão e a disseminação final de uma contaminação, os analistas de difusão
afirmam que a massa crítica é atingida quando a curva de difusão alcança este ponto de
inflexão. Segundo essa abordagem, o processo de difusão no qual a taxa de
134
contaminação acelera inicialmente e depois declina é conduzido pela reação em cadeia
característica de modelos de contágio. Presume-se que o contágio toma conta do
processo de difusão neste ponto, e que o processo atingiu sua massa crítica.
Nesse
caso, processo de difusão da aids teria atingido sua massa critica no final de 1985.
Um argumento similar existe para o ponto de inflexão de primeira ordem da curva de
difusão logística, que é o período com a taxa de adoção mais alta, isto é, o maior
aumento absoluto de novos bairros. Habitualmente o ponto de inflexão de primeira
ordem ocorre quando aproximadamente cinqüenta por cento de todos os atores foram
contaminados. Na rede de bairros, a taxa de adoção maior foi onze e foi realizada entre
1985 e 1986 atingindo cinqüenta e um por cento da rede.
Entretanto, essa abordagem pressupõe a relação entre contágio e massa crítica; não
prova que exista a massa crítica, apenas a assume. Todavia, é útil por motivos práticos.
Podemos monitorar o processo de difusão e vigiar para determinar o momento em que
ocorre o primeiro declínio do crescimento da aceleração (os declínios acidentais devem
ser ignorados). Nesse momento, é possível estimar o número final de bairros a serem
contaminados como cerca de cinco a dez vezes o número de bairros no momento de
maior crescimento porque entre 10 e 20 por cento já adotaram. Entretanto, essa é uma
simples regra prática.
Em outra perspectiva, assume-se que um processo de difusão atinge sua massa crítica
quando os vértices mais centrais são contaminados. Uma vez contaminados, tantos
atores na rede passam a ser expostos que muitos limiares individuais são alcançados,
conduzindo a uma avalanche de contaminações. O valor denominado intermediação,
do inglês between-centrality, parece estar associado com a massa crítica. Geralmente a
posição dos primeiros contaminados na rede é relevante para o processo de difusão. Se
os primeiros adotantes são centrais e conectados diretamente, seus vizinhos têm maiores
taxas de exposição e mais risco de contaminação.
A massa crítica traz uma mudança qualitativa do sistema traduzida num decréscimo
repentino dos limiares individuais.
Durante o processo de difusão, os limiares
individuais podem decrescer como uma conseqüência da taxa de contaminação no
135
sistema total (menor resistência geral). Baixos limiares indicam maior vulnerabilidade à
contaminação, de forma que o processo de difusão se fortalece.
Um retardo de limiar é um período no qual um ator não é contaminado ainda que ele
esteja exposto ao mesmo nível em que ele será contaminado mais tarde. A diminuição
dos limiares quando a massa crítica é alcançada no processo de difusão pode explicar a
ocorrência de retardo de limiar, que é um período em que a exposição alcançou o limiar
individual, porém o indivíduo (vértice) não se contaminou. Neste caso, a adoção ocorre
depois de que a massa crítica é alcançada e o limiar do indivíduo decresce.
Esta abordagem de limiares e de retardos de limiar não prova que os vértices da rede
tenham limiares ou retardos de limiar, apenas os define numa forma particular. Numa
rede de difusão empírica, sempre é possível computar a exposição de um ator no
momento da contaminação (limiar) e por quanto tempo este ator precisou estar exposto
a esse nível antes de adotar (retardo de limiar). Segundo NOOY et. al. (2005) isto não
descarta a possibilidade de que o limiar do indivíduo fosse realmente mais baixo e seu
retardo de limiar mais longo.
7.6 Resultados Obtidos
Através da análise da rede, os seguintes resultados foram identificados:
A aids, assim como as doenças infecciosas, difundem-se numa forma particular
que é representada pela curva em S, curva típica de difusão. No começo, poucos
atores são contaminados e a taxa de contaminação se acelera.
Comprovou-se
essa característica na epidemia pelo vírus HIV.
Na sub-rede (parte da rede de bairros) mais densa a epidemia ocorreu mais
rapidamente do que na sub-rede que apresenta buracos estruturais.
Da mesma forma, na sub- rede com poucas conexões, ou seja, com valor de grau
médio baixo, a difusão foi mais lenta.
136
Quanto maior a vizinhança de um nó da rede, mais rapidamente ele foi
infectado.
A centralidade geográfica não apresentou correlação significativa com a
proliferação da epidemia. Entretanto, a análise da centralidade considerando-se a
rede formada somente pelos bairros com ocorrências de aids, conforme as fases
de proliferação, evidenciou a forte correlação das medidas de centralidade da
rede com a proliferação.
Observou-se uma correlação negativa entre a da área do bairro (medida em
quilômetros quadrados) é o tempo de contaminação.
A Aids atingiu sua massa critica no ano de 1985.
Confirmou-se que a expansão da epidemia se deu no sentido zona sul, centro e
zona norte, conforme análise da rede formada por bairros por período de tempo.
Confirmou-se uma prevalência de pessoas com vírus HIV pertencentes a classes sociais
com menor poder aquisitivo, confirmadas pelos índices econômico-sociais (IBGE) dos
bairros. Entretanto, unidades hospitalares de saúde pública atendem primordialmente a
esse grupo social. Assim sendo, existem, provavelmente, pacientes soropositivos que,
quando atendidos por hospitais privados, nem sempre registram a notificação
compulsória.
7.7 Resumo
As doenças infecciosas difundem-se numa forma particular que é representada pela
curva em S, curva típica de difusão. No começo, poucos atores são contaminados e a
taxa de contaminação se acelera. Quando dez a vinte por cento dos atores são
contaminados, a aceleração estabiliza-se enquanto o número absoluto de novos casos
está ainda aumentando, ocasionando um aumento brusco do número total de
contaminados. Finalmente o número de casos novos diminui e o processo de difusão
termina, com estabilização das taxas.
137
Este modelo de crescimento é típico de uma reação em cadeia causada por contágio. Os
modelos de rede se aproximam da difusão como um processo de contágio no qual os
vértices da rede expõem seus contatos à contaminação. Uma vez que a exposição atinge
seus limiares, que depende de atributos do vértice e das características da infecção, eles
serão contaminados e começarão a infectar outros. Como conseqüência, a estrutura da
rede e as posições dos primeiros contaminados da rede, influenciam a taxa de
proliferação. Este é um mecanismo muito provável. Entretanto, é difícil provar que a
difusão realmente funciona assim.
Num determinado momento, um processo de difusão bem-sucedido hipoteticamente
alcança uma massa crítica, o que significa que o processo de difusão pode se sustentar.
Mesmo com percepção tardia, é difícil localizar o momento quando se alcança a massa
crítica.
Entretanto, conforme uma regra prática empírica isto acontece quando
a
contaminação atinge dez a vinte por cento dos atores que eventualmente poderão ser
contaminados.
No estudo realizado, concluiu-se que a massa critica foi formada,
principalmente, pelo grupo de homossexuais e bissexuais, em 1985. Este é o primeiro
ponto de inflexão de segunda ordem da curva de difusão em forma de S: o momento no
qual a taxa de contaminação não se acelera mais,
porém a população ainda está
crescendo.
Alternativamente, a massa crítica pode ser associada ao momento em que os atores mais
centrais são contaminados ou quando, relativamente, muitos atores foram contaminados
embora suas exposições não estejam aumentando. No último caso, a teoria é que a
massa crítica ou fatores externos diminuem os limiares individuais. Pesquisas em curso
sobre difusão de contaminação devem esclarecer esta questão. Entretanto, o conceito
oferece algumas ferramentas práticas para monitorar e guiar o processo de difusão.
138
CAPÍTULO 8
PROPOSTA DE MEDIDA DE INTERAÇÃO ESPACIAL
8.1 Introdução
Este capítulo propõe-se a apresentar uma proposta para identificar o movimento dos
pacientes entre bairros, por intermédio de um critério de interação espacial com base no
total de ocorrências comuns ao par formado pelo bairro e pela unidade hospitalar.
O problema de interação espacial que trata de N locais distintos e P pessoas deve
considerar N x N x P interações em um determinado tempo t. Ao considerar-se a
dinâmica das interações na dimensão espaço-tempo, a matriz de interações passa a ter o
tamanho de N x N x P x T, onde T é a unidade de tempo considerada.
No presente
estudo, como é usual, a informação sobre a rotina de deslocamento dos pacientes entre
local de trabalho ou estudo e moradia, entre outros, não estava disponível.
O capítulo divide-se nos seguintes tópicos: 2. Objetivo; 3. Sistemas; Software e Dados;
4. Medida de Interação Espacial; 5. Resultados Obtidos; e 6. Resumo.
8.2 Objetivo
Com o objetivo de tentar identificar padrões de deslocamento, considerou-se a unidade
hospitalar de saúde onde o diagnóstico de aids foi realizado, como elemento de conexão
entre bairros. Usualmente, utiliza-se a unidade hospitalar próxima ao local de trabalho
ou próxima a algum local que faça parte da rotina de deslocamento do paciente. Assim
sendo, analisou-se a interação entre o bairro de residência do paciente e a unidade de
saúde onde o diagnóstico de contaminação foi realizado, como tentativa de identificar
padrões de deslocamento dos pacientes entre bairros.
Os bairros são conectados por
uma unidade de saúde. Para mensurar a interação entre duas localidades, considerou-se
o fluxo de pessoas, ou seja, o valor absoluto das conexões entre o bairro e a unidade de
saúde. Considerou-se também uma medida relativa, que usa os valores percentuais de
pacientes do bairro e da unidade.
139
8.3 Sistemas, Software e Dados
Utilizou-se o software NetDraw (2008) para visualização dos resultados. Mais uma vez,
utilizou-se a base de dados do Sistema Nacional de Notificações (SINAN), de 1982 a
2005.
8.4 Medida de Interação Espacial
Um paciente soropositivo, que reside em um bairro do município, pode realizar teste de
infecção pelo HIV em distintas unidades hospitalares de saúde. O estudo comprovou
que, regra geral, o teste é realizado em uma única unidade hospitalar. Uma unidade
hospitalar, por outro lado, é responsável pelo teste de inúmeros pacientes. Métodos de
análise de relacionamento, usualmente concentram os cálculos na pessoa ou no local,
com objetivo de examinar o grau de distribuição de cada conexão do par formado por
local-pessoa.
O relacionamento entre locais e pessoas é usualmente representado por
gráficos denominados Bipartite, como o da Figura 8.1.
Considerou-se que dois bairros são conectados, quando os mesmos compartilham pelo
menos um diagnóstico realizado por um paciente do respectivo bairro, na mesma
unidade hospitalar, no período de tempo considerado.
Unidade
Bairro
Figura 8.1 Gráfico Bipartite, de interação entre bairro-unidade, sem considerar o tempo.
Dois bairros estão conectados, se possuem pelo menos um diagnóstico realizado em
unidade de saúde comum, na unidade de medida de tempo considerada.
140
8.4.1 Cálculo da Interação Espacial
A força da interação espacial entre dois locais, como bairro e a unidade hospitalar de
saúde, pode ser medida pela quantidade de pacientes compartilhados, pela distância
geográfica ou por outra medida de interação espacial.
Utilizou-se uma medida de
interação espacial (IE), que considera o total de pacientes compartilhados por dois
locais: unidade e bairro ou entre dois bairros. As notificações de aids foram totalizadas
por mês e bairro, obtendo-se o total de ocorrências de cada local, assim como o total
compartilhado por cada par bairro-unidade.
Calculou-se a medida de interação espacial dos pares compostos por bairro e unidade,
considerando-se o total de pacientes compartilhados, ou seja, o total de pacientes que
residem no bairro x com diagnóstico realizado na unidade y, conforme Equação 8.1.
IE
Pc x, y
2
Px Py
Equação 8.1 Medida de interação espacial
Onde:
IE (x,y) medida de interação espacial;
Pc (x,y) quadrado do total de soropositivos que residem no bairro x e com diagnóstico
realizado na unidade y, no período de tempo considerado;
Px total de soropositivos que residem no bairro x, no período de tempo considerado.
Py total de soropositivos que realizaram o diagnóstico na unidade y, no período de
tempo considerado.
8.5 Resultados obtidos
Inicialmente, analisou-se a distribuição dos pares de bairro e unidade, com relação ao
total de pacientes compartilhados, conforme Figura 8.2.
O princípio de potência
constante pode ser observado no gráfico, indicando que a rede de interação espacial
pode ser muito reduzida e simplificada se os pares com pequeno número de pacientes
compartilhados entre bairro e unidade forem desconsiderados. A Figura 8.3 apresenta a
141
relação entre o total de pacientes compartilhados e a distância média entre os locais que
compartilham esses pacientes. Conforme esperado, os pares que compartilham poucos
pacientes são em geral, mais distantes. De forma contrária, os pares que compartilham
muitos pacientes, tendem a ser mais próximos com distância média variando de cinco a
quinze mil metros.
Mais uma vez, observou-se o principio da potência constante,
confirmando-se que o cálculo da interação espacial pode ser baseado no total de
pacientes compartilhados entre bairro e unidade ou entre bairros. Na Figura 8.4, o valor
absoluto do total de pacientes compartilhados, foi substituído pela medida de interação
espacial.
