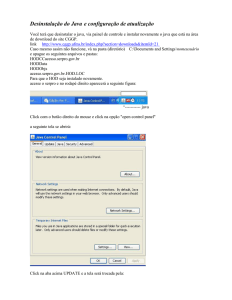
CC
ColCat
Uma ferramenta de pesquisa bibliográfica
ágil e eficaz
No diap. nº12 encontram-se informações detalhadas sobre este projecto da Univ. de Aveiro
bem como sobre o seu autor.
http://cc.doc.ua.pt/
Escolher por autor e marcar a(s) biblioteca(s)
Escolho aut., tit. , ass.
Escolher por autor e marcar a(s) biblioteca(s)
Click!
Resultados da pesquisa
Faço click nestes
Ver os 1ºs 10 registos encontrados na UA
Depois fui espreitar os resultados da UM
Procuro agora um título em Bibliotecas
estrangeiras
Click! 2º
1º
Escolho as Bibliotecas estrangeiras
1º marco as bibl.
2º
Click!
Resultados encontrados
Fui espreitar os 1ºs registos da BL
•
•
•
•
•
•
•
•
•
•
Sobre o CC (ColCat)...
O ColCat, os motores de pesquisa e a web profunda / web invisível
Motores de pesquisa web como o Google ou o Sapo tem a informação nas suas bases de dados limitada à web
superficial (visible web), que consiste no conjunto de páginas estáticas (exempo) ou páginas dinâmicas préparametrizadas referenciadas noutras páginas (exemplo, link na barra de navegação "Recursos electrónicos"
=> "bases de dados"); O conteúdo destas páginas é sempre o mesmo para uma determinada URL.
Os diferentes conteúdos que uma página dinâmica pode ter (exemplo , resultado de uma pesquisa), desde
algumas unidades a várias dezenas de milhões em grandes bases de dados, que variam de acordo com uma
pesquisa ou acção do utilizador, não são vis íveis para os "spiders" (robots dos motores de busca que
percorrem a web, saltando de link em link, indexando as páginas encontradas). É por isso que estes conteúdos
se dizem estar na web profunda (tradução livre de "deep web") ou web invisível (invisible web).
O ColCat também não indexa esses conteúdos; aliás, não recolhe nenhuma informação para uma base de
dados local, como os motores de busca que indexam páginas web fazem. Pelo contrário, faz tudo em tempo
real, simulando a interacção de um utilizador humano com os servidores remotos. Isto é feito de tal modo que
estes servidores não conseguem distinguir o ColCat de um utilizador normal. Isto permite ainda que, se um
registo é adicionado num desses servidores remotos, no segundo seguinte a mesma pesquisa no ColCat já
apresente esse registo, caso este corresponda a essa pesquisa.
O ColCat pesquisa na web profunda das bases de dados de informação bibliográfica (OPACs).
A sua apurada base de inteligência permite-lhe "ler" e "compreender" as respostas dos servidores remotos,
tendo sido "treinado" para saber analisar as diferentes respostas de cada um deles. É nesta inteligência, fruto
de algumas dezenas de horas de programação e parametrização, que está o seu real valor, permitindo ao
ColCat analisar os diferentes resultados dos vários catálogos remotos; diferentes quer no formato dos dados,
quer no modo de apresentação.
A concepção e desenvolvimento do ColCat tornou-se possível perante a mudança de paradigma, com as
bibliotecas a disponibilizarem publicamente a pesquisa nos seus catálogos (OPACs). Apesar de ter ficado
numa fase operacional desde fins de 2002, só recentemente com o aumento da velocidade da ligação à internet
das várias instituições, é que este atingiu um grau de resposta elevado, quer em termos de rapidez e de
eficácia.
Exemplo de pesquisa num motor de pesquisa web e no ColCat:
Google: "Carl Sagan biblioteca universidade lisboa" -> resultado: nenhuma referência a obras nas várias
Bibliotecas desta Universidade;
ColCat, Universidade de Lisboa, campo "autor": 40 obras - livros, vídeos (como autor e/ou apresentador).
Com o ColCat, além de obter a informação desejada, também é possível pesquisar de uma forma integrada
várias fontes ao mesmo tempo, apresentado em poucos segundos a relação dos resultados, normalizados e
mostrados numa única página à medida que vão sendo obtidos; de outra forma, demoraria muito mais tempo.
•
•
CC: o novo nome do projecto ColCat
Filipe Bento :: contacto