1000
100
10
1
1
10
100
1000
10000
Figura 8.2 Total de pares bairro-unidade (eixo y) que compartilham exatamente Pc
pacientes (eixo x).
15000
10000
5000
0
0
100
200
300
400
500
600
700
800
Figura 8.3 Distância média dos pares (eixo y) que compartilham Pc pacientes (eixo x).
142
0.02
0.01
0
1
10
100
1000
Figura 8.4 Medida de Interação Espacial – IE (eixo y) que compartilham Pc pacientes
(eixo x).
Calculou-se a medida de interação espacial dos pares formados por bairro e unidade
hospitalar, ou seja, o total de pacientes que residem no bairro x com diagnóstico
realizado na unidade y, conforme equação 8.1.
Considerou-se que o bairro x e a unidade y interagem quando os mesmos apresentam
pelo menos um diagnóstico realizado na mesma unidade, no período de um semestre. O
grau de interação depende do total de casos do bairro e da unidade. Desta forma, sendo
P(x) o total de pacientes que residem no bairro x, P(y) o total de pacientes com
diagnóstico realizado na unidade y e Pc (x,y) o total de pacientes compartilhados por x e
y, a interação espacial calcula o percentual de casos comuns, no período de tempo
considerado.
Em seguida, realizou-se o agrupamento dos pares de bairros e unidades, com o objetivo
de identificar padrões.
Métodos de agrupamento de dados baseado em gráficos
poderiam ser utilizados.
Entretanto, no presente estudo, utilizou-se um método mais
simples e com menor custo de processamento. Conforme a análise realizada (Figura
8.2), ao se desconsiderar os pares com pequeno número de pacientes compartilhados,
obteve-se um conjunto muito menor, facilitando a segmentação dos pares utilizados nas
tarefas de mineração de dados.
dados em duas fases.
A partir dessa análise, realizou-se o agrupamento de
Na primeira fase removeu-se o total de pares com valor de
interação espacial inferior a 0.03. O valor foi obtido com análise estatística padrão,
sendo 0.03 o valor da média.
O resultado para os anos de 1985 e 1988 estão
apresentados nas Figuras 8.5a e 8.5b, onde as cores dos nós da rede indicam a região do
município onde o bairro está localizado.
143
Na segunda fase, realizou-se um agrupamento de dados hierárquico com o conjunto
menor de pares, resultantes dessa simplificação.
Para facilitar a identificação de
padrões, as unidades de saúde foram ordenadas de tal forma que os bairros com
maiores valores de IE, em relação à determinada unidade, fossem posicionados mais
próximos, reduzindo-se dessa forma a interseção de curvas na Figura 8.6.
Com as
unidades de saúde posicionadas no eixo vertical e o tempo no eixo horizontal, foi
possível visualizar a variação da interação bairro-unidade no tempo.
Para a análise de epidemias, em que os dados sobre a movimentação das pessoas
infectadas estivessem disponíveis, o gráfico proposto na Figura 8.6 permitiria identificar
os locais visitados e, conseqüentemente, com risco de contaminação. Verificou-se que
a distribuição de bairros entre as unidades de saúde, foi constante no tempo, para a
maioria dos bairros, com pequenas variações sazonais (Figura 8.6). Além disso,
conforme esperado, a distribuição de bairros por unidades prioriza o espaço geográfico,
como pode ser observado na Figura 8.5a. A unidade hospitalar de saúde com o maior
valor de interação espacial por bairro está representada no mapa temático da Figura 8.7.
Cada tonalidade de cinza representa uma unidade de saúde distinta, observando-se desta
forma, a existência de um padrão por região espacial.
Esse conhecimento é novo,
apesar de esperado. Não existe estudo baseado na interação bairro-unidade conforme
proposto. Atualmente, há somente a idéia de distribuição de freqüência em municípios
do estado. Outro conhecimento importante é a formação dos agrupamentos de bairros
unidos pela unidade hospitalar.
Esse conhecimento, uma vez aprofundado, pode
identificar padrões de movimento e de deslocamento, como pares formados por bairro
de residência e bairro de local de trabalho. Através desse estudo, ainda não foi possível
afirmar que existem padrões de deslocamento entre os bairros unidos pela unidade
hospitalar. Entretanto, o conhecimento destes grupos de bairros é de grande utilidade e
deve ser aprofundado.
144
Figura 8.5a Rede de bairros e unidades hospitalares, 1985, município do Rio de Janeiro,
visualização com NetDraw.
Figura 8.5b Rede de
bairros e unidades hospitalares, 1988, município do Rio de
Janeiro, visualização com NetDraw.
145
14000
14000
12000
11738
Unidade de Saúde
12000
10000
7943
8000
7439
10000
7323
FLAMENGO
LARANJEIRAS
6000
4000
8000
GLORIA
CATETE
BOTAFOGO
2000
2005
2003
2001
1999
1997
1995
1993
1991
1989
1987
0
1985
6000
Figura 8.6 Total de interações entre bairros (lista parcial) e respectivas unidades
hospitalares de saúde, 1985 a 2005, município do Rio de Janeiro.
Figura 8.7 Unidade de saúde mais utilizada por bairro, a tonalidade cinza representa
uma unidade hospitalar, 1982 a 2005, município do Rio de Janeiro.
8.6 Resumo
A análise do movimento dos pacientes entre bairros e unidades hospitalares de saúde
contribuiu para a compreensão da epidemia.
Observou-se o princípio de potência
constante na distribuição de casos de aids entre bairros e unidades hospitalares de saúde,
146
deduzindo-se que a rede de interação espacial poderia ser muito reduzida e simplificada
se os pares com pequeno número de pacientes compartilhados entre bairro e unidade
fossem desconsiderados.
Definiu-se o critério de interação baseado no total de ocorrências comuns ao bairro e a
unidade hospitalar, em uma unidade de tempo. A análise indicou uma forte correlação
entre bairro-unidade e espaço geográfico, conforme esperado. O total de pacientes
compartilhados entre bairro e unidade hospitalar correlaciona-se a distância geográfica.
Além disso, observou-se que a unidade hospitalar de saúde mais utilizada por bairro
permaneceu constante nos últimos períodos da epidemia, na maioria dos bairros.
A visualização proposta auxilia a interpretação dos resultados. Essa informação pode ser
útil. Supondo-se que determinado bairro apresente uma redução brusca de casos da
epidemia, indicando uma anomalia ou erro, poder-se-ia pesquisar diretamente a unidade
de saúde que historicamente atende o bairro, em busca de possíveis falhas nos
diagnósticos. O estudo se propõe ainda a auxiliar o redirecionamento de pacientes em
caso de desativação de uma unidade hospitalar.
Na maioria dos casos a relação entre bairro e unidade hospitalar é definida pela
distância entre a unidade e bairro de residência. O mesmo critério pode ser considerado
para relacionar bairros através de outra entidade, diferente da unidade hospitalar.
Outra aplicação do modelo refere-se aos casos de infecção por contágio, nos quais a
informação sobre o deslocamento das pessoas infectadas estivesse disponível. Nesse
caso, os pares de bairros e unidades seriam substituídos por pares de locais visitados
pela pessoa infectada. A análise da Figura 8.6 permitiria identificar rapidamente os
locais visitados pelas pessoas infectadas e, conseqüentemente os locais com maior
probabilidade de contaminação.
Entretanto, conforme já mencionado, dados sobre o deslocamento de pessoas são muito
raros e usualmente são gerados por simulação, para fins de pesquisa. Apesar disso, a
disponibilidade desse tipo de informação cresce a cada dia, através de GPS utilizados
em carros e celulares, levando-nos a supor que esse tipo de estudo será útil, na prática,
no futuro breve.
147
CAPÍTULO 9
CONSIDERAÇÕES FINAIS
9.1 Conclusões
A descoberta de conhecimento em bases de dados deve ser conceituada como a busca
por padrões que propiciem o desenvolvimento ou competitividade de uma empresa. O
aumento da competitividade ocorre devido à informação adquirida que auxiliará na
identificação de riscos e oportunidades e no conhecimento dos pontos fortes e fracos do
negócio. Na área de saúde, a competitividade poderia ser medida através da redução das
taxas de mortalidade e morbidade.
A definição estática da OMS que definia a saúde como o estado de completo bem estar,
foi superada. Nas definições atuais ela é dependente da dinâmica social e de políticas
econômicas e culturais. Assim sendo, os níveis de padrão sanitário dependem muito
mais de políticas econômicas, sociais e de aspectos culturais do que da intervenção da
medicina propriamente dita.
Por esse motivo, buscou-se novas formas de estudar
saúde.
A Mineração de Dados geográficos integrada a Redes Complexas introduz novos
desafios e problemas. A necessidade crescente de técnicas de mineração de dados
específicas para dados espaciais é explicada pela disponibilidade de dados de satélites e
de mapas urbanos digitais de cidades, além da ampliação da coleta de dados com uso de
sistemas GPS (Global Positioning Systems). O desenvolvimento de tecnologias
possibilita armazenar grandes volumes de dados. No entanto, a capacidade de analisar
estes dados, transformando-os em conhecimento útil é muito inferior à capacidade de
produção e armazenamento.
A pesquisa foi dividida em três grandes partes. A primeira composta pela proposta do
Índice de influência espacial. Na segunda parte, o Indice foi utilizado e agrupamentos
de dados usando Mapas Auto-Organizáveis de Kohonen foram realizadas, com o
objetivo de compreender os relacionamentos entre bairros e pacientes e, principalmente,
entender os vetores da epidemia.
Nessa fase, as variáveis relevantes foram
148
identificadas. As informações obtidas foram utilizadas na modelagem espaço-temporal e
na predição de óbitos. Na terceira e última parte, a epidemia foi analisada com a
abordagem de redes sociais, buscando-se padrões na estrutura da rede formada, que
pudessem auxiliar no conhecimento da epidemia.
A mineração de dados espaciais prescinde da definição de um critério de proximidade.
Esse conceito é fundamental para a valoração de dependência espacial. Dependência
espacial é o impacto que a variação na localização espacial causa na variação dos
atributos, ou seja, é a medida de como os atributos são dependentes do espaço
geográfico. Apresentou-se uma proposta de Índice de influência espacial, que cria um
conceito de vizinhança através das características de relacionamento espacial de
distância e direção entre objetos. Com a proposta do IF, a primeira parte da pesquisa foi
concluída.
Na segunda parte, através do agrupamento dos bairros por ano da primeira ocorrência,
identificou-se que a contaminação partiu da zona sul para a Leopoldina e zona norte. A
redução do nível de escolaridade e dos índices econômicos pode ser associada ao
movimento em direção aos bairros da zona norte e oeste da cidade, considerando-se os
índices sócio-econômicos do IBGE. Apesar disso, os bairros mais críticos,
considerando-se todo o período, ainda são os do Centro, Copacabana e Tijuca.
O crescimento da contaminação em mulheres coincidiu com a redução do nível de
escolaridade e com o empobrecimento. Não foi possível identificar uma divisão de
bairros por categoria de exposição (homossexual, bissexual, entre outras categorias).
Entretanto, observou-se, de forma brusca, o crescimento de contaminação em mulheres
e empobrecimento da população.
Esses padrões identificados são novos, pois não há
estudo similar com dados do município do Rio de Janeiro. Esses padrões serviram de
entrada para a terceira parte da pesquisa.
Ainda na segunda parte, identificaram-se as fases distintas da epidemia, usando o índice
de influência espacial proposto com o objetivo de identificar o movimento da epidemia.
Através do cálculo do IF por direção, identificou-se o movimento da disseminação a
partir do Centro na direção norte Essa interpretação não é automática. Entretanto, uma
vez identificado o IFd relevante por período de tempo definido, o movimento do
149
fenômeno estudado pode ser compreendido. Prevaleceram as direções partindo-se de
Copacabana e Centro sentido norte, Leste-Oeste e norte.
A análise de séries temporais da epidemia, com a predição da epidemia no tempo e no
espaço obteve, como melhor resultado, a identificação de padrões que, com em conjunto
com as devidas ações preventivas, podem reduzir o total de óbitos. É o caso da
identificação da forte correlação dos óbitos com os casos identificados pela contagem de
linfócitos CD4 inferior a 350 mm, conforme apresentado no capítulo seis. Nesse ponto
a segunda parte da pesquisa foi concluída.
Em seguida, verificou-se que a epidemia da AIDS apresenta um modelo de crescimento
típico de uma reação em cadeia causada por contágio. Os modelos de rede se
aproximam da difusão como um processo de contágio no qual os vértices da rede
expõem seus contatos à contaminação. No momento que um vértice da rede atinge seu
limiar, que depende de atributos do vértice e das características da infecção, ele será
contaminados e iniciará o processo de contaminação de outros vértices. Como
conseqüência, a estrutura da rede e as posições dos primeiros contaminados da rede,
influenciam a taxa de proliferação. Entretanto, apesar de muito provável, segundo
NOOY et. al (2005) é difícil provar que a difusão realmente funciona assim.
Num determinado momento, um processo de difusão bem-sucedido, hipoteticamente
alcança uma massa crítica, o que significa que o processo de difusão pode se sustentar.
Mesmo com percepção tardia, é difícil localizar o momento quando se alcança a massa
crítica.
Entretanto, conforme uma regra prática empírica isto acontece quando
a
contaminação atinge dez a vinte por cento dos atores que eventualmente poderão ser
contaminados. No estudo realizado, conforme esse critério, concluiu-se que a massa
critica foi formada, principalmente, pelo grupo de homossexuais e bissexuais, em 1985.
Em seguida, com base na informação de agrupamentos de dados que identificou os
grupos de bairros mais relacionados, identificou a necessidade de conhecer a interação
entre bairro e unidade hospitalar. A análise do movimento dos pacientes entre bairros e
unidades hospitalares contribuiu para a compreensão da epidemia. Definiu-se o critério
de interação baseado no total de ocorrências do bairro e da unidade. A análise indicou
uma forte correlação entre bairro-unidade e espaço geográfico, conforme esperado. O
150
total de pacientes compartilhados entre bairro e unidade de saúde, assim como entre
bairros que utilizam a mesma unidade de saúde é diretamente relacionado à distância
geográfica. Além disso, observou-se que a unidade de saúde mais utilizada por bairro é
constante nos últimos períodos da epidemia, na maioria dos bairros.
Usualmente, os mecanismos de difusão de epidemias reproduzem a estrutura social da
cidade, pressupondo-se nesse caso, a interação entre semelhantes. De forma contrária,
identificou-se que a AIDS teve início com homens pertencentes a grupos com maior
renda e escolaridade, atingindo, em seguida, homens e mulheres de áreas periféricas da
cidade. A taxa de crescimento das mulheres é maior que dos homens. Entretanto, os
homens ainda são maioria em valores absolutos.
O cenário da epidemia mudou nos últimos anos. Percebe-se, claramente um binômio
formado por homens da zonal sul e centro e mulheres da zona norte. Não foi possível
explicar como ocorre a formação desse relacionamento. Uma das explicações é que
apesar de ser sexualmente transmissível, a epidemia da aids encontra explicação para
sua expansão nas condições econômico-sociais da população. A redução e erradicação
da epidemia não podem depender do controle de um setor ou tecnologia. Ao tentar
reduzir os números da epidemia, através de campanhas sociais, muitas vezes conforme
padrões dos países mais desenvolvidos, a desigualdade permanece. Não se consegue
superar a condição dos bairros periféricos que, conforme o estudo, são os mais
atingidos.
Mais uma vez, comprovou-se que é necessário preparar condições que
permitam romper a dependência econômica.
Esse estudo buscou entender as muitas traduções do desenvolvimento da epidemia pelo
vírus HIV. A mais expressiva tradução, operada pelos atores dessa rede complexa, foi a
necessidade de ações mais ofensivas ao combate, tratando desigualmente os bairros do
município. O estudo foi uma tentativa de provar que ações específicas com foco nas
regiões com as maiores taxas de contaminação podem criar condições para melhoria em
relação aos índices atuais de contaminação da população do município do Rio de
Janeiro.
151
9.2 Trabalhos Futuros
Uma sugestão para continuação desse trabalho é considerar a relação topológica entre
os objetos espaciais, no cálculo do índice de influência espacial. Nesse caso, além da
distância e direção, a relação topológica também seria considerada no cálculo.
Exemplos de relações topológicas são: A contêm B, A está dentro de B, A intercepta B,
entre outras. A inclusão da relação topológica seria especialmente útil em tarefas de
mineração espacial que utilizam polígonos que contem e interceptam ruas, escolas, rios
e hospitais, sendo uma das sugestões de continuidade desse trabalho. Esse, de fato, era
o objetivo inicial da pesquisa. Entretanto, apesar de inúmeras solicitações dos mapas do
município ao Instituto Pereira Passos, sem sucesso, o objetivo foi modificado.
Outra sugestão é desenvolver uma ferramenta para detecção automática de
agrupamentos resultantes do Mapa Auto-Organizável e a respectiva visualização de
resultados.
Finalmente, a principal sugestão para pesquisa futura é o desenvolvimento de uma
ferramenta que realize tarefas de mineração de dados usando diretamente como entrada
mapas geográficos.
152
REFERÊNCIAS BIBLIOGRÁFICAS
AGRAWAL,R., 1994, “Tutorial on database mining”, Thirteenth ACM Symposium on
Principles of Database Systems. MN: pp. 75-6, Mineapolis.
AGRAWAL, R., MANNILA, H., SRINKANT, R., TOIVONEN, H. e VERKANO, A.
I, 1996, “Fast discovery of association rules”, In: FAYYAD, U.M., PIATETSKYSHAPIRO, G., SMYTH, P. e ULTHURUSAMY, R. (eds), Advances in Knowledge
Discovery and Data Mining. Cambridge, MA: MIT Press, pp. 307-328.
ANSELIN, L., 2005, GeoDa 0.9 User's Guide, Spatial Analysis Laboratory,
Department of Agricultural and Consumer Economics and CSISS, University of
Illinois, Urbana, IL.
ASIMOV, D. 1985, “The grand tour: a tool for viewing multidimensional data”, SIAM
Journal of Science and Statistical Computing 6: pp. 28-143.
BARABÁSI, A. How Everything Is Connected to Everything Else, 2002, ISBN: 0-45228439-2.
BERTIN, J., 1985, Graphical Semiology. Madison, Wisconsin, USA: University of
Wiscosin Press.
BLOOMFIELD, P., 1976, Fourier Analysis of Time Series: An Introduction, New York:
Wiley.
BREIMAN, L., FRIEDMAN, J.H., OLSHEN, R.A e STONE C.J., 1984, Classification
and regression trees. Belmont. CA: Wadsworth.
153
CAI, Y. CERCONE, N. e HAN, J., 1991, “Atribbute-oriented induction in relational
databases”, In: Piatesky-Shapiro, G. E Frawley, W. J. (eds) Knowledge Discovery in
Databases. AAAI Press, pp. 213-8.
CALINSKI, T. e HARABASZ, J., 1974, "A Dendrite Method for Cluster Analysis",
[online], http://www.informaworld.com/, dez/2006.
CALOBA, L. P. , 2002, “Introdução ao Uso de Redes Neurais na Modelagem de
Sistemas Dinâmicos e Séries Temporais”, Livro de Minicursos do XIV Congresso
Brasileiro de Automática, Natal.
CÂMARA, G., 1996, "SPRING: Integrating remote sensing and GIS by object-oriented
data modelling", Garrido J Computers & Graphics, 20: (3) 395-403, May-Jun 1996.
CASANOVA, M.A., CAMARA, G., DAVIS, J., CLODOVEU A., VINHAS L.,
QUEIROZ, G.R., Bancos de Dados Geográficos, Editora MundoGeo, 2005.
CHATFIELD, C., The Analysis of Time Series, Chapman and Hall Ltd, London, 1989.
CHERNOFF, H., 1973, “The use of faces to represent points in k-dimensional space
graphically”, Journal of American Statistical Association, 68: pp. 361-36.
CHERNOFF, H., 1978, “Graphical representations as a discipline”, In: Wang, P.C.C
(ed) Graphical Representations of Multivariate Data, New York, USA: Academic
Press, 1978.
COOLEY, J.W. e TUKEY, J. W., 1965, "An algorithm for the machine calculation of
complex Fourier series," Math. Comput. 19, 297–301.
COOLEY, J.W., LEWIS, P.A.W. e WELCH, P.D., 1967,” Historical notes on the fast
Fourier transform”, IEEE Trans., AU-15,no. 2,76-9.
154
DAVIES, D. L. e BOULDIN, D. W., 1979, “A cluster separation measure”, IEEE
Transactions on Pattern Analysis and Machine Intelligence, v. PAMI-1, p. 224–227.
DRUCK S., CARVALHO, M.S., CÂMARA G., MONTEIRO, A.M.V., Análise
Espacial de Dados Geográficos. Brasília, Embrapa, (ISBN 85-7383-260-6), 2004.
ERDOS, P e RÉNYI, A., 1960, The Evolution of Random Graphs. Magyar Tud. Akad.
Mat. Kutató Int. Közl. 5: 17–61.
ESTER, M., KRIEGEL, H. P. E XU, X., 1995, “Knowledge discobvery in large spatial
databases: focusing techniques for efficient class identification”, Proceedings
Iternational Symposium on Large Databases (SSD’95), Maine.
FAYYAD, U.M., PIATETSKY-SHAPIRO, G., SMYTH, P.G. From Data Mining to
Knowledge Discovery: an overview. In FAYYAD, U.M. et al. (eds) Advances in
Knowledge Discovery and Data Mining. Menlo Park. AAAI Press, 1996/The MIT
Press, pp. 1-34, 1996.
GAHEGAN, M. N., 1996, “Visualization strategies for exploratory spatial analysis”,
Proceedings: Third International Conference on GIS and Environmental Modeling,
Santa Fe.
GAHEGAN, M., 1999, “Four barries to the development of effective exploratory
visualization tools for the geosciences”, International Journal of Geographic
Information Science, 13(4), 289-310.
GAHEGAN, M., 2000, “On the application of inductive machine learning tools to
geographical analysis”, Geographical Analysis, 32(2), 113-39.
GLOBAL FORUM FOR HEALTH RESEARCH, 2006, Principais recomendações
para prioridades de pesquisa em doenças e agravos, Ministério da Saúde, Brasília.
155
GOEBEL, M. e GRUENWALD, L.,1999, “A survey of data mining and knowledge
discovery software tools”, SIGKDD Explorations, 1: pp. 20-33.
GRANGEIRO, A.,1994, “O perfil socio-econômico da AIDS no Brasil”, In: A AIDS no
Brasil (R. Parker, C. Bastos, J. Galvão & S. Pedrosa, eds.), pp. 91-128, Rio de Janeiro:
ABIA/UERJ/Editora Relume-Dumará.
GRANOVETTER, M., 1973, “The strength of weak ties”, American Journal of
Sociology 78, pp. 1360-80.
HAN, J. e FU, Y., 1995, “Discovery of multiple level associations rules from large
databases”, Proceedings of the International Conference on Very Large Databases,
430-1.
HAN, J., FU, U. WANG, W., CHIANG, J. GONG, W., KOPERSKI, , K. D., LU, Y.,
RAJAN, A., STEFANOVIC, N., XIA, B. e ZAIANE, O. R., 1996, “DBMiner: a system
for mining knowledge in large relational databases”, Proceedings of International
Conference on Mining and knowledge Discovery (KDD 96), Oregon.
HAN, J., 1999, Characteristic rules. In: Handbook of Data Mining and Knowledge
Discovery (Ed. Kloegen, W. and Zytkow, J.), Oxford University Press, Oxford, UK (in
press).
HASLETT, J., BRADLEY, R., CRAIG, P., UNWIEN, A. e WILLS, G., 1990,
“Dynamic graphics for exploring spatial data with application to locating global and
local anomalies”, The American Statistician, Vol. 45, No. 3, pp. 234-242.
HAYKIN, S., 1999, Neural Networks: a Comprehensive Foundation. Prentice Hall.
156
HSU, C. N. e KNOBLOCK, C. A., 1996, “Using inductive learning to generate rules for
semantic query optimization”, In: FAYYAD U. M. et al. (eds) Advances in Knowledge
Discovery and Data Mining, AAAI Press/The MIT Press, pp. 425-45.
HUNT, E., MARIN, J. e STONE, P., Experiments in Induction, New York: Academic
Press., 1996.
IBGE,
www.ibge.gov.br/home/estatistica/populacao/tabuadevida/2003/default.shtm,
consulta realizada em 24-01-2007
KAPLAN, R.S. e NORTON, D.P., 2004, Mapas Estratégicos Convertendo ativos
intangíveis em ativos tangíveis, Editora Campus.
KEIM, D., KRIGEL, H., 1996, “Visualization techniques for mining large databases: a
comparison”, IEEE Transactions on Knowledge and Data Engineering (Special Issue
on Dataming).
KEMPE, D., KLEINBERG, J.M. e TARDOS, E., 2005, “Influential nodes in a diffusion
model for social networks”, in ICALP, pp. 1127-1138, Springer Verlag.
KOHONEN, T., 2001, Self Organizing Maps, Springer, 2001.
LALONDE, M., 1978 “A new perspective of the health of Canadians: a work
document”, Otawa Health Conference, Ago.
LEE, H. Y. e ONG, H. L., 1996, “Visualization support for data mining”, IEEE Expert
Intelligent Systems and their Applications, Vol. 11, No. 5, pp. 69-75.
MacEACHREN, A. M., e KRAAK, M. J., 1997, “Exploratory cartographic
visualization: advancing the agenda”, Computers and Geosciences, 23(4): pp. 335-378.
157
MacEACHREN, A. M., WACHOWICS, M., EDSALL, R., HAUG, D. e MASTERS,
R., 1999, “Constructing knowledge from multivariate spatio temporal data: integrating
geographical visualization with knowledge discovery methods”, International Journal
of Geographical Information Science, 13(4): 311-334.
MacEACHREN, A. M, 2000, “An evolving cognitve-semiotic approach to geographic
visualization and knowledge construction”, Information Design Journal.
MacEACHREN, A. M, 2004, How Maps Work: Representation, Visualization,
Principles and Methodology”, 2ed, London: Taylor e Francis.
MACKINLAY, J.D., 1986, “Automating the design of graphical presentations of
relational information”, ACM Transactions and Graphics, 5(2): pp. 110-41.
MANN, J. e TARANTOLA, D., 1996, AIDS in the World II, New York/Oxford: Oxford
University Press.
MAPINFO, http://www.mapinfo.com/, dez/2006.
MATHEUS, C. J., CHAN, P.K. e PIETETSKY-SHAPIRO, G., 1993, “Systems for
knowledge discovery in databases”, IEEE Transactions on knowledge and data
engineering, 5: pp. 903-13.
MATTOS, R., 1999, Sobre os limites e as possibilidades dos estudos acerca dos
impactos das políticas públicas relativas à epidemia de HIV/AIDS. Algumas reflexões
metodológicas feitas a partir do caso brasileiro. In: Saúde, Desenvolvimento e Política:
Respostas frente à AIDS no Brasil (R. Parker, J. Galvão e M.S. Bessa, eds) pp 29-90,
São Paulo: Editora 34.
MATLAB, The Language of Technical Computing Matlab 7.0, The MathWorks, Inc.,
disponível em http://www.mathworks.com/company, dez/2006.
158
MILGRAM, S., 1969, “Interdisciplinary thinking and the small world problem”, In: M.
Sherif & C. W. Sherif (Eds), Interdisciplinary Relationships in the Social Sciences,
Chicago, Aldine, 1969, pp. 103-20.
MINISTÉRIO DA SAÚDE, 2004, Critérios de Definição de Casos de Aids, séries
anuais.
NETDRAW, 2008, www.analytictech.com, set/2008.
NG, R. e HAN, J. 1994, “Efficient and effective clustering method for spatial data
mining”, Proceedings International Conference on Very Large Databases, pp. 144-55.
NOOY, W., MRVAR, A. e BATAGELJ, V., 2005, Exploratory Social Network
Analysis with Pajek, São Paulo, Cambridge University Press.
NOWELL, D e KLEINBERG, J., 2003, “The link prediction problem for social
networks”, in CIKM 03: Proceedings of the twelfth international conference on
Information and knowledge management, pp. 556-559, 2003.
PAJEK, disponível em http://vlado.fmf.uni-lj.si/pub/networks/pajek/, 2008.
PORTER, M. E.,1989, Vantagem Competitiva: técnicas para análise da indústria e da
concorrência, Rio de Janeiro: Editora Campus.
PRIESTLEY, M.B., 1981, Spectral Analysis and Time Series, vols 1 e 2, London:
Academic Press.
QUINLAN, J. R., 1986, “Induction on decision trees”, Machine Learning, 1: pp. 81106.
159
QUINLAN, J. R., 1990, “Learning logical definitions from relations”, Machine
learning, 5: pp. 239-66.
QUINLAN, J. R., 1993, C4.5
Programs for Machine Learning, San Matel, CA:
Morgan, Kaufmann.
RAINSFORD, C. P., e RODDICK, J. F., 1999, “Database issues in knowledge
discovery and data mining”, Australian Journal of Information Systems, Vol. 6, No. 2,
pp. 101-128, 1999.
RAMAKRISHMAN, N. e GRAMA, A. Y., 1999, “ Data Mining: from serendipity to
science”, IEEE Computer, 32(8): pp. 34-7.
REINARTZ, T., 1999, “Focusing Solutions for Data Mining”, Lecture Notes in
Artificial Intelligence, pp. 16-23. Berlin: Springer.
RIBARSKY, W., KATZ, J. e HOLLAND, A., 1999, “Discovery visualization using fast
clustering”, IEEE Computer Graphics and Applications, pp. 32-39, September/October
1999.
RODDICK, J. F. e SPILLIOPOULOU, M., 1999, “A bibliography of temporal, spatial
and spatio-temporal data mining research”, SIGKDD Explorations. Vol. 1, No. 1, (in
press).
SANTOS, F.F, EBECKEN, N.F. F., 2006, “O Ressarcimento ao SUS como instrumento
de informação sobre a Saúde no Brasil”, In: 8º Congresso Brasileiro de Saúde Coletiva
e 11º Congresso Mundial de Saúde Pública, Abrasco e World Federation of Public
Health Associations, WFPHA. pp. 23-35, Rio de Janeiro, Brasil.
160
SANTOS, F.F, EBECKEN, N.F.F., 2007, Knowledge Discovery based on the
integration of KDD and GIS, Statistics for Data Mining, Learning and Knowledge
Extraction, pp 45-47, Aveiro, Portugal.
SCWARCWALD C., BASTOS, F., ESTEVES, M.A. e ANDRADE, C., 2000, “A
disseminação da epidemia da AIDS no Brasil, no período de 1987-1996: uma análise
espacial”, Caderno Saúde Pública, Rio de Janeiro, 16(Sup. 1): 7-19, 2000.
SEIXAS, J.M., CALOBA, L.P. e DELPINO, I., 1995, “Reducing Input Space
Dimension for Real-Time Data Analysis in High-Event Rate Environments”,
International Conference on Applications of Neural Networks, Paris.
SHEKHAR, S. HAMIDZADEH, B., KOHLI, A. e COYLE, M., 1993, “Learning
transformation rules for semantic query optimization: a data driven approach”, IEEE
Transactions on Knowledge and Data Engineering, 5(6): pp. 960-64.
SIEGEL, M. D., 1998, “Automatic rule derivation for semantic query optimizer”,
Proceedings of the International Conference on Expert Systems, pp. 371-85.
SOM-PAK, 2000, “The Self-Organizing Map Program Package”, SOM Programming
Team of the Helsinki University of Technology, Laboratory of Computer and
Information Science, Rakentajanaukio 2 C, SF-02150 Espoo, Finland.
STATISTICA, disponível em http://www.statsoft.com/products/products.htm, 2005.
TOBLER, W.,1979, Cellular Geography, Philosophy in Gegraphy, Gale and Olsson
(eds) Dordrecht, Reidel.
TREISMAN, A., 1986, “Features and objects in visual processing”, Scientific American,
November 1986, 255(5): 114B-25.
161
TUFTE, E. R., 1990, Envisioning Information, Graphics Press, Cheshire, Connecticut,
USA.
TUKEY, J. W., 1977, Exploratory Data Analysis. Reading, MA, USA: AddisonWesley.
ULTSCH, A., 1993, “Knowledge extraction from self-organizing neural networks”, In:
Opitz, O. ed. Information and Classification. Springer, 1993
ULTSCH, A., 1999, “Data Mining and Knowledge Discovery with Emergent SelfOrganizing Feature Maps for Multivariate Time Series”, In: Oja, E.; Kaski, S. ed.
Kohonen Maps, Elsevier, 1999. p. 36–46.
VESANTO J., 1997, “Data Mining Techniques Based on the Self-Organizing Map.”
Dissertação
–
Helsinki
University
of
Technology,
May
1997.
[online],
http://www.cis.hut.fi/projects/monitor/publications/html/mastersJV97/, Jul/2007.
VESANTO, J., 2000, SOM Toolbox for Matlab 5, Helsinki, Finlândia: Helsinki
University of Technology, 2000.
UNAIDS (The Joint United Nations Programme on HIV/AIDS), 1999, UNAIDS 3rd
Meeting of the Latin America and Caribbean Epidemiological Network. Abstracts.
Cuernavaca: UNAIDS.
WANG, W., YANG, J. e MUNTZ, R., 1997, “STINGA: Statistical information grid
approach to spatial data mining”, Proceedings of Very Large Databases, pp. 186-96.
WEKA, disponível em http://www.cs.waikato.ac.nz/ml/weka/index_downloading.html,
2005.
162
WITTEN, I. H. e EIBE F., Data Mining: Practical machine learning tools and
techniques, 2nd Edition, Morgan Kaufmann, San Francisco, 2005.
WORBOYS, M. F., DUCKHAM, M., 2004, GIS: A Computing Perspective (2nd
edition), CRC Press. Boca Raton, Florida, Taylor Francis Ltd., 2004.
ZHANG, T., RAMAKRISHMAN, R. e LINVY, M., 1996, ”BIRCH: an efficient data
clustering method for very large databases”, Proceedings ACM-SIGMOD 1996, Canada.
163
ANEXO A - Agrupamento de Bairros por Área e Índices Econômico-sociais
Agrupamento de bairros por área (km2)
Agrupamento índices econômico-sociais, 2000, município do Rio de Janeiro.
164
ANEXO B - Agrupamento de Bairros por Índices Econômico-Sociais
Claro para
escuro:
0- 32%
33-64%
65-97%
Proporção de apartamentos (%), 2005, município do Rio de Janeiro.
Claro para
escuro:
2- 47%
48-93%
94-100%
Proporção de responsáveis do domicílio com curso superior (%), 2005.
165
ANEXO C - Agrupamento de Bairros por Índices Econômico-Sociais (Parte 2)
Claro para
escuro:
2- 19%
20-37%
38-56%
Proporção de responsáveis do domicílio com renda menor que 2 salários mínimos (%),
2005.
Proporção de responsáveis do domicílio mulheres (%), 2005.
166
ANEXO D - Agrupamento de Bairros por Indices Econômicos-sociais (Parte 3)
Claro para
escuro:
2- 19%
20-37%
38-56%
Proporção de responsáveis pelo domicilio sem escolaridade, 2005.
Proporção de favelas, 2002.
167
ANEXO E - Tabelas de Medidas de Centralidade por Bairro
Limiar, Proximidade da Centralidade, Intermediação, Densidade Egocêntrica e
Taxa de Contaminação no Primeiro Ano, 1982 a 1985.
Bairro
Ano
Limiar
1ª
Prox.
Intermed. Densid.
Central.
Taxa no
ego
1o ano
ocorr
Bangu
1982
0.00
0.15
0.02
0.04
0.06
J Botânico
1983
0.00
0.13
0.00
0.17
0.48
Centro
1983
0.00
0.12
0.00
0.30
0.30
Rio
1983
0.00
0.13
0.00
0.33
0.28
Copacabana
1983
0.00
0.19
0.05
0.10
0.09
Maracanã
1983
0.00
0.13
0.01
0.17
0.39
Tanque
1983
0.00
0.10
0.00
0.00
0.32
Piedade
1983
0.00
0.10
0.00
0.00
0.24
Sampaio
1983
0.00
0.10
0.00
0.00
0.79
Madureira
1983
0.00
0.14
0.01
0.07
0.21
Leblon
1984
0.00
0.15
0.00
0.29
0.28
São Crist
1984
0.17
0.12
0.00
0.00
0.30
Marechal
1984
0.00
0.12
0.00
1.00
0.22
Paciência
1984
0.00
0.12
0.00
1.00
0.15
Barra
1984
0.00
0.12
0.00
1.00
0.15
P Seca
1984
0.20
0.12
0.00
1.00
0.19
S Conrado
1984
0.00
0.12
0.00
0.00
0.99
Flamengo
1984
0.00
0.15
0.01
0.25
0.23
Irajá
1984
0.00
0.14
0.00
0.33
0.11
Tijuca
1984
0.29
0.17
0.02
0.18
0.15
Grajaú
1984
0.00
0.15
0.00
0.33
0.59
B de Pina
1984
0.00
0.12
0.00
0.00
0.18
Méier
1984
0.00
0.11
0.00
0.00
0.20
C Nova
1984
0.14
0.12
0.00
0.00
1.49
Gávea
1984
0.17
0.16
0.01
0.17
0.53
Comprido
168
Bairro
Ano
Limiar
1ª
Prox.
Intermed. Densid.
Central.
Taxa no
ego
1o ano
ocorr
Penha
1985
0.00
0.11
0.00
0.00
0.17
Botafogo
1985
0.25
0.15
0.01
0.18
0.82
Gamboa
1985
0.50
0.12
0.00
0.00
1.93
S Teresa
1985
0.33
0.17
0.01
0.18
0.80
Bangú
1985
0.00
0.15
0.02
0.04
0.38
Pavuna
1985
0.00
0.12
0.00
0.00
0.15
Manguinhos
1985
0.00
0.13
0.00
1.00
0.40
Anchieta
1985
0.00
0.11
0.00
0.00
0.24
Benfica
1985
0.14
0.12
0.00
1.00
0.51
R Miranda
1985
0.25
0.10
0.00
0.00
0.24
Glória
1985
0.40
0.11
0.00
0.00
1.09
Santo Cristo
1985
0.50
0.11
0.00
0.00
0.94
Vila Isabel
1985
0.50
0.14
0.01
0.07
0.57
Eng Leal
1985
0.00
0.11
0.00
0.00
0.00
Leme
1985
0.33
0.12
0.00
1.00
0.75
Sepetiba
1985
0.00
0.12
0.00
0.17
0.67
B Ribeiro
1985
0.20
0.09
0.00
0.00
0.22
Catete
1985
0.25
0.15
0.01
0.20
1.46
Penha Circ
1985
0.25
0.10
0.00
0.00
0.20
Ipanema
1985
0.67
0.12
0.00
1.00
0.27
Todos Santos 1985
0.25
0.10
0.00
0.00
0.43
Olaria
1985
0.00
0.10
0.00
0.00
0.18
Taquara
1985
0.14
0.11
0.00
0.00
0.12
T Coelho
1985
0.17
0.10
0.00
0.00
0.37
Parada Lucas
1985
0.25
0.08
0.00
0.00
0.54
Humaitá
1985
0.29
0.12
0.00
0.00
0.63
Vidigal
1985
1.00
0.12
0.00
1.00
0.97
169
ANEXO F - Algoritmo Cálculo de Tendência Espacial
Nome do pgm: calcindice <parâmetros>
Onde parâmetros são:
calcindice arquivo, objeto, distância, direção, atributo, min-coefcorr, recalc, tipo-calc.
arquivo; nome do arquivo de entrada.
objeto: polígono Oi para o qual os cálculos serão feitos, sendo o default todos.
distância: limitador de distância, sendo o limite inferior da faixa a ser considerada, O
default é calcular para todos as faixas de distância, sendo os seguintes valores válidos:
0, 1.001, 6.001, 10.001 e 20.001.
direção: direções válidos: 0º, 45º , 90º, 135º , 180º , 225º , 270º e 315º .
atributo – é o atributo a ser considerado.
min-coefcorr: valor do coeficiente de correlação mínimo.
recalc: informa se a tabela de direções será regravada.
tipo-calc : cálculo a ser executado’, o default é corrlin.
Passo 1: Ler os dados por polígono.
n= total de polígonos
If objeto <> all then n=1
For each i from 1 to n do
For each j from 1 to n do
Selecionar os polígonos Oj que satisfazem critérios de distância/direção
de Oi
Gravar em tabela temporária Oi_temp
end
end
Passo 2: Validar direções
For each i from 1 to n do
Contar registros de Oi_temp por direção e distância
If
total =>2 then
Armazenar em Oi_calculo_valido
end
170
end do;
Passo 3 : Cálculo da Tendência Espacial
Inicializa/cria listas vazias obj_total
For each i from 1 to n do
If direção/distância in Oi_calc_valido then do
Inicializa media, soma, diferença, desv, dist, array x, k to 0;
Selecionar objetos in Oi_temp que satisfaçam direção/distancia
For each objeto in selecao do
k =k + 1;
armazenar x.k = atributo(objeto)
calcular soma = soma + atributo(objeto)
calcular diferenca = atributo(objeto) – atributo(Oi);
dist = distancia(objeto);
d = faixa_dist(objeto);
inserir a tupla (diferença, dist) em obj_total (obj_total.k)
end do;
// cálculo de IFd
media = (soma + atributo(Oi)) / k;
desv = atributo(Oi) – media;
soma = 0;
for each x from 1 to k do
soma = soma + (desv * (x.k – media))
end do
calcular IFd.i = soma/desv2
// Cálculo da regressão
Calcular regressão tipo_calc de obj_total e armazenar em coefcorr
171
if abs(coefcorr) > = min_coefcorr
then
Oi_ dir_dist_coefcorr = coefcorr
else Oi_ dir_dist_coefcorr = 0
Armazenar Oi_dir_dist_coefcorr
else nop;
end do;
end algoritmo
172
ANEXO G - Indicadores Econômico-sociais
Indicador
Definição
situset
Situação do setor (1- Área urbanizada)
tiposet
Tipo do setor (0-Comum ou não especial, 1- Especial aglomerado)
tdomicpp
Número de domicílios particulares permanentes
pop2000
População total
thom
População masculina
tmul
População feminina
pcasas
Proporção de casas (%)
paptos
Proporção de apartamentos (%)
pdomimp
Proporção de domicílios improvisados (%)
pdomprop
Proporção de domicílios próprios (%)
pdomalug
Proporção de domicílios alugados (%)
paguared
Proporção de domicílios ligados à rede de água (%)
paguapoc
Proporção de domicílios com abastecimento por água de poços e nascentes (%)
paguaout
Proporção de domicílios com outras fontes de água (%)
psbanh
Proporção de domicílios sem banheiro (%)
psredint
Proporção de domicílios sem rede interna de água (%)
psanrede
Proporção de domicílios ligados à rede de esgoto (%)
psanfoss
Proporção de domicílios com esgoto de fossa (%)
psanvala
Proporção de domicílios com esgoto para vala (%)
psanrio
Proporção de domicílios com esgoto para rio ou mar (%)
psaninad
Proporção de domicílios com esgoto inadequado (%)
plixocol
Proporção de domicílios com lixo coletado (%)
plixocac
Proporção de domicílios com lixo coletado por caçamba (%)
plixoent
Proporção de domicílios com lixo enterrado (%)
plixoquei
Proporção de domicílios com lixo queimado (%)
plixojog
Proporção de domicílios com lixo coletado jogado em rio ou terreno (%)
plixoina
Proporção de domicílios com lixo inadequado (%)
nmedpesd
Número médio de pessoas por domicílio
pest2g
Proporção de responsáveis do domicílio com segundo grau (%)
pest3g
Proporção de responsáveis do domicílio com curso superior (%)
173
Indicador
Definição
pren0_2
Proporção de responsáveis do domicílio com renda menor que dois salários minm ários mí
mínimos (%)
pren1_3
Proporção de responsáveis do domicílio com renda entre um e três salários mínmos
mínimos (%)
razhxm
Razão entre população masculina e feminina
pchefmul
Proporção de responsáveis do domicílio que são mulheres (%)
174
ANEXO H- Mapa da rede de bairros, tamanho do vértice proporcional a centralidade, 2005, município do Rio de Janeiro
175
ANEXO I - Mapa de valores de degrau (número de conexões) rede de bairros, do município do Rio de Janeiro
176
ANEXO J - Mapa de Valores de Centralidade de Bairros, município do Rio de Janeiro.
177
ANEXO K – Mapa de Valores de Restrição Agregada da Rede de Bairros, do município do Rio de Janeiro
178
ANEXO L – Mapa de Valores de Densidade Egocêntrica da Rede de Bairros, município do Rio de Janeiro.
179
ANEXO M – Mapa de Valores de Limiar da Rede de Bairros, município do Rio de Janeiro.
180
ANEXO N Dicionário de Dados
BANCO DE DADOS ( DBF )
NOME
No
TIPO
Caracter
TA
M
7
NOME
NU_NOTIFIC
Tipo de notificação
Data da notificação
CATEGORIAS
1. Negativa
2. individual
3. surto
Data
DT_NOTIFIC
mm/dd/aa
181
DESCRIÇÃO
CARACTERISTICAS/
CRÍTICA DE
CONSISTENCIA
Preenchimento obrigatório
É campo-chave para
identificar registros no
sistema
Número da notificação do
caso. A numeração das fichas
de notificação
pode ser
previamente
atribuída
e
impressa nas fichas ou pode ser
definida a critério da Unidade
de Saúde (Ex.: Número do
prontuário).
Define o tipo de notificação a
Não existe campo na
ser realizada
estrutura de banco
As categorias são
utilizadas para seleção da
tela correspondente ao tipo
de notificação.
Data de notificação: Data de
Preenchimento obrigatório
preenchimento da ficha de
É campo-chave para
notificação
identificar registros no
sistema
Caracter
4
NU_ANO
Município de
notificação
Caracter
7
ID_MUNICIP
Unidade de saúde (ou
outra fonte
notificadora)
Caracter
**
**
Caracter
7
2
ID_UNIDAD
E
Código e nome dos
municípios do
cadastro do IBGE
Código e nome do
estabelecimento
segundo tabela
disponibilizada para
cadastramento pelo
usuário
Ano dos primeiros sintomas
para os agravos agudos e ano
do diagnóstico para os casos de
hanseníase, tuberculose e
AIDS
Nome do município onde está
localizada a unidade de saúde
(ou outra fonte notificadora)
que realizou a notificação. O
nome não é uma variável. Está
associado ao código
Digitação do nome do
município ou do código.
Quando digitado o nome,
o código é preenchido
automaticamente e viceversa.
É campo-chave para
identificar registros no
sistema
Nome completo e código da
Digitação do nome da
unidade de saúde (ou outra
unidade de saúde ou do
fonte notificadora) que realizou código. Quando digitado
o atendimento e notificação do o nome, o código é
caso
preenchido
automaticamente e viceversa.
É campo-chave para
identificar registros no
sistema
Recomenda-se a utilização
das tabelas do SIA e SIH SUS
Siglas da unidade federada que notificou
o caso
SG_UF_NO
T
182
Preenchido
automaticamente a partir
da data correspondente
Data do
Diagnóstico
Data
Data do nascimento
Data
Idade
Caracter
-
4
DT_DIAG
mm/dd/aa
Data em que foi realizado o
diagnóstico do caso notificado.
DT_NASC
mm/dd/aa
Data de nascimento do
paciente
NU_IDADE
A composição da
variável obedece o
seguinte critério: 4º
dígito:
ANOS (A), MESES
(M), DIAS (D)
Ex. 09 M – nove
meses, 18 A – dezoito
anos
Idade do paciente por ocasião
da Data do diagnóstico.
183
OBS: quando não há data de
nascimento a idade deve ser
digitada segundo informação
fornecida pelo paciente como
aquela referida por ocasião da
data do diagnóstico e se o
paciente não souber informar
sua idade, anotar a idade
aparente.
Preenchimento
obrigatório.
Data de notificação
Preenchimento
obrigatório, caso a idade
não esteja preenchida no
campo seguinte.
Preenchida
automaticamente, a partir
da diferença entre data do
diagnóstico e data do
nascimento.
Campo de preenchimento
obrigatório caso a data de
nascimento não seja
preenchida
Raça / cor
Caracter
1
CS_RACA
123459-
branca
preta
amarela
parda
indígena
ignorado
184
Considera-se na seleção das
categorias a cor ou raça
declarada pela pessoa.
1- branca
2- preta
3- amarela ( pessoa que se
declarou de raça amarela)
4- parda (pessoa que se
declarou mulata, cabocla,
cafuza, mameluca ou
mestiça de preto com
pessoa de outra cor ou
raça)
5- indígena (pessoa que se
declarou indígena ou índia)
Escolaridade (em
anos de estudos
concluídos)
Caracter
3
CS_ESCOL
AR
1 – nenhuma
2 – De 1 a 3
3 – De 4 a 7
4 – De 8 a 11
5 – De 12 e mais
6 - Não se aplica
9 - Ignorado
UF
Caracter
2
SG_UF
Código
padronizado pelo
IBGE
185
Anos de estudo concluídos. A
classificação é obtida em função
da série e do grau que a pessoa
está freqüentando ou freqüentou
considerando a última série
concluída com aprovação. A
correspondência é feita de forma
que cada série concluída com
aprovação corresponde a um ano
de estudo.
-
Sigla da Unidade Federada de
residência do paciente por
ocasião da notificação
Ao digitar sigla da UF, o
campo 25 (país) é
preenchido
automaticamente com o
nome do país “Brasil”
Se nenhuma UF for
selecionada, o sistema pula
automaticamente para
seleção de outro país que
não o Brasil
-
Categoria padronizada
segundo definição da
RIPSA
Categoria 6- não se
aplica é preenchida
automaticamente
quando caso notificado é
< 7 anos.
Município de
residência
Caracter
7
ID_MN_RES
I
Bairro
Caracter
Zona
Caracter
1
CS_ZONA
Relações sexuais
caracter
1
ANT_REL_SE
9
ID_BAIRRO
Códigos e nomes
padronizados pelo
IBGE -
Digitação do nome do
município ou do código.
Quando digitado o nome, o
código é preenchido
automaticamente e viceversa.
- Campo de
preenchimento
obrigatório quando UF é
digitada
Códigos e nomes Nome e respectivo código do
Digitação do nome ou
padronizados
bairro de residência do paciente preenchimento automático a
segundo
tabela por ocasião da notificação.
partir do código no campo
disponibilizada
Serão exibidos apenas os Bairros seguinte.
pelo
sistema. pertencentes ao Município
Cadastramento
selecionado no campo anterior.
realizado
pelo
usuário.
1-urbana
Zona de residência do paciente
Critérios definidos na
2-rural
por ocasião da notificação
Oficina de trabalho do
3 – urbana/rural
SINAN (set/98)
9- ignorado
1.
2.
3.
só com homens
só com mulheres
com homens e
mulheres
4. não se aplica
9. ignorado
186
Código e nome do município de
residência do caso notificado.
Serão exibidos somente os
Municípios pertencentes à UF
selecionada no campo anterior.
Pratica sexual do paciente
Não pode ser nulo
Quando o paciente for do sexo
feminino e ANT_REL_SEX=2, o
programa deve mostrar uma
mensagem alertando para a
notificação de paciente
HOMOSSEXUAL FEMININO
Relações sexuais com
indivíduo sabidamente
HIV + / AIDS
caracter
1
ANT_REL__1
Classificação das
Categorias de Exposição
Caracter
2
ANT_REL_CA
1. sim
2. não
3. não se aplica
9. ignorado
10 -Homossexual
20- Bissexual
Relações Sexuais com
indivíduo sabidamente
HIV+ /AIDS
Não pode ser nulo
Categoria de Exposição do paciente
- Rotina de classificação
Hierarquizada ;
- Não pode ser nulo.
30- Heterossexual
40-Drogas
50-Hemofilico
60-Transfusão
70- Acidente de Trabalho
80-Perinatal
90-Ignorado
Para todas as categorias:
21- Bi/Drogas
22- Bi/Hemofilico
23- Bi/Transfusão
24- Bi/Droga/Hemof
Paciente com múltiplos
parceiros
caracter
1
ANT_PAC_MU
Parceiro(a) que mantém
relações sexuais só com
homens
Parceiro(a) que mantém
relações sexuais só com
mulheres
Parceiro(a) que mantém
relações sexuais com
homens e mulheres
Parceiro(a) com
múltiplos parceiros
caracter
1
ANT_PARC_H
caracter
1
ANT_ PARC
_M
caracter
1
ANT_ PARC _1
caracter
1
ANT_PARC_3
Parceiro(a) que usa
drogas injetáveis
caracter
1
ANT_PARC_D
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
187
* Campo que não consta da ficha de
notificação e na tela do programa.
Variável interna do sistema
Disponível após exportação para outros
formatos.
Ver Rotina para classificação das
categorias de exposição no final deste
documento.
Paciente com múltiplos parceiros
Aceitar apenas códigos
Listados
Parceiro (a) que mantém
relações sexuais só com
homens
Parceiro (a) que mantém
relações sexuais só com
mulheres
Parceiro (a) que mantém
relações sexuais com homens e mulheres
Aceitar apenas códigos listados
Quando paciente do sexo feminino,
preencher com a categoria 2 (não).
Aceitar apenas códigos listados
Quando paciente do sexo masculino,
preencher com a categoria 2 (não).
Aceitar apenas códigos listados
Parceiro(a) com
múltiplos parceiros
Aceitar apenas códigos listados
Parceiro(a) que usa
drogas injetáveis
Aceitar apenas códigos listados
Parceiro(a) que recebeu
transfusão de
sangue/derivados
Parceiro Hemofílico
caracter
1
ANT_PARC_T
ANT_DT
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
-
caracter
1
ANT_PARC_2
Uso de Droga Injetável
caracter
1
ANT_DROGA
Hemofilia
caracter
1
ANT_HEMOLF
História de Transfusão de
Sangue/Derivados
caracter
1
ANT_TRANSF
No caso de haver Historia
de transfusão,
data da Transfusão
Unidade federada de
Transfusão
date
caracter
2
ANT_UF
Município de Transfusão
caracter
7
Instituição de Transfusão
Após investigação
realizada conforme
algoritmo da CN
DST/AIDS, a transfusão
foi considerada causa da
infecção pelo HIV?
caracter
caracter
7
1
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Parceiro(a) que recebeu
transfusão de sangue/derivados
Aceitar apenas códigos listados
Parceiro Hemofílico
Aceitar apenas códigos listados
Paciente Usuário de Droga Injetável
Aceitar apenas códigos listados
Paciente Hemofílico
Aceitar apenas códigos listados
Quando paciente do sexo feminino,
preencher com a categoria 2 (não).
Aceitar apenas códigos listados
Paciente tem Historia de Transfusão de
Sangue/Derivados
Data da Transfusão
Não pode ser nulo se ANT_TRANSF =
1
-
unidade federada da transfusão do paciente
ANT_MUNICI
-
município da transfusão do paciente
(código IBGE)
Aceitar apenas códigos listados – tabela
de siglas de unidade federada
Não pode ser nulo se ANT_TRANSF =
1
Aceitar apenas códigos listados – tabela
de municípios
Não pode ser nulo se ANT_TRANSF =
1
ANT_INSTIT
ANT_INFECC
1. sim
2. não
3. não se aplica
9. ignorado
Nome da Instituição de Transfusão
Após investigação realizada conforme
algoritmo da CN DST/AIDS, a transfusão
foi considerada causa da infecção pelo HIV
188
Não pode ser nulo se ANT_TRANSF =
1
Crítica para data da transfusão em
relação à data do diagnóstico – não
aceitar se a data da transfusão for
menor que 1 ano da data do
diagnóstico e mostrar mensagem
alertando da inconsistência!
Transmissão vertical
(mãe/filho)
Caracter
1
ANT_TRASMI
1. sim
2. não
3. não se aplica
9. ignorado
Ocorreu transmissão vertical (mãe/filho)
Acidente de trabalho em
profissionais de saúde
com sorologia negativa no
momento do acidente e
soroconversão nos
primeiros 6 meses
Outro
Caracter
1
ANT_ACIDEN
1. sim
2. não
3. não se aplica
9. ignorado
Acidente trabalho em Profissionais de
saúde com sorologia negativa no momento
do acidente e soroconversão nos primeiros
6 meses
Caracter
70
ANT_OUTRO
CRITÉRIO CARACAS
Caracter
1
ANT_SARCO
M
Sarcoma de Kaposi
Pontuação (10)
Aceitar apenas códigos listados.
Tuberculose disseminada
/ extra-pulmonar / não
cavitária
Candidíase Oral ou
leucoplasia pilosa
Caracter
1
ANT_TUBERC
Tuberculose disseminada/extrapulmonar/
não cavitária - Pontuação (10)
Aceitar apenas códigos listados.
Caracter
1
ANT_CANDID
Candidíase Oral ou Leucoplasia Pilosa
Pontuação (5)
Aceitar apenas códigos listados.
Tuberculose pulmonar
cavitária ou não
especificada
Herpes Zoster em
indivíduo menor ou igual
a 60 anos
Disfunção do sistema
nervoso central
Caracter
1
ANT_PULMO
N
Tuberculose pulmonar cavitária ou não
especificada - Pontuação (5)
Aceitar apenas códigos listados.
Caracter
1
ANT_HERPES
1
ANT_DISFUN
Herpes Zoster em indivíduo menor ou igual
a 60 anos
Pontuação (5)
Disfunção do sistema nervoso central
Pontuação (5)
Aceitar apenas códigos listados.
Caracter
Diarréia igual ou maior
que um 1 mês
Caracter
1
ANT_DIARRE
Diarréia igual ou maior que um 1 mês
Pontuação (2)
Aceitar apenas códigos listados.
Febre >= 38ºC por tempo
maior ou igual a 1 mês
Caracter
1
ANT_FEBRE
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
Febre maior ou igual 38º C, por tempo
maior ou igual a 1 mês
Pontuação (2)
Aceitar apenas códigos listados.
Sarcoma de Kaposi
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
189
Aceitar apenas códigos listados.
Incluir mensagem alertando o
digitador que o sistema está
incluindo um caso de aids de
transmissão vertical e se ele tem
certeza!
Aceitar apenas códigos listados.
Incluir mensagem alertando o
digitador que o sistema está
incluindo um caso de aids por
acidente de trabalho e se ele tem
certeza!
Aceitar apenas códigos listados.
Caquexia ou perda de
peso maior que 10%
Caracter
1
ANT_CAQUE
X
Astenia maior ou igual a 1
mês
Caracter
1
ANT_ASTERI
Dermatite persistente
Caracter
1
ANT_DERMA
T
Anemia e/ou linfopenia
e/ou trombocitopenia
Caracter
1
ANT_ANEMIA
Tosse persistente ou
qualquer pneumonia
(exceto tuberculose)
Caracter
1
ANT_TOSSE
Linfadenopatia maior ou
igual a 1 cm, maior ou
igual a 2 sítios
extrainguinais por tempo
> ou = a 1 mês
CRITÉRIO CDC –
Candidíase (esôfago,
traquéia, brônquios,
pulmão)
Citomegalovirose
Caracter
1
ANT_LINFO
Caracter
1
Caracter
Câncer cervical invasivo
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Caquexia ou pedra de peso maior que 10%
Pontuação (2)
Aceitar apenas códigos listados.
Astenia maior ou igual a 1 mês
Pontuação (2)
Aceitar apenas códigos listados.
Astenia maior ou igual a 1 mês
Pontuação (2)
Aceitar apenas códigos listados.
Anemia e/ou linfopenia e/ou
trombocitopenia
Pontuação (2)
Tosse persistente ou qualquer pneumonia
(exceto tuberculose)
Pontuação (2)
Aceitar apenas códigos listados.
1. Sim
2. Não
9. Ignorado
Linfadenopatia maior ou igual a 1 cm,
maior ou igual a 2 sítios extra-inquinais por
tempo maior ou igual a 1 mês
Pontuação (2)
Aceitar apenas códigos listados.
ANT_PULMA
O
1.
2.
9.
Sim
Não
Ignorado
Candidíase (esôfago, traquéia,
brônquios,pulmão)
Aceitar apenas códigos listados.
1
ANT_CITO
Aceitar apenas códigos listados.
1
ANT_CANCER
Câncer cervical invasivo
Criptococose
(Extrapulmonar)
Caracter
1
ANT_CRIPTO
Criptococose (Extra-Pulmonar)
Aceitar apenas códigos listados
Crítica: se sexo=1, preencher com o
código 2.
Aceitar apenas códigos listados
Criptosporidíase
Caracter
1
ANT_CRIP_1
Criptosporidíase
Aceitar apenas códigos listados.
Histoplasmose
disseminada
Caracter
1
ANT_HISTO
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Citomegalovirose
Caracter
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
Histoplasmose disseminada
Aceitar apenas códigos listados.
190
Aceitar apenas códigos listados.
Isosporíase
Caracter
1
ANT_ISOPOR
Herpes Simples (MucoCutâneo > 1 mês,
esôfago, brônquios,
pulmão)
Leucoencefalopatia
Multifocal Progressiva
Caracter
1
ANT_H_SIMP
Caracter
1
ANT_LEUCO
Linfoma não Hodgkin
caracter
1
ANT_LINFOM
Linfoma Primário do
Cérebro
caracter
1
ANT_LINFO_
Micobacteriose
Disseminada
caracter
1
ANT_MICRO
Pneumonia
por P. Carinii
caracter
1
ANT_PNEUM
O
Salmonelose
(Septicemia recorrente)
caracter
1
ANT_SALMO
Toxoplasmose Cerebral
caracter
1
ANT_TOXO
Sorologia para HIV Elisa (1º teste)
caracter
1
LAB_ELISA1
1. Sim
2. Não
9. Ignorado
1. Sim
2. Não
9. Ignorado
Isosporíase
Aceitar apenas códigos listados.
Herpes Simples (Muco-Cutâneo > 1 mês,
esôfago, brônquios, pulmão)
Aceitar apenas códigos listados.
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
1.
2.
9.
Leucoencefalopatia Multifocal Progressiva
Aceitar apenas códigos listados.
Linfoma não Hodgkin
Aceitar apenas códigos listados.
Linfoma Primário do Cérebro
Aceitar apenas códigos listados.
Micobacteriose Disseminada
Aceitar apenas códigos listados.
Pneumonia por P. Carinii
Aceitar apenas códigos listados.
1. Sim
2. Não
9. Ignorado
1. Sim
2. Não
9. Ignorado
Salmonelose (Septicemia recorrente)
Aceitar apenas códigos listados
Toxoplasmose Cerebral
Aceitar apenas códigos listados
1.
2.
3.
4.
9.
Diagnóstico de Infecção pelo HIV
Elisa ( 2º teste )
Aceitar apenas códigos listados
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Sim
Não
Ignorado
Positivo
Negativo
Inconclusivo
Não realizado
Ignorado
191
Sorologia para HIV –
Imunofluorescência
caracter
1
LAB_IMUNO
Sorologia para o HIV –
Western Blot
caracter
1
LAB_WEST
PCR
caracter
1
LAB_PCR
Outros
caracter
1
LAB_OUTRO
Outros
Contagem de Linfócitos
CD4+
Data da contagem de
CD4+
caracter
Numérica
60
4
LAB_OUTROS
LAB_CD4
especificar
LAB_DT
Data da contagem do CD4
data
1.
2.
3.
4.
9.
1.
2.
3.
4.
9.
1.
2.
3.
4.
9.
1.
2.
3.
4.
9.
Positivo
Negativo
Inconclusivo
Não realizado
Ignorado
Positivo
Negativo
Inconclusivo
Não realizado
Ignorado
Positivo
Negativo
Inconclusivo
Não realizado
Ignorado
Positivo
Negativo
Inconclusivo
Não realizado
Ignorado
192
Diagnóstico de Infecção pelo HIV
Imunofluorescência
Aceitar apenas códigos listados
Diagnóstico de Infecção pelo HIV
Western Blot
Aceitar apenas códigos listados
Diagnóstico de Infecção pelo HIV
PCR
Aceitar apenas códigos listados
Outros Diagnósticos de Infecção pelo HIV
Aceitar apenas códigos listados
Critério excepcional
CDC – caso sem
diagnóstico laboratorial
da infecção pelo HIV,
excluídas outras causas
de imunodeficiência
(corticoterapia
sistêmica, leucoses e
síndrome de imunodeficiência genética) e
com doença indicativa
de AIDS diagnosticada
por método definitivo
Diagnóstico de AIDS
explicitado na
declaração de óbito
Óbito por causa não
externa em paciente em
acompanhamento e com
ARC
Nome da unidade
federada onde se realiza
o tratamento
Nome do município
onde se realiza o
tratamento
Nome da Unidade de
saúde onde se realiza o
tratamento
Situação Atual
caracter
1
DEF_DEFINI
1. Sim
2. Não
9. Ignorado
No caso de presença de situações clínicas
definidoras, porém sem o diagnóstico
laboratorial da infecção pelo HIV, houve
exclusão das causas de imunodeficiência
listadas na definição de caso de AIDS do
Ministério da Saúde
Aceitar apenas códigos listados
Campo habilitado se o diagnóstico
laboratorial (LAB_ELISA1 &
LAB_ELISA2 & LAB_IMUNO &
LAB_WEST & LAB_PCR &
LAB_OUTRO) >2
caracter
1
DEF_DIAGNO
caracter
1
DEF_CAUSA
1. Sim
2. Não
9. Ignorado
1. Sim
2. Não
9. Ignorado
Diagnóstico de AIDS explicitado na
declaração de óbito, sem nenhum outro
dado
Óbito por causa não externa em paciente
em acompanhamento e com ARC
Aceitar apenas códigos listados
Se EVO_SITUAC=1, então campo
preenchido com código 2)
Aceitar apenas códigos listados
Se EVO_SITUAC=1, então campo
preenchido com código 2)
caracter
7
TRA_UF
-
Nome da unidade federada onde se realiza o
tratamento
caracter
7
TRA_MUNICI
-
Nome do município onde se realiza o
tratamento
caracter
6
TRA_UNIDAD
-
Nome da unidade de saúde onde se realiza
o tratamento
caracter
1
EVO_SITUAC
Situação atual do paciente: vivo, morto ou
ignorado
Aceitar apenas códigos listados
Data do Óbito
data
EVO_DT
1. Vivo
2 . Morto
9 . Ignorado
-
Data do óbito do paciente
Se EVO_SITUAC =1 ativar o botão
SALVAR, caso contrário habilitar os
campos seguintes como obrigatórios.
Nº da declaração de
óbito (D.O)
caracter
EVO_DO
-
Numero da D. O
15
193
No caso de óbito
informar a causa da
morte (exatamente
como a Declaração de
óbito)
No caso de óbito
informar a causa da
morte
No caso de óbito
informar a causa da
morte
No caso de óbito
informar a causa da
morte
Caracter
60
EVO_CAUSA1
-
No caso de óbito informar a causa da morte
(exatamente como na declaração de óbito
Caracter
60
EVO_CAUSA2
-
No caso de óbito informar a causa da morte
(exatamente como na declaração de óbito
Caracter
60
EVO_CAUSA3
-
No caso de óbito informar a causa da morte
(exatamente como na declaração de óbito
Caracter
60
EVO_CAUSA4
-
No caso de óbito informar a causa da morte
(exatamente como na declaração de óbito
* Critério de
confirmação/descarte
caracter
3
CRITERIO
Definição do caso de aids em maiores de 12
anos segundo os critérios adotados pela
Coordenação Nacional de DST/Aids
Variável interna do sistema, preenchida
segundo os critérios descritos abaixo. A
hierarquização dos critérios deve ser
feita na seguinte ordem de importância
(maior para o menor): 123, 120, 130,
140, 200, 100, 300, 500, 600, 400.
* Data da Digitação
data
8
DTDIGIT
100. CDC
200. CDC/Laboratório
300. RJ/Caracas
120. CDC+
CDC/Laboratório
130. CDC+ RJ/Caracas
140. CDC/Laboratório +
RJ/Caracas
123. CDC+
CDC/Laboratório +
RJ/Caracas
400.CDC Excepcional
500. ARC+ Óbito
600. Óbito
900. Descartado
901.HIV+
-
Data da Digitação do caso, preenchido com
a data do dia
da digitação do caso
preenchido com a data da digitação do
caso
* Campo que não consta da ficha de
notificação e da tela do programa.
194
Definição de caso de aids em casos com 13 anos ou mais segundo os critérios adotados pela Coordenação Nacional de DST/Aids
CDC : (LAB_ELISA1=1 AND LAB_ELISA2=1) OR (LAB_IMUNO=1 OR LAB_WEST=1 OR LAB_PCR=1 OR LAB_OUTRO=1) AND (LAB_IMUNO<>2 AND LAB_WEST<>2
AND LAB_PCR<>2 AND LAB_OUTRO<>2) AND (ANT_PULMAO=1 OR ANT_CITO=1 OR ANT_CANCER=1 OR ANT_CRIPTO=1 OR ANT_CRIP_1=1 OR ANT_HISTO=1
OR ANT_ISOPOR=1 OR ANT_H_SIMP=1 OR ANT_LEUCO=1 OR ANT_LINFOM=1 OR ANT_LINFO_ =1 OR ANT_MICRO=1 OR ANT_PNEUMO=1 OR ANT_SALMO=1 OR
ANT_TOXO=1)
CDC/Laboratório: (LAB_ELISA1=1 E LAB_ELISA2=1) OR (LAB_IMUNO=1 OR LAB_WEST=1 OR LAB_PCR=1 OR LAB_ORTRO=1) AND (LAB_IMUNO<>2 AND
LAB_WEST<>2 AND LAB_PCR<>2 AND LAB_OUTROS<>2) AND (LAB_CD4 >0 AND LAB_CD4 <350).
RJ/CARACAS : (LAB_ELISA1=1 AND LAB_ELISA2=1 OR LAB_IMUNO=1 OR LAB_WEST=1 OR LAB_PCR=1 OR LAB_OUTRO=1) AND (LAB_IMUNO<>2 AND
LAB_WEST<>2 AND LAB_PCR<>2 AND LAB_OUTRO<>2) AND (a soma dos campos PS, PT, PC, PP, PH, PD, PR, PF, PQ, PA, PE ,PN,PO,PL totalize 10 ou mais pontos,
segundo as condições abaixo relacionadas):
se ANT_SARCOM=1 então PS=10 ELSE PS=0
se ANT_TUBERC=1 então PT=10 ELSE PT=0
se ANT_CANDID=1 então PC=5 ELSE PC=0
se ANT_PULMON=1 então PP=5 ELSE PP=0
se ANT_HERPES=1 então PH=5 ELSE PH=0
se ANT_DISFUN =1 então PD=5 ELSE PD=0
se ANT_DIARRE=1 então PR=2 ELSE PR=0
se ANT_FEBRE=1 então PF=2 ELSE PF=0
se ANT_CAQUEX=1 então PQ=2 ELSE PQ=0
se ANT_ASTENI=1 então PA=2 ELSE PA=0
se ANT_DERMAT=1 então PE=2 ELSE PE=0
se ANT_ANEMIA=1 então PN=2 ELSE PN=0
se ANT_TOSSE=1 então PO=2 ELSE PO=0
se ANT_LINFOM=1 então PL=2 ELSE PL=0
CDC Excepcional: (LAB_ELISA1>3 AND LAB_ELISA2>3 AND LAB_IMUNO>3 AND LAB_WEST>3 AND LAB_PCR>3 AND LAB_OUTRO>3) AND
(ANT_PULMAO=1 OR ANT_CITO=1 OR ANT_CANCER=1 OR ANT_CRIPTO=1 OR ANT_CRIP_1=1 OR ANT_HISTO=1 OR ANT_ISOPOR=1 OR ANT_H_SIMP=1 OR
ANT_LEUCO=1 OR ANT_LINFOM=1 OR ANT_LINFO_ =1 OR ANT_MICRO=1 OR ANT_PNEUMO=1 OR ANT_SALMO=1 OR ANT_TOXO=1)
ARC + ÓBITO: (LAB_ELISA1=1 E LAB_ELISA2=1) OR (LAB_IMUNO=1 OR LAB_WEST=1 OR LAB_PCR=1 OR LAB_OUTRO=1) AND (LAB_IMUNO<>2 AND
LAB_WEST<>2 AND LAB_PCR<>2 AND LAB_OUTRO<>2) AND (EVO_SITUAC=2 AND DEF_CAUSA=1 AND EVO_DT= DT_DIAG) AND (a soma dos campos PS, PT, PC,
PP, PH, PD, PR, PF, PQ, PA, PE,PN,PO,PL totalize menos de 10 pontos , segundo as condições abaixo relacionadas):
195
A data do óbito deve ser igual a data do diagnostico
se ANT_CANDID=1 então PC=5 ELSE PC=0
se ANT_PULMON=1 então PP=5 ELSE PP=0
se ANT_HERPES=1 então PH=5 ELSE PH=0
se ANT_DISFUN =1 então PD=5 ELSE PD=0
se ANT_DIARRE=1 então PR=2 ELSE PR=0
se ANT_FEBRE=1 então PF=2 ELSE PF=0
se ANT_CAQUEX=1 então PQ=2 ELSE PQ=0
se ANT_ASTENI=1 então PA=2 ELSE PA=0
se ANT_DERMAT=1 então PE=2 ELSE PE=0
se ANT_ANEMIA=1 então PN=2 ELSE PN=0
se ANT_TOSSE=1 então PO=2 ELSE PO=0
se ANT_LINFOM=1 então PL=2 ELSE PL=0
ÓBITO: (LAB_ELIS>2 AND LAB_ELISA2>2 e LAB_IMUNO>2 AND LAB_WEST>2 AND LAB_PCR>2 AND LAB_OUTRO>2) AND ( EVO_DT = DT_DIAG) AND
(EVO_SITUAC=2 AND DEF_DIAGNO=1) AND (EVO_CAUSA1<>´ ´ OR EVO_CAUSA2<>´ ´ OR EVO_CAUSA3<>´ ´ OR EVO_CAUSA4<>´ ´).
A data do óbito deve ser igual a data do diagnostico
Observação: Caso o critério definido, pelo sistema, seja o CDC/Laboratório (categoria 200), a data de diagnóstico deve ser igual à data da contagem do CD4 (LAB_DT).
DESCARTADO: os casos que não atendam as condições acima. O registro é salvo na base de dados, porém não entra no lote de transferência.
Rotina para classificação das categorias de exposição:
10 – Homossexual:
Em casos do sexo masculino:
quando ANT_REL_SE = 1 AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_HEMOF<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
Em casos do sexo feminino:
quando ANT_REL_SE = 1 AND ANT_REL_1= 1 AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_HEMOF<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
11 – Homo/Drogas:
Em casos do sexo masculino:
quando ANT_REL_SE = 1 AND ANT_DROGA=1 AND ANT_INFECC<>1 AND ANT_HEMOF<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
Em casos do sexo feminino
quando ANT_REL_SE = 1 AND ANT_REL_1= 1 AND ANT_DROGA=1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
12 - Homo/Hemofilico:
Somente nos casos de sexo masculino, quando ANT_REL_SE = 1 AND ANT_HEMOF=1 AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND
ANT_ACIDEN<>1
13 – Homo/ Transfusão:
Manter somente para receber base de dados anterior. Casos novos entram na categoria 62.
14 - Homo/Droga/Hemof:
196
Somente nos casos de sexo masculino, quando ANT_REL_SE = 1 AND ANT_HEMOF=1 AND ANT_DROGA=1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND
ANT_ACIDEN<>1
15 – Homo/Droga/Transfusão:
Manter somente para receber base de dados anterior. Casos novos entram na categoria 64.
20 - Bissexual:
Somente nos casos do sexo masculino, quando ANT_REL_SE = 3 AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_HEMOF<>1 AND ANT_TRASMI<>1 AND
ANT_ACIDEN<>1
21 - Bi/Drogas:
Somente nos casos do sexo masculino, quando ANT_REL_SE = 3 AND ANT_DROGA=1 AND ANT_INFECC<>1 AND ANT_HEMOF<>1 AND ANT_TRASMI<>1 AND
ANT_ACIDEN<>1
22 - Bi/Hemofílico:
Somente nos casos do sexo masculino, quando ANT_REL_SE = 3 AND ANT_HEMOF=1 AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND
ANT_ACIDEN<>1
23- Bi/Transfusão:
Manter somente para receber base de dados anterior. Casos novos entram na categoria 63.
24 - Bi/Droga/Hemofílico :
Somente nos casos do sexo masculino, quando ANT_REL_SE = 3 AND ANT_DROGA=1 AND ANT_HEMOF=1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND
ANT_ACIDEN<>1
25 – Bi/Droga/Transfusão:
Manter somente para receber base de dados anterior. Casos novos entram na categoria 65.
30- Heterossexual:
Em casos do sexo masculino:
quando ANT_REL_SE = 2 AND (ANT_REL_1=1 OR ANT_PAC_MU=1 OR ANT_PARC_H=1 OR ANT_ PARC _M=1 OR ANT_ PARC _1=1 OR ANT_PARC_3=1 OR
ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_HEMOF<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
Em caso do sexo feminino:
quando ANT_REL_SE = 1 AND (ANT_REL_1= 1 OR ANT_PAC_MU=1 OR ANT_PARC_H=1 OR ANT_ PARC _M=1 OR ANT_ PARC _1=1 OR ANT_PARC_2=1 OR
ANT_PARC_3=1 OR ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
quando ANT_REL_SE = 3 AND (ANT_REL_1= 1 OR ANT_PAC_MU=1 OR ANT_PARC_H=1 OR ANT_ PARC _M=1 OR ANT_ PARC _1=1 OR ANT_PARC_2=1 OR
ANT_PARC_3=1 OR ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
31- Hetero/Droga:
Em casos do sexo masculino:
quando ANT_REL_SE = 2 AND ANT_DROGA=1 (ANT_REL_1 OR ANT_PAC_MU=1 OR ANT_PARC_H=1 OR ANT_ PARC _M=1 OR ANT_ PARC _1=1 OR ANT_PARC_3=1
OR ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_INFECC<>1 AND ANT_HEMOF<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
Em casos do sexo feminino:
quando ANT_REL_SE = 1 AND ANT_DROGA=1 (ANT_REL_1= 1 AND ANT_PAC_MU=1 OR ANT_PARC_H=1 OR ANT_ PARC _M=1 OR ANT_ PARC _1=1 OR
ANT_PARC_2=1 OR ANT_PARC_3=1 OR ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_INFECC<>1 AND ANT_HEMOF<>1 AND ANT_TRASMI<>1 AND
ANT_ACIDEN<>1
197
quando ANT_REL_SE = 3 AND ANT_DROGA=1 (ANT_REL_1= 1 OR ANT_PAC_MU=1 OR ANT_PARC_H=1 OR ANT_ PARC _M=1 OR ANT_ PARC _1=1 OR
ANT_PARC_2=1 OR ANT_PARC_3=1 OR ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
32 - Hetero/Hemofilico:
Somente nos casos do sexo masculino, quando ANT_REL_SE = 2 AND (ANT_REL_1 OR ANT_PAC_MU=1 OR ANT_PARC_H=1 OR ANT_ PARC _M=1 OR ANT_ PARC _1=1
OR ANT_PARC_3=1 OR ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_HEMOF=1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
33 - Hetero/Transfusão:
Manter somente para receber base de dados anterior. Casos novos entram na categoria 66.
34 - Hetero/Droga/Hemof:
Somente em casos do sexo masculino, quando ANT_REL_SE = 2 AND ANT_DROGA=1 AND ANT_HEMOF=1 AND ANT_REL_1 OR ANT_PAC_MU=1 OR ANT_PARC_H=1 OR
ANT_ PARC _M=1 OR ANT_ PARC _1=1 OR ANT_PARC_3=1 OR ANT_PARC_D=1 OR ANT_PARC_T=1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND
ANT_ACIDEN<>1
35 – Hetero/Droga/Transfusão:
Manter somente para receber base de dados anterior. Casos novos entram na categoria 67.
36 – Hetero com parceria de risco indefinido:
Em casos do sexo masculino:
quando ANT_REL_SE = 2 AND (ANT_REL_1<>1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _M<>1 OR ANT_ PARC _1<>1 OR ANT_PARC_3<>1 OR
NT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_HEMOF<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
Em caso do sexo feminino:
quando ANT_REL_SE = 1 AND (ANT_REL_1<> 1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _M<>1 OR ANT_ PARC _1<>1 OR ANT_PARC_2=1 <>1
OR ANT_PARC_3<>1 OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
quando ANT_REL_SE = 3 AND (ANT_REL_1<> 1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _M<>1 OR ANT_ PARC _1<>1 OR ANT_PARC_2=1<>1
OR ANT_PARC_3<>1 OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>
40 - Drogas:
Em casos do sexo masculino:
quando (ANT_REL_SE =9 OR ANT_REL_SE = 4) AND ANT_DROGA=1 AND ANT_INFECC<>1 AND ANT_HEMOF<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
ou quando ANT_REL_SE = 2 AND ANT_DROGA=1 AND (ANT_REL_1<>1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _M<>1 OR ANT_ PARC _1<>1 OR
ANT_PARC_3<>1 OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_INFECC<>1 AND ANT_HEMOF<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
Em casos do sexo feminino:
quando (ANT_REL_SE =9 OR ANT_REL_SE = 4) AND ANT_DROGA=1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
quando ANT_REL_SE = 1 AND ANT_DROGA=1 AND (ANT_REL_1<>1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _M<>1 OR ANT_ PARC _1<>1 OR
ANT_PARC_2=1<>1 OR ANT_PARC_3<>1 OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
ou quando ANT_REL_SE = 3 AND ANT_DROGA=1 AND (ANT_REL_1<>1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _M<>1 OR ANT_ PARC _1<>1 OR
ANT_PARC_2=1<>1 OR ANT_PARC_3<>1 OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
198
41 -Drogas/Hemofílico:
Somente para o sexo masculino,
quando (ANT_REL_SE =9 OR ANT_REL_SE = 4) AND ANT_DROGA=1 AND ANT_HEMOF=1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
ou quando ANT_REL_SE = 2 AND ANT_DROGA=1 AND ANT_HEMOF=1 AND (ANT_REL_1<>1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _M<>1 OR
ANT_ PARC _1<>1 OR ANT_PARC_3<>1 OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
42 -Drogas/ Transfusão:
Manter somente para receber base de dados anterior.
50-Hemofilia:
Somente para o sexo masculino,
quando (ANT_REL_SE =9 OR ANT_REL_SE = 4) ANT_HEMOF=1 AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
ou quando ANT_REL_SE = 2 AND ANT_HEMOF=1 AND (ANT_REL_1<>1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _M<>1 OR ANT_ PARC _1<>1 OR
ANT_PARC_3<>1 OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_DROGA<>1 AND ANT_INFECC<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
60-Transfusão:
Em casos do sexo masculino:
quando (ANT_REL_SE =9 OR ANT_REL_SE = 4) AND ANT_INFECC=1 AND ANT_TRASMI<>1 AND ANT_DROGA<>1 AND ANT_HEMOF<>1 AND ANT_TRASMI<>1 AND
ANT_ACIDEN<>1
ou quando ANT_REL_SE = 2 AND ANT_INFECC=1 AND (ANT_REL_1<>1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _1<>1 OR ANT_PARC_3<>1
OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_DROGA<>1 AND ANT_TRASMI<>1 AND ANT_HEMOF<>1 AND ANT_ACIDEN<>1
Em casos do sexo feminino:
quando (ANT_REL_SE =9 OR ANT_REL_SE = 4) AND ANT_INFECC=1 AND ANT_TRASMI<>1 AND ANT_DROGA<>1 AND ANT_ACIDEN<>1
quando ANT_REL_SE = 2 AND ANT_REL_1<>1 AND ANT_INFECC=1 AND ANT_TRASMI<>1 AND ANT_DROGA<>1 AND ANT_ACIDEN<>1
quando ANT_REL_SE = 1 AND ANT_INFECC=1 AND (ANT_REL_1<> 1 OR ANT_PAC_MU<>1 OR ANT_ PARC _M<>1 OR ANT_ PARC _1<>1 OR ANT_PARC_2=1 <>1 OR
ANT_PARC_3<>1 OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_DROGA<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
ou quando ANT_REL_SE = 3 AND ANT_INFECC=1 AND ANT_DROGA=1 AND (ANT_REL_1<>1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _M<>1 OR
ANT_ PARC _1<>1 OR ANT_PARC_2=1 <>1 OR ANT_PARC_3<>1 OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
61-Transfusão/Drogas:
Em casos do sexo masculino:
quando (ANT_REL_SE =9 OR ANT_REL_SE = 4) AND ANT_DROGA=1 AND ANT_INFECC=1 AND ANT_TRASMI<>1 AND ANT_HEMOF<>1 AND ANT_ACIDEN<>1
ou quando ANT_REL_SE = 2 AND ANT_INFECC=1 AND ANT_DROGA=1 AND (ANT_REL_1<>1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _M<>1
OR ANT_ PARC _1<>1 OR ANT_PARC_3<>1 OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_TRASMI<>1 AND ANT_HEMOF<>1 AND ANT_ACIDEN<>1
Em casos do sexo feminino:
quando (ANT_REL_SE =9 OR ANT_REL_SE = 4) AND ANT_INFECC=1 AND ANT_DROGA=1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
quando ANT_REL_SE = 2 AND ANT_REL_1<>1 AND ANT_DROGA=1 AND ANT_INFECC=1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
quando ANT_REL_SE = 1 AND ANT_INFECC=1 AND ANT_DROGA=1 AND (ANT_REL_1<> 1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _M<>1 OR
ANT_ PARC _1<>1 OR ANT_PARC_2=1 <>1 OR ANT_PARC_3<>1 OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
199
ou quando ANT_REL_SE = 3 AND ANT_INFECC=1 AND ANT_DROGA=1 AND (ANT_REL_1<>1 OR ANT_PAC_MU<>1 OR ANT_PARC_H<>1 OR ANT_ PARC _M<>1 OR
ANT_ PARC _1<>1 OR ANT_PARC_2=1 <>1 OR ANT_PARC_3<>1 OR ANT_PARC_D<>1 OR ANT_PARC_T<>1) AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
62-Transfusão/Homo:
Em casos do sexo masculino:
quando ANT_REL_SE = 1 AND ANT_INFECC=1 AND ANT_TRASMI<>1 AND ANT_DROGA<>1 AND ANT_HEMOF<>1 AND ANT_ACIDEN<>1
Em casos do sexo feminino:
quando ANT_REL_SE = 2 AND ANT_REL_1=1 AND ANT_INFECC=1 AND ANT_TRASMI<>1 AND ANT_REL_1= 1 AND ANT_DROGA<>1 AND ANT_ACIDEN<>1
63-Transfusão/Bi:
Somente nos casos do sexo masculino, quando ANT_REL_SE = 3 AND ANT_INFECC=1 AND ANT_TRASMI<>1 AND ANT_DROGA<>1 AND ANT_HEMOF<>1 AND
ANT_ACIDEN<>1
64-Transfusão/Droga/Homossexual:
Em casos do sexo masculino:
quando ANT_REL_SE = 1 AND ANT_DROGA=1 AND ANT_INFECC=1 AND ANT_TRASMI<>1 AND ANT_HEMOF<>1 AND ANT_ACIDEN<>1
Em casos do sexo feminino:
quando ANT_REL_SE = 2 AND ANT_REL_1= 1 AND ANT_DROGA=1 AND ANT_INFECC=1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
65 -Transfusão/Droga/Bissexual:
Somente nos casos do sexo masculino, quando ANT_REL_SE = 3 AND ANT_DROGA=1 AND ANT_INFECC=1 AND ANT_TRASMI<>1AND ANT_HEMOF<>1 AND
ANT_ACIDEN<>1
66-Transfusão/Hetero:
Em casos do sexo masculino:
quando ANT_REL_SE = 2 AND ANT_INFECC=1 AND (ANT_REL_1=1 OR ANT_PAC_MU=1 OR ANT_PARC_H=1 OR ANT_ PARC _1=1 OR ANT_PARC_3=1 OR
ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_DROGA<>1 AND ANT_TRASMI<>1 AND ANT_HEMOF<>1 AND ANT_ACIDEN<>1
Em caso do sexo feminino:
quando ANT_REL_SE = 1 AND ANT_INFECC=1 AND (ANT_REL_1= 1 OR ANT_PAC_MU=1 OR ANT_PARC_H=1 OR ANT_ PARC _M=1 OR ANT_ PARC _1=1 OR
ANT_PARC_2=1 OR ANT_PARC_3=1 OR ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_DROGA<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
ou quando ANT_REL_SE = 3 AND ANT_INFECC=1 AND (ANT_REL_1= 1 OR ANT_PAC_MU=1 OR ANT_ PARC _M=1 OR ANT_ PARC _1=1 OR ANT_PARC_2=1<>1 OR
ANT_PARC_3=1 OR ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_DROGA<>1 AND ANT_TRASMI<>1 AND ANT_ACIDEN<>1
67-Transfusão/Droga/Hetero:
Em casos do sexo masculino:
quando ANT_REL_SE = 2 AND ANT_INFECC=1 AND ANT_DROGA=1 AND (ANT_REL_1=1 OR ANT_PAC_MU=1 OR ANT_PARC_H=1 OR ANT_ PARC _M=1 OR ANT_
PARC _1=1 OR ANT_PARC_3=1 OR ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_TRASMI<>1 AND ANT_HEMOF<>1 AND ANT_ACIDEN<>1
Em caso do sexo feminino:
quando ANT_REL_SE = 1 AND ANT_INFECC=1 AND ANT_DROGA=1 AND (ANT_REL_1= 1 OR ANT_PAC_MU=1 OR ANT_PARC_H=1 OR ANT_ PARC _M=1 OR ANT_
PARC _1=1 OR ANT_PARC_2=1 OR ANT_PARC_3=1 OR ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_TRASMI=1AND ANT_ACIDEN<>1
200
quando ANT_REL_SE = 3 AND ANT_INFECC=1 AND ANT_DROGA=1 AND (ANT_REL_1= 1 OR ANT_PAC_MU=1 OR ANT_PARC_H=1 OR ANT_ PARC _M=1 OR ANT_
PARC _1=1 OR ANT_PARC_2=1 OR ANT_PARC_3=1 OR ANT_PARC_D=1 OR ANT_PARC_T=1) AND ANT_TRASMI<>1AND ANT_ACIDEN<>1
70- Acidente de Trabalho: ANT_ACIDEN=1
80-Perinatal: ANT_TRASMI=1
90-Ignorado: Todas as condições acima não atendidas.
